Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek V3 (0324) using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek V3 (0324)
DeepSeek V3 (0324) is a Mixture-of-Experts language model with 671 billion total parameters and 37 billion activated per token, developed by DeepSeek AI. The model incorporates Multi-head Latent Attention, FP8 mixed-precision training, and Multi-Token Prediction techniques. It demonstrates strong performance in reasoning, code generation, and multilingual tasks, particularly Chinese, with support for 128K token contexts and availability under permissive open-source licensing.
Explore the Future of AI
Your server, your data, under your control
DeepSeek V3 (0324) is a large-scale Mixture-of-Experts (MoE) language model developed by DeepSeek AI, designed for enhanced reasoning, code generation, and multilingual proficiency—especially in Chinese—while maintaining efficiency in both training and deployment. Building on the architecture of DeepSeek-V2, this iteration incorporates innovative techniques in attention mechanisms, load balancing, and precision computing, yielding strong benchmark results across multiple domains. The model's open-source codebase is available under the MIT License, with model weights released for commercial use under a separate license, as outlined by the DeepSeek-V3 GitHub repository.
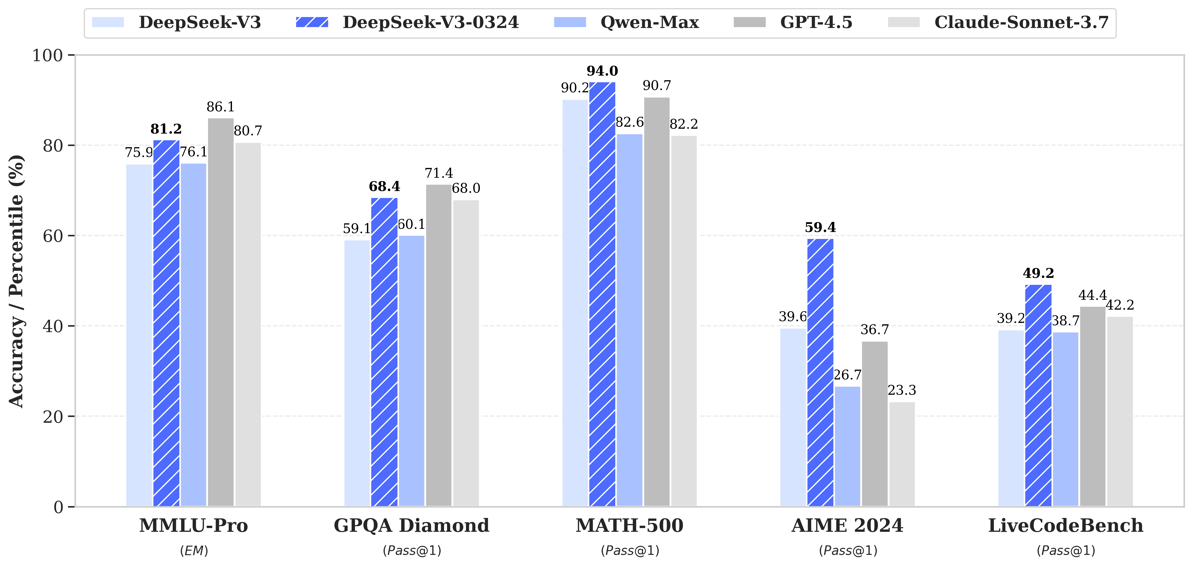
Benchmark comparison highlighting DeepSeek-V3-0324's improvements over its predecessor and contemporaries across reasoning, math, and coding tasks.
Central to DeepSeek-V3 (0324) is a Mixture-of-Experts (MoE) architecture, utilizing 671 billion total parameters, with 37 billion parameters dynamically activated per token for improved computational efficiency. This architecture leverages "finer-grained" expertise specialization, with a limited set of shared and routed experts, while employing a restricted routing strategy that distributes computation—each token is dispatched to at most four computational nodes, minimizing communication overhead.
The model's attention mechanism relies on Multi-head Latent Attention (MLA), a low-rank compression technique for keys, values, and queries. Only compressed latent vectors are cached during generative inference, significantly reducing memory requirements relative to traditional multi-head attention systems, as validated in DeepSeek-V2.
A further innovation is the auxiliary-loss-free load balancing, which directly adjusts experts' bias terms during training to ensure consistently distributed token allocation. This approach circumvents the need for extra auxiliary loss terms and yields distinctive patterns of expert specialization across the network.
For training objectives, DeepSeek-V3 (0324) implements Multi-Token Prediction (MTP), allowing the model to predict multiple future tokens at once, thus supplying denser training signals and facilitating improved speculative decoding at inference.
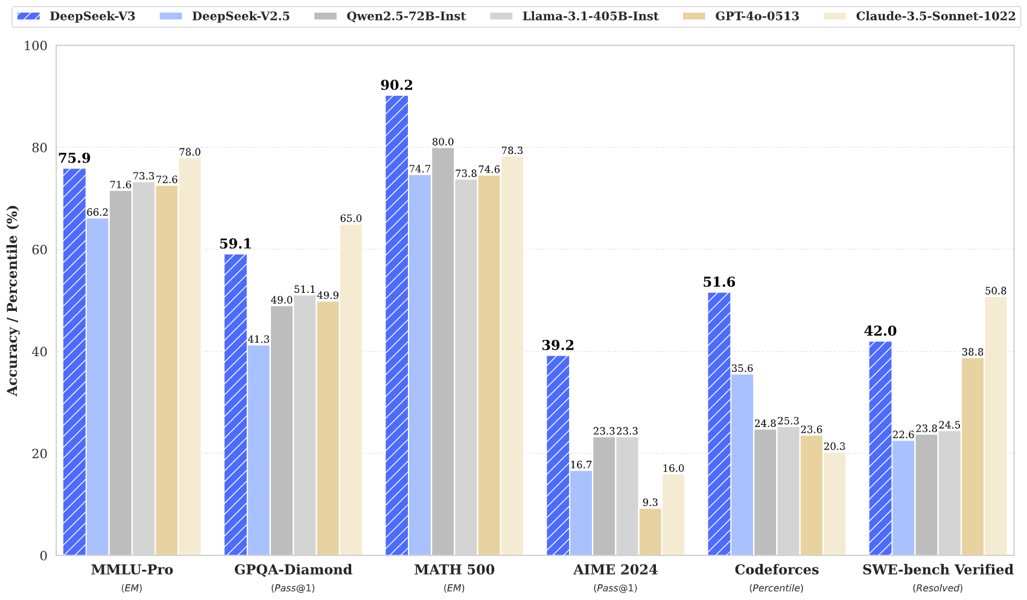
Comparative benchmark results demonstrate DeepSeek-V3's strong standing in reasoning, math, and programming tasks versus other large models.
Training of DeepSeek-V3 (0324) employs FP8 mixed-precision computation, marking one of the first demonstrations of the feasibility of extremely low-precision training at this scale. Precision is enhanced through tile-wise activation quantization, block-wise weight quantization, and periodic promotion to higher-precision accumulators to counteract numeric instability. Efficient utilization of computation-communication overlap, aided by custom cross-node communication kernels and the DualPipe pipeline parallelism algorithm, results in rapid and scalable training performance.
Performance and Benchmark Evaluation
DeepSeek-V3 (0324) exhibits competitive or superior results among both open-source and leading closed-source language models on a range of academic and practical benchmarks. Its improvements are evident in multi-turn reasoning, code generation, and performance on Chinese-language tasks.
On standardized benchmarks such as MMLU-Pro, GPQA, and LiveCodeBench, DeepSeek-V3 (0324) demonstrates measurable gains over its predecessor. The model's performance on HumanEval and other programming tasks shows substantial improvements, as does its function-calling accuracy and code generation consistency.
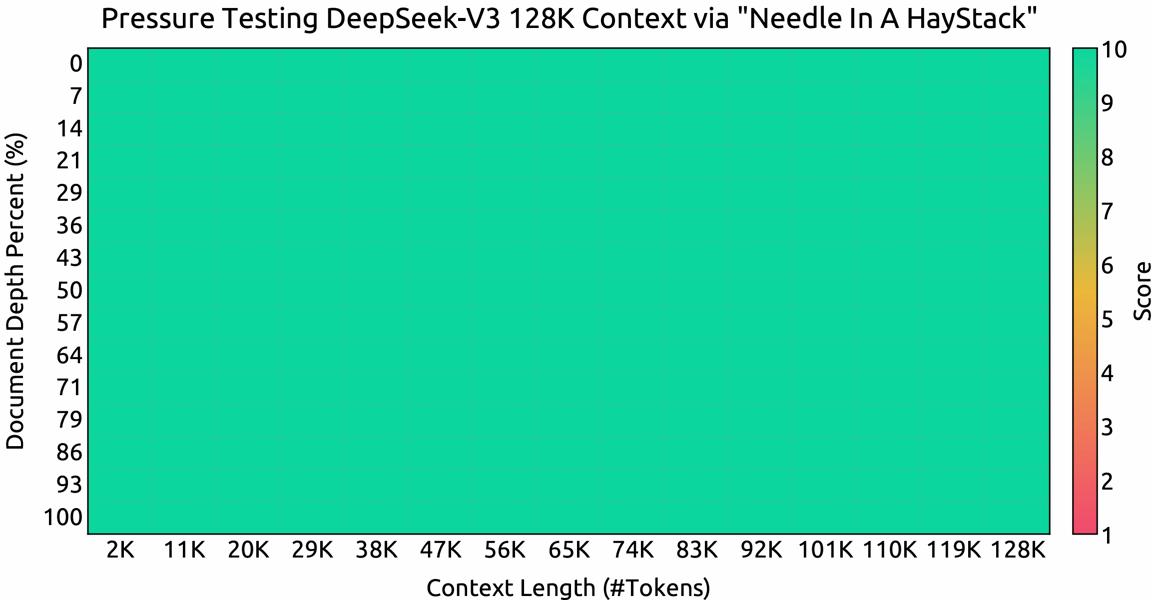
The model's long-context capabilities have also been rigorously tested, with effective context window handling up to 128,000 tokens, as evidenced by Needle In A Haystack (NIAH) results.
Heatmap from NIAH tests showing DeepSeek-V3's robust accuracy across context lengths up to 128K tokens.
These quantitative gains extend to mathematical tasks (such as MATH-500 and AIME 2024), Chinese writing proficiency, open-ended question answering, and open evaluation platforms like AlpacaEval 2.0 and Arena-Hard. DeepSeek-V3-0324's strong performance in Chinese-language search and report analysis underscores its multilingual enhancements.
Training Data, Procedures, and Fine-Tuning
The pre-training phase utilized a corpus of 14.8 trillion high-quality tokens, with a deliberate emphasis on mathematical reasoning, programming problems, and expanded multilingual material. A sophisticated byte-level BPE tokenizer with a 128K token vocabulary is employed, optimized for minimizing boundary bias and maximizing compression efficiency for various languages.
A fill-in-the-middle objective is incorporated, using the Prefix-Suffix-Middle (PSM) framework to round out training diversity, and an AdamW optimizer with staged batch size and learning rate schedules controls convergence. Context length is progressively increased during later training phases with the YaRN approach, allowing the model to handle substantially longer input sequences.
Post-training, DeepSeek-V3 (0324) undergoes supervised fine-tuning with a dataset of 1.5 million curated instances, enriched by internal model-generated reasoning content and human-verified non-reasoning data. Reinforcement Learning via Group Relative Policy Optimization further aligns the model, with policy improvements guided by both model-based and rule-based reward models. Knowledge distillation from specialized reasoning models in the DeepSeek R1 series enhances the chain-of-thought abilities while maintaining output structure and stylistic consistency.
Applications and Use Cases
DeepSeek-V3 (0324) serves as a general-purpose large language model suitable for a diverse range of tasks, including natural language understanding, advanced reasoning, programming, and mathematical problem solving. Its extended context window supports applications in document processing and long-form content generation, while its advanced code capabilities are particularly relevant for software engineering and automated code assistance. The model's improvements in Chinese language tasks extend its utility to regions and domains requiring strong multilingual or culturally adapted performance.
Additionally, the model's generative reward self-evaluation abilities facilitate improved alignment and policy shaping, which are valuable in chatbot construction, conversational agents, and autonomous reasoning applications.
Limitations
Despite its strengths, DeepSeek-V3 (0324) does have several stated limitations. Deployment is most tractable for organizations able to accommodate large parameter models, and while the end-to-end generation speed is higher than previous versions, there is still scope for further efficiency gains. In English factual question answering, the model lags slightly behind frontier closed systems, likely reflecting a deliberate training focus on Chinese and multilingual expertise. For engineering-specific coding tasks, the model performs below some leading closed alternatives on benchmarks such as SWE-Bench-Verified.
Timeline and Relationship to Other DeepSeek Models
The DeepSeek-V3-0324 snapshot denotes the March 24th version, which incorporates specific improvements in reasoning and Chinese processing relative to the original DeepSeek-V3 release—announced with a technical report in early 2025. DeepSeek-V3 (0324) builds on the architectural foundations and innovations introduced by DeepSeek-V2 and benefits from reasoning techniques initially explored in the DeepSeek R1 series.