Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 2.5 Math 1.5B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 2.5 Math 1.5B
Qwen 2.5 Math 1.5B is a specialized language model developed by Alibaba Cloud for mathematical reasoning in English and Chinese. Built on the Qwen2.5 architecture with 4,096 token context length, it was trained on the Qwen Math Corpus v2 containing over one trillion tokens. The model supports chain-of-thought reasoning and tool-integrated reasoning with Python code execution for solving complex mathematical problems.
Explore the Future of AI
Your server, your data, under your control
Qwen2.5-Math-1.5B is a specialized large language model designed for mathematical reasoning and problem-solving in both English and Chinese. Developed by the Qwen Team, Qwen2.5-Math-1.5B is part of the Qwen2.5-Math series, which was released in September 2024 as an enhancement to the earlier Qwen2-Math models. The series also includes larger models such as Qwen-2_5-math-7b and Qwen-2_5-math-72b, as well as instruction-tuned variants and a reward model for reinforcement learning. Qwen2.5-Math-1.5B is engineered with a focus on logic, symbolic manipulation, and bilingual mathematical processing, leveraging both chain-of-thought and tool-integrated reasoning paradigms.
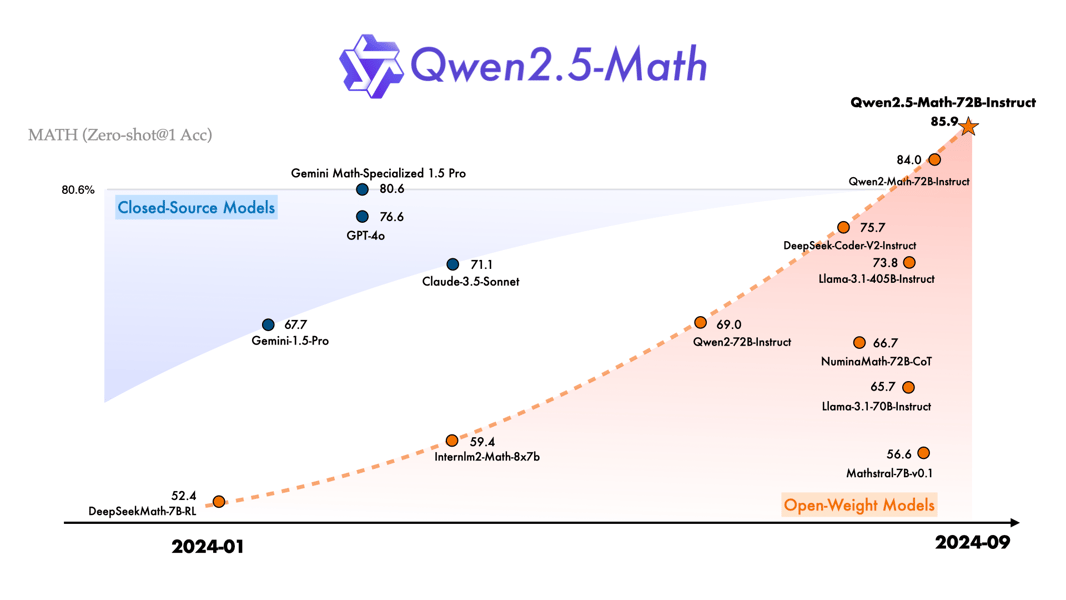
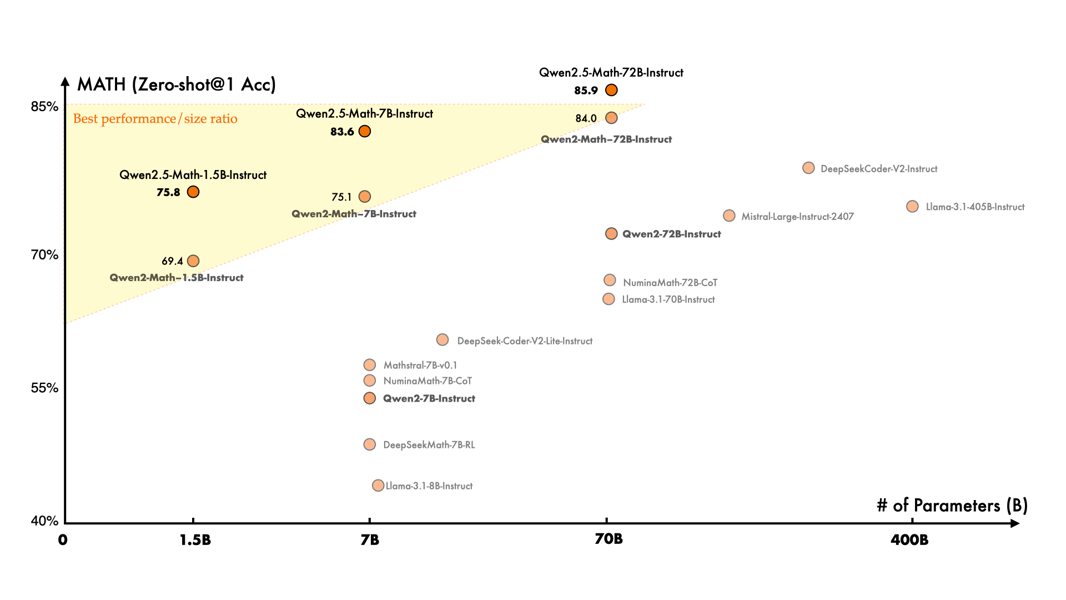
Qwen2.5-Math-72B-Instruct performance on Zero-shot@1 accuracy on mathematical benchmarks in September 2024. The chart shows progression among open-weight and closed-source mathematical models over the course of 2024.
Qwen2.5-Math-1.5B is built on the Qwen2.5 base architecture, benefiting from enhancements in language understanding, symbolic reasoning, and code generation over previous iterations. The parameter initialization for this model comes directly from the Qwen2.5 series, ensuring a robust foundation for mathematical tasks.
The development pipeline for Qwen2.5-Math incorporates several stages, including synthetic data generation using larger instruction-tuned models, aggregation of high-quality mathematical data (with a focus on expanding Chinese language resources), and specialized parameter tuning for mathematical domains. Model training maintains a context length of 4,096 tokens, offering sufficient capacity for complex, multi-step mathematical reasoning.
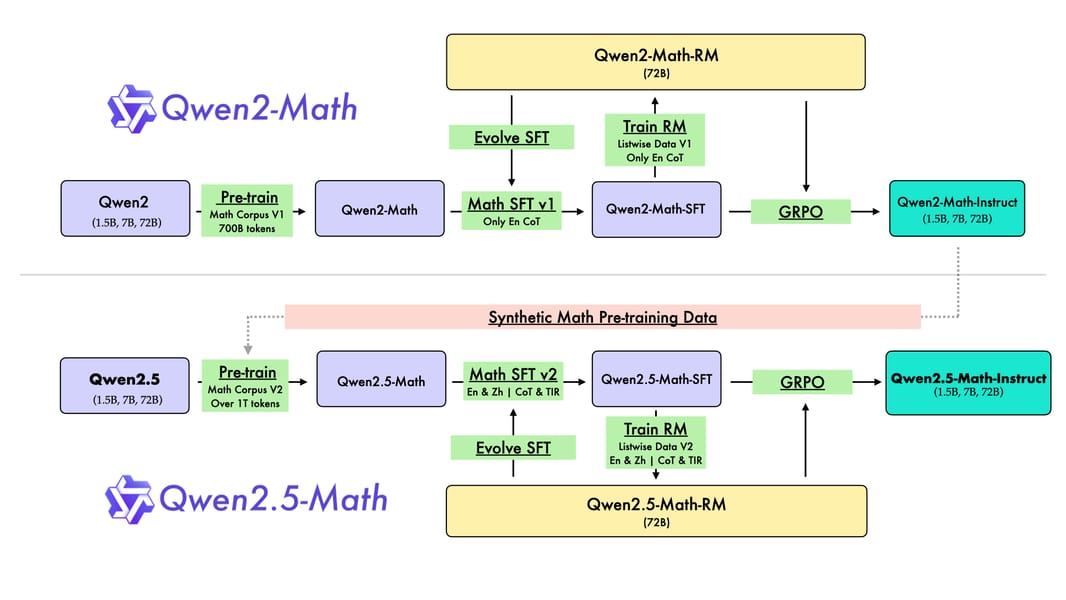
Flowchart depicting the specialization pipeline from Qwen2-Math to Qwen2.5-Math, illustrating stages such as data synthesis, supervised fine-tuning, reward model training, and policy optimization.
The pre-training of Qwen2.5-Math-1.5B utilizes the Qwen Math Corpus v2, comprising over one trillion tokens, which is a notable increase from the previous version's 700 billion. This corpus includes extensive mathematical content in both English and Chinese, collected from web data, educational resources, and curated code repositories. The training process further incorporates synthetic data generated by high-capacity Qwen2-Math models to enrich coverage and complexity.
A math-specific reward model, Qwen2.5-Math-RM-72B, is employed for constructing supervised fine-tuning data through rejection sampling and drives reinforcement learning post-SFT via Group Relative Policy Optimization. Task-specific instruction tuning introduces both chain-of-thought and tool-integrated reasoning data in English and Chinese.
Rigorous data decontamination protocols are enforced to prevent overlap between training and benchmark datasets. These include 13-gram text matching, normalization to remove extraneous symbols, and subsequence ratio thresholds. This ensures unbiased model evaluation, particularly on standardized mathematical datasets such as GSM8K, MATH, and various Chinese academic examinations.
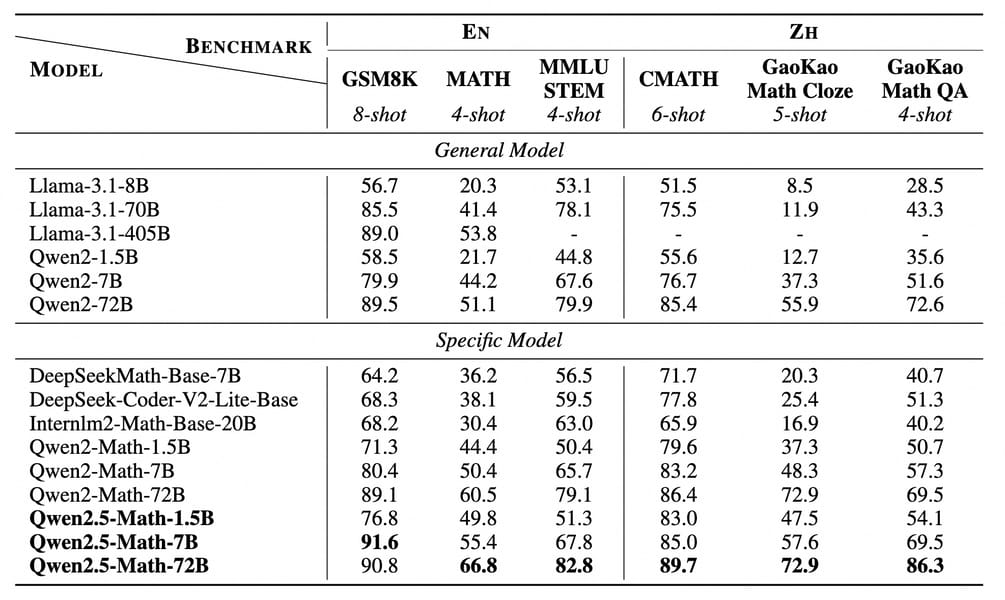
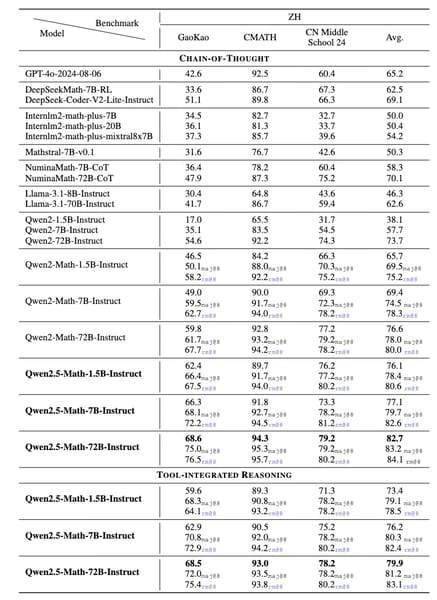
Evaluation metrics for Qwen2.5-Math and prior models, showing performance across both English and Chinese mathematical benchmarks at equivalent model scales.
Qwen2.5-Math-1.5B supports two principal reasoning modalities: Chain-of-Thought (CoT) and Tool-Integrated Reasoning (TIR). CoT enables stepwise natural language explanations, enhancing the interpretability and logical flow of mathematical solutions. Tool-Integrated Reasoning connects model outputs to a local or embedded Python interpreter, facilitating precise numerical computations and symbolic algebraic manipulation.
The TIR approach allows the model to solve complex mathematical questions by generating executable code. This yields accuracy on benchmark datasets and enables solutions to problems that are difficult to resolve solely through text-based reasoning.
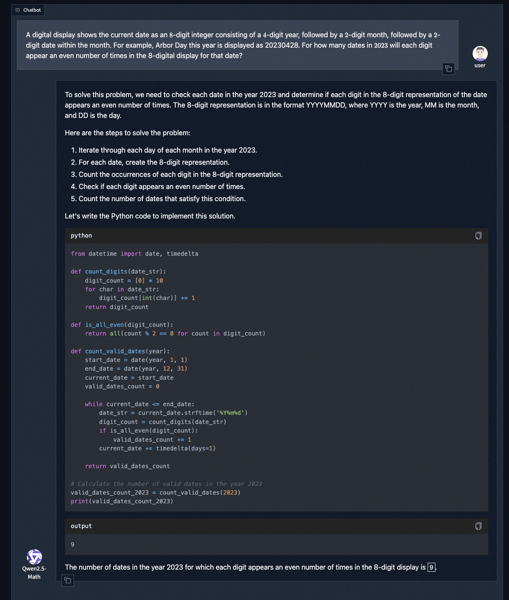
Chatbot demonstration of Qwen2.5-Math's Tool-Integrated Reasoning: the model generates a solution plan, outputs Python code, and executes it for the answer.
A demo implementation within Qwen-Agent showcases this process, accepting code-execution requests from users and enabling local solution verification. Additionally, multimodal demos built on Qwen2-VL expand capabilities to process images or handwritten sketches of problems.
Performance and Evaluation
Qwen2.5-Math-1.5B demonstrates results across standard mathematical evaluation benchmarks in both English and Chinese environments. On the MATH benchmark, it achieves approximately 80% accuracy when utilizing the Python interpreter with TIR, and shows consistent gains over the prior Qwen2-Math series.
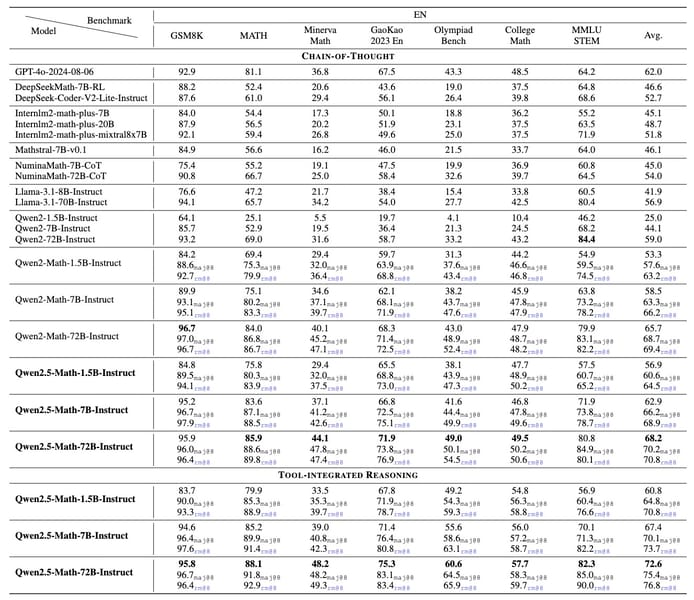
Performance of Qwen2.5-Math-Instruct and other models on English mathematical benchmarks under chain-of-thought and tool-integrated reasoning modalities.
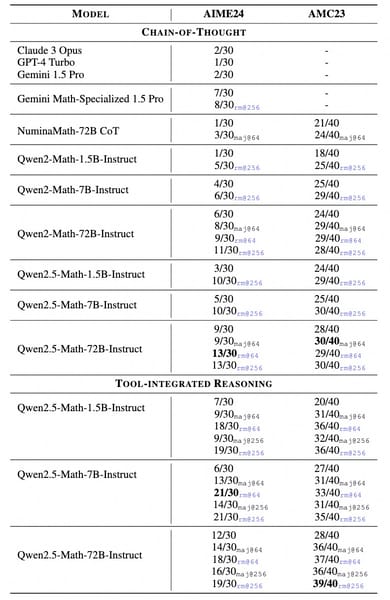
In rigorous competition settings such as AIME 2024 and AMC 2023, the model solves a substantial portion of challenging problems. For instance, in CoT mode with reward aggregation, Qwen2.5-Math-1.5B-Instruct answers 29 out of 40 AMC 2023 questions. Larger variants within the Qwen2.5-Math series further improve these metrics, with performance comparable to several other models on both English and Chinese tasks.
Performance of Qwen2.5-Math-Instruct and other models on AIME 2024 and AMC 2023 benchmarks; results are grouped by reasoning strategy.
Qwen2.5-Math-1.5B is specifically intended for mathematical reasoning tasks in English and Chinese. Its design is tailored for academic benchmarks, math education, and problem-solving involving symbolic computation and logical deduction. The model is not recommended for general-purpose language tasks outside mathematics, as highlighted in project documentation.
Both the base and instruction-tuned versions are provided: the base model is optimized for few-shot inference and fine-tuning, while the instruction-tuned model is suitable for interactive chat-like use. The recommended inference settings utilize the latest versions of popular transformer libraries for compatibility.