Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 1.5 32B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 1.5 32B
Qwen1.5-32B is a 32-billion parameter generative language model developed by Alibaba Cloud's Qwen Team and released in February 2024. The model supports up to 32,768 tokens of context length and demonstrates multilingual capabilities across European, East Asian, and Southeast Asian languages. It achieves competitive performance on language understanding and reasoning benchmarks, with an MMLU score of 73.4, and includes features for retrieval-augmented generation and external system integration.
Explore the Future of AI
Your server, your data, under your control
Qwen1.5-32B is a large-scale generative language model in the Qwen1.5 series, developed by the Qwen Team and released in February 2024. This model, part of the Qwen lineup, incorporates designs for enhanced alignment, multilingual capabilities, long-context processing, and aims for improved performance across a range of natural language processing tasks.
Timeline graphic highlighting releases in the Qwen series, with a focus on the launch of Qwen1.5.
The Qwen1.5-32B model is built as part of a modular series covering a spectrum of model sizes, from 0.5B to 110B parameters, alongside a mixture-of-experts (MoE) variant. All models in this series are unified by support for an extended context window of up to 32,768 tokens, which enhances their ability to process and retain information over lengthy documents or complex, multi-turn conversations. The architecture is accessible via the Hugging Face Transformers library (version 4.37.0 and above), allowing integration without modification or reliance on custom execution environments, as described in the official Qwen1.5 release documentation.
Alignment to human preferences is achieved using reinforcement learning techniques such as Direct Policy Optimization (DPO) and Proximal Policy Optimization (PPO), which are incorporated during the fine-tuning stages of development. These methods refine the model's tendency to follow human instructions and produce responses that are helpful, accurate, and contextually appropriate, as detailed in the Qwen team's technical blog post. While the specific pretraining datasets employed remain undisclosed, the focus on diverse data and multilingual resources is stated as a priority for broad generalization.
The Qwen1.5-32B model is published in multiple quantized formats, including Int4/Int8 GPTQ, AWQ, and GGUF, enabling efficient inference and adaptation to a range of deployment scenarios.
Performance and Benchmark Evaluation
Qwen1.5-32B demonstrates competitive results across numerous language understanding, reasoning, and coding benchmarks. The base model’s performance includes an MMLU score of 73.4, with scores indicating knowledge and reasoning competencies; a C-Eval score of 83.5; GSM8K at 77.4 for mathematical reasoning; MATH at 36.1; HumanEval at 37.2 for programming tasks; MBPP at 49.4; BBH at 66.8; and CMMLU at 82.3. These results, published in the Qwen1.5 performance overview, indicate its performance relative to peer language models of similar scale.
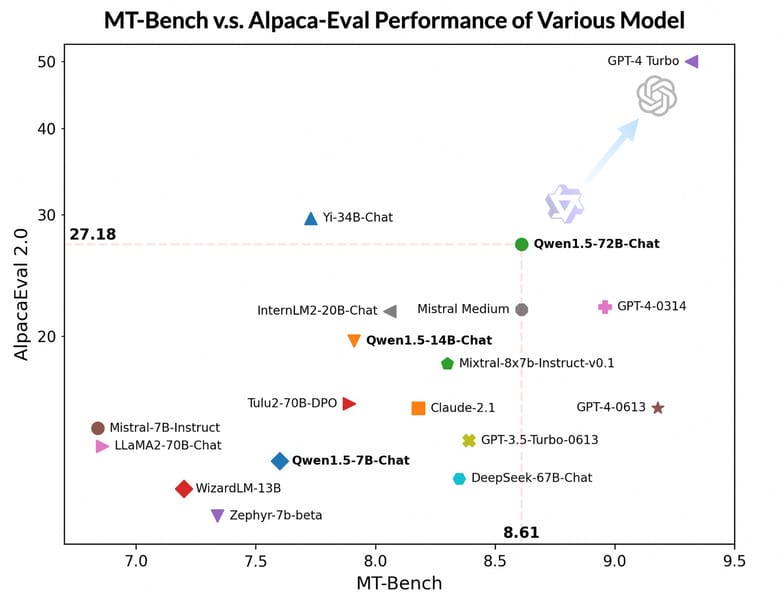
Although the Qwen1.5-32B model's multilingual and tool-use specific results are less extensively documented than those of larger siblings such as Qwen-1_5-72B, the series as a whole exhibits capabilities in language understanding, translation, and code-related tasks. The model family has been evaluated using benchmarks such as MT-Bench and AlpacaEval v2 for instruction following, L-Eval for long context handling, RGB for retrieval-augmented generation, and additional assessments for code interpretation and tool use.
Scatter plot comparing alignment with human preferences across Qwen1.5 and other prominent language models on MT-Bench and AlpacaEval 2.0.
Qwen1.5-32B includes support for multiple languages spanning Europe, East Asia, and Southeast Asia, with demonstrable performance across exams, translation, comprehension, and mathematical reasoning tasks. The design emphasizes uniform multilingual evaluation and large context capacity, allowing applications in translation, cross-lingual information retrieval, and multilingual dialogue.
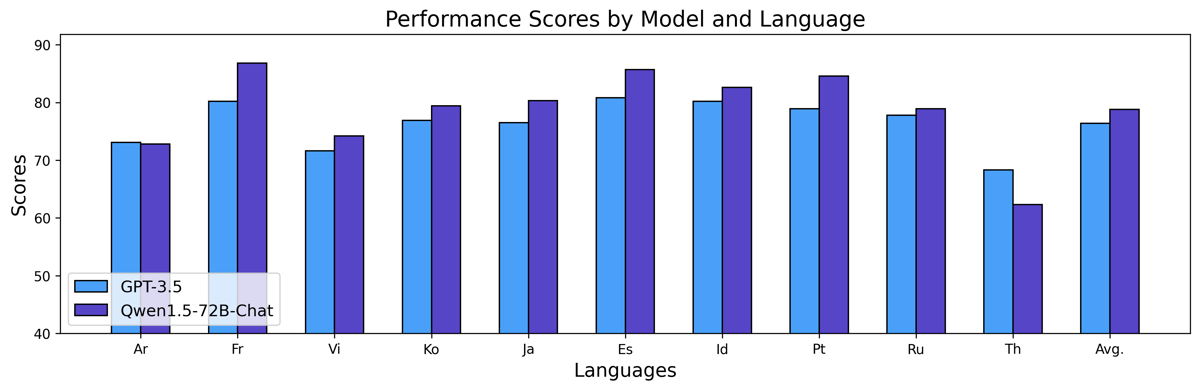
Illustrative results in the broader Qwen1.5 family indicate score parity or, in some cases, an advantage compared to other leading models in multilingual benchmarks, as highlighted in bar charts comparing Qwen-1_5-72B-Chat with models like GPT-3.5 across languages such as Arabic, French, Vietnamese, Korean, Japanese, and others in a performance comparison.
Bar chart comparing multilingual evaluation scores between Qwen1.5-72B-Chat and GPT-3.5 across various languages.
The consistent support for context lengths up to 32,768 tokens increases usability in scenarios requiring rich document understanding and handling of complex multi-step instructions without premature truncation or loss of coherence.
Integration, Alignment, and System Connectivity
Beyond core language modeling, Qwen1.5-32B is developed with capabilities for integration with external systems. Features include support for retrieval-augmented generation (RAG), enabling the use of up-to-date or private knowledge via connected external databases or APIs. The model series is also designed for API-based interaction, function/tool calling, and interaction with agent-oriented frameworks.
Alignment with human intent and safety guidelines is addressed via the aforementioned DPO and PPO training regimes. These steps contribute to instruction-following reliability and human-aligned outputs, validated through comprehensive crowd-sourcing and evaluation results in alignment-oriented benchmarks, as described in the Qwen1.5 technical overview.
Comparative Position and Limitations
Within the Qwen1.5 series, the 32B model occupies a middle-size tier, offering a balance between scale and resource efficiency. Larger siblings, such as Qwen-1_5-72B, are reported to outperform models like Llama-2-70B across diverse metrics and demonstrate high scores in alignment and multilingual evaluations. However, on code interpretation and visual reasoning tasks, the series is noted to trail behind frontier models such as GPT-4, particularly in tool-use and math-centric reasoning.
While the models achieve parity in many multi-turn, chat, and reasoning benchmarks, ongoing work is planned by the Qwen Team to bolster code reasoning and interpreter accuracy, as noted in the model’s official blog announcement.
Applications and Use Cases
Qwen1.5-32B finds application across a wide range of domains, including language comprehension and generation, coding assistance, complex reasoning, multilingual dialogue, retrieval-augmented workflows, and integration with agent frameworks capable of tool invocation. Fine-tuning support and configurability allow adaptation to specialized domains and research. Local inference in quantized formats and integration with open-source tools further extend practical accessibility.