Launch a dedicated cloud GPU server running Laboratory OS to download and run Mixtral 8x22B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Mistral AI / Mixtral 8x22B
Mixtral 8x22B is a Sparse Mixture of Experts language model developed by Mistral AI with 141 billion total parameters and 39 billion active parameters per token. The model supports multilingual text generation across English, French, German, Spanish, and Italian, with a 64,000-token context window. It demonstrates capabilities in reasoning, mathematics, and coding tasks, released under Apache 2.0 license.
Explore the Future of AI
Your server, your data, under your control
Mixtral 8x22B, developed by Mistral AI, is a large-scale open-weight language model built upon a Sparse Mixture of Experts (SMoE) architecture. Released under the Apache 2.0 license, the model is designed for a wide range of applications, enabling both academic research and commercial use. Mixtral 8x22B is characterized by efficient inference, multilingual capabilities, performance in mathematics and coding, and support for long-context tasks within the Mixtral and broader large language model (LLM) ecosystem.
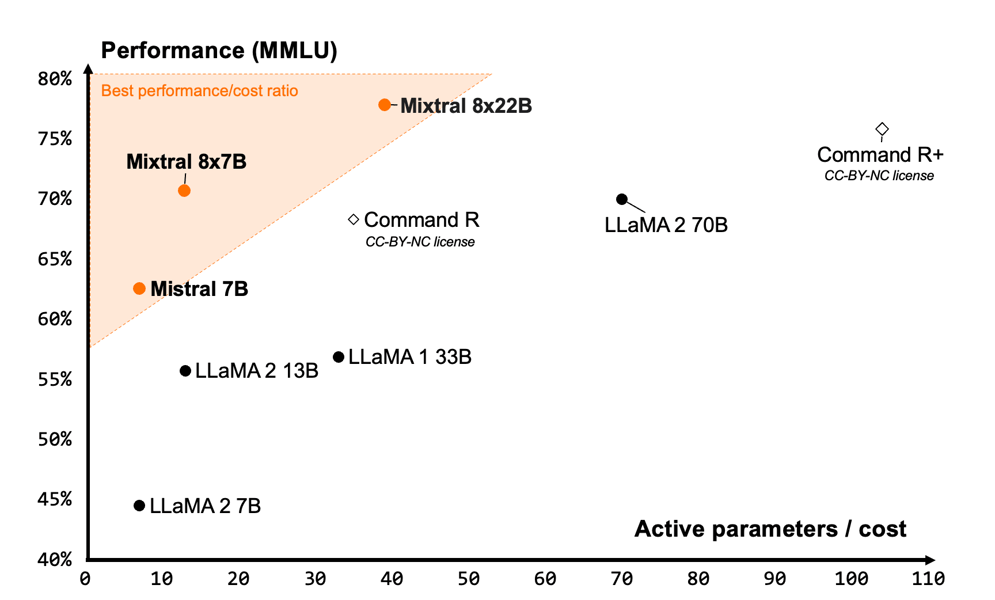
Performance versus inference budget among open models, illustrating how Mixtral 8x22B can achieve a performance-to-cost utilization.
Mixtral 8x22B leverages the Sparse Mixture of Experts (SMoE) architecture, a design distinguished by the presence of multiple independent "experts" within each transformer layer. For each token processed, a router network dynamically selects a subset of these expert feedforward blocks, combining their outputs to compose the final representation. In Mixtral 8x22B, the model contains a total of 141 billion parameters but activates only 39 billion parameters during inference for a given token, optimizing computational efficiency while maintaining a large effective model size.
This sparsity-focused structure can enhance both inference speed and throughput, especially at scale. The architecture includes an extended context window, supporting sequences up to 64,000 tokens, enabling the model to process and recall information from lengthy documents and conversations with high fidelity.
Multilingual and Domain-Specific Capabilities
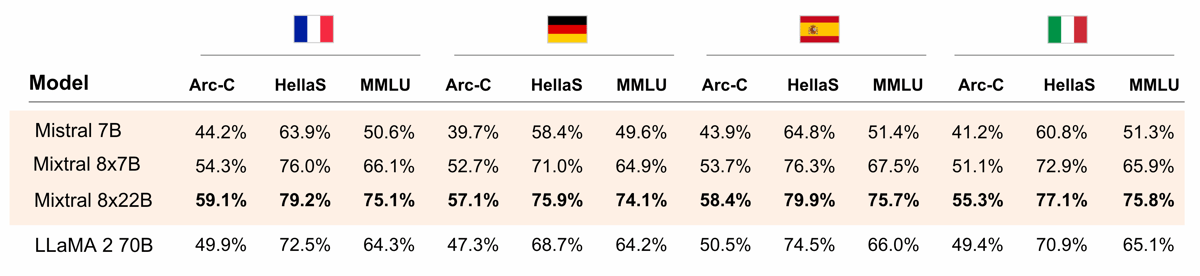
Mixtral 8x22B demonstrates multilingual competence. The model natively handles English, French, German, Spanish, and Italian, as evidenced by evaluations on established benchmarks such as HellaSwag, Arc Challenge, and MMLU in multiple languages here. Alongside its language skills, Mixtral 8x22B exhibits reasoning and knowledge proficiency, achieving accuracy in tasks requiring general understanding, common sense, and complex reasoning.
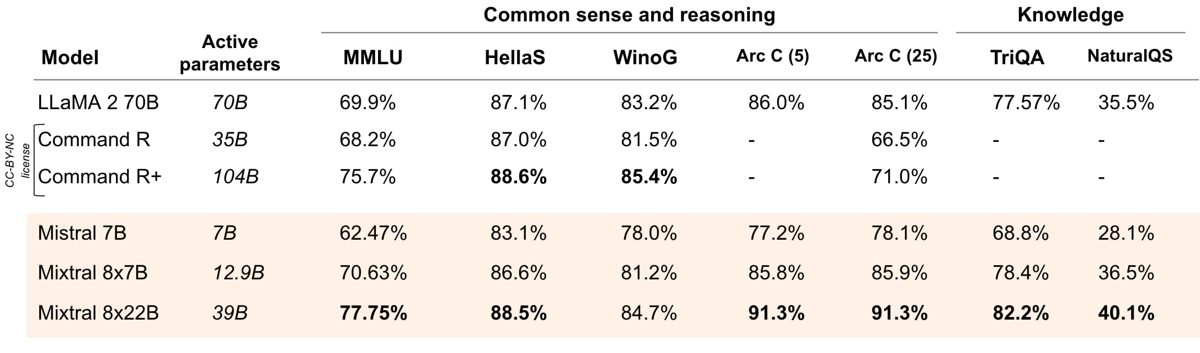
Mixtral 8x22B comparative results on common sense, reasoning, and knowledge benchmarks, indicating consistent performance relative to other open models.
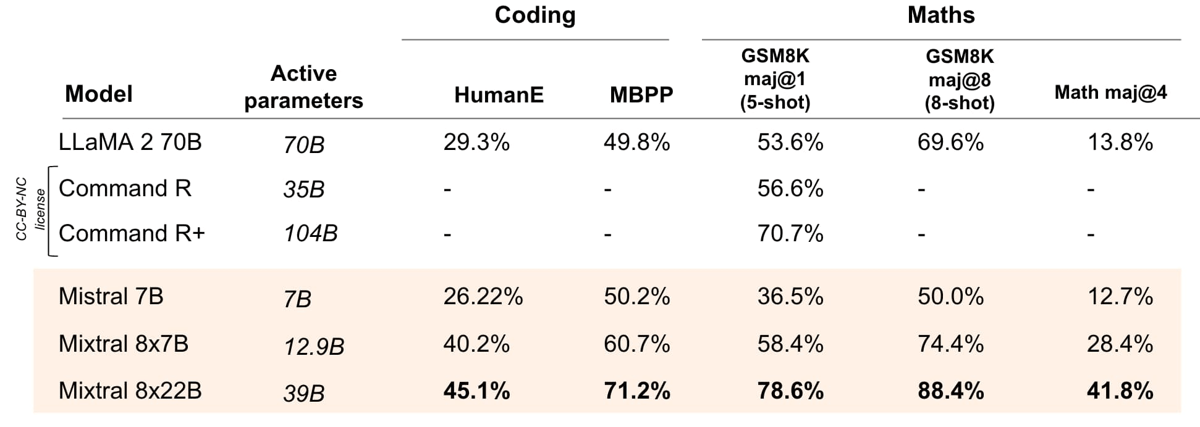
In addition to language understanding, the model is designed for tasks in mathematics and software development. Its architecture and training enable Mixtral 8x22B to perform well at coding tasks (as evaluated on benchmarks such as HumanEval and MBPP) and mathematical reasoning (as seen on GSM8K and Math benchmarks), consistently yielding results competitive with other openly available models.
Mixtral 8x22B's coding and mathematics benchmark results compared to other open models.
Mixtral 8x22B is the product of large-scale pretraining on diverse, multilingual datasets. The model integrates modifications to the standard transformer design, notably by replacing classical feedforward blocks with sparse Mixture-of-Experts layers that implement dynamic expert routing through gating networks. Each token is typically routed to a pair of experts per layer, optimizing parameter use and computational demands. Native support for function calling and constrained output modes enables precise task structuring, assisting in both software engineering and broader workflow automation tasks.
The technical implementation ensures compatibility with major deep learning frameworks, supporting integration into common model serving and deployment environments, such as the Hugging Face Transformers library. This includes compatibility with popular libraries for inference, and optimizations utilizing vLLM and Megablocks kernels for efficiency.
Performance and Benchmarking
Comprehensive benchmarking demonstrates Mixtral 8x22B's performance in language understanding, reasoning, multilingual ability, coding, and mathematics. On general reasoning and knowledge tests (such as MMLU, HellaSwag, WinoGrande, ARC Challenge, TriviaQA, and NaturalQuestions), Mixtral 8x22B achieves performance metrics that are competitive with other open models in its parameter class, according to available benchmark data. For mathematics and code, the Mixtral 8x22B base and instruct variants achieved notable scores in HumanEval, MBPP, and GSM8K, with instruction-tuning further boosting accuracy rates.
The utilization of sparse activation patterns allows Mixtral 8x22B to achieve efficient inference speeds and a lower active parameter footprint compared to dense models of comparable total size. As shown in published results, the model sustains throughput for both batch and long-context workloads.
Applications and Limitations
Designed as a foundational model, Mixtral 8x22B supports application across research, industry, and development contexts. Native function calling enables integrations, such as tool use and external action execution, while the large context window supports document-based workflows, question answering, summarization, and structured prompt engineering.
As a base model, Mixtral 8x22B does not include moderation or safety layers by default. It should be fine-tuned or wrapped accordingly for sensitive or public-facing deployments. The sparse expert architecture, while enabling efficiency, introduces complexity with respect to expert routing and parallelism; operationally, effective load balancing and batching are recommended for optimal performance, especially in distributed settings.
Family and Licensing
Mixtral 8x22B is part of the broader Mixtral model family, which also includes Mixtral 8x7B as well as the earlier Mistral 7B model. The entire series employs Mixture-of-Experts techniques to optimize the performance-to-computation ratio within the open-weight model landscape. The Apache 2.0 licensing ensures these models are open and accessible for both research and commercial innovation.