Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Diffusion XL using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
stabilityai / Stable Diffusion XL
Stable Diffusion XL is a text-to-image diffusion model developed by Stability AI featuring a two-stage architecture with a 3.5 billion parameter base model and a 6.6 billion parameter refiner. The model utilizes dual text encoders and generates images at 1024x1024 resolution with improved prompt adherence and compositional control compared to previous Stable Diffusion versions, while supporting fine-tuning and multi-aspect ratio training.
Explore the Future of AI
Your server, your data, under your control
Stable Diffusion XL (SDXL) is an open-access text-to-image generative model developed by Stability AI, first released on July 26, 2023. As the successor to previous Stable Diffusion models, SDXL leverages advancements in multimodal transformer architecture and latent diffusion, setting a new foundation for high-fidelity, versatile, and more controllable image generation. Key developments in SDXL include improved prompt interpretation, nuanced control mechanisms, and architectural changes that extend the model's utility across photorealistic and artistic domains.
Announcement graphic for SDXL, symbolizing the model's scope and ambition in generative AI.
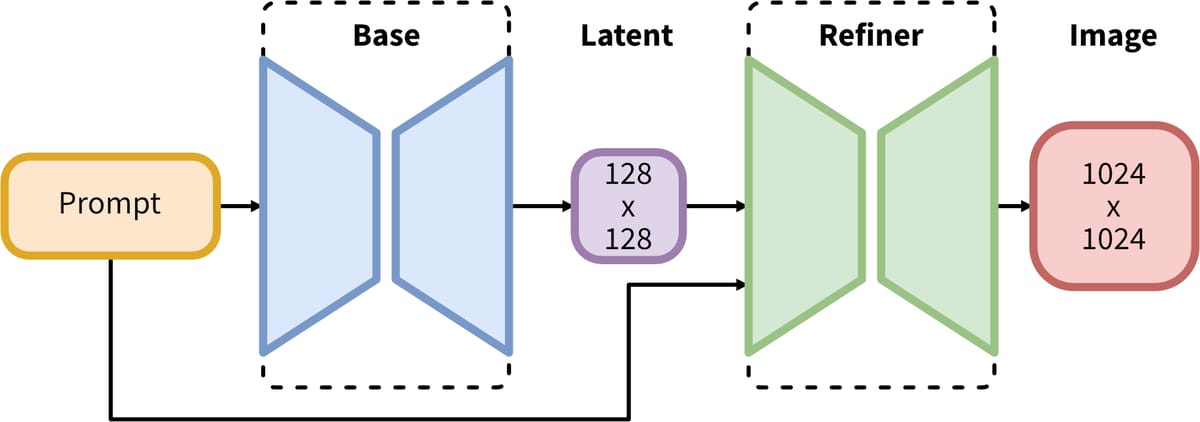
SDXL is built upon a robust two-stage latent diffusion framework, which divides the generative process into a “base” stage and a refinement stage. The base model has 3.5 billion parameters and generates initial latent image representations. These latent outputs are then passed to a refiner model, comprising 6.6 billion parameters in the full ensemble pipeline, to further denoise and sharpen the image for greater detail and realism. Notably, the base model can also function independently, reducing compute requirements when the highest fidelity is not essential.
Diagram of the SDXL two-stage latent diffusion pipeline: a base model generates latents, which are then refined for final high-resolution output.
This two-stage “mixture-of-experts” architecture draws on latent diffusion techniques to balance computational efficiency with output quality. The model adopts a UNet backbone, which is approximately three times larger than in Stable Diffusion 1.x, due to more transformer attention blocks and greater cross-attention context. Conditioning mechanisms are introduced on image size and crop coordinates using Fourier feature encodings, allowing SDXL to learn and generate images across diverse aspect ratios without discarding valuable training data.
To capture textual nuance, SDXL integrates two fixed, pre-trained text encoders: OpenCLIP-ViT/G and CLIP-ViT/L, leveraging a context dimension of 2048 and pooled text embeddings. This dual-encoder approach enhances the model’s comprehension and disambiguation of complex or subtle prompt terms.
Training and Datasets
The SDXL base model undergoes a multi-stage training process, beginning with pretraining at a resolution of 256x256 pixels for 600,000 optimization steps on a large, internal dataset, followed by continued training at 512x512 pixels. In the final refinement phase, the model is fine-tuned on a multi-aspect dataset, partitioned into resolution “buckets” to closely match a 1024x1024 pixel area while observing varied aspect ratios.
A discrete-time diffusion schedule with 1,000 steps is employed during training. The refiner is trained in the same latent space, specializing in generating visually detailed, high-resolution outputs through a noising-denoising process targeting the first 200 noise scales, as described in the SDEdit method.
The autoencoder, retrained from scratch for SDXL, uses a larger batch size and exponential moving average parameter tracking. This results in improved reconstructions, as measured by metrics such as PSNR, SSIM, LPIPS, and relative FID rFID.
Example of SDXL fine-tuned product generation: high-fidelity output for a specific object class.
SDXL demonstrates significant increases in image fidelity, prompt sensitivity, and compositional control compared to earlier Stable Diffusion models. The ensemble pipeline demonstrates effectiveness for photorealistic rendering, lighting, shadow detail, and style diversity.
User preference studies indicate that SDXL outputs are strongly favored over those from preceding models, such as Stable Diffusion 1.5 and Stable Diffusion 2. In controlled evaluations, the SDXL base and refiner ensemble achieved the highest preference win rate among surveyed models, as shown in published research.
User preference bar chart showing higher win rates for SDXL over previous models.
While traditional quantitative metrics such as Fréchet Inception Distance (FID) and CLIP score offer benchmarks, studies reveal these may not match human perceptions of image complexity, compositionality, and text interpretation for foundational text-to-image models. For example, SDXL’s improvements in realism and prompt adherence may not be fully captured by FID or CLIP alone as noted in published research.
The model is distinguished by several technical enhancements:
It requires less verbose or prescriptive prompts for detailed outputs, distinguishing between nuanced terms and concepts.
It handles complex spatial arrangements and difficult tasks such as generating hands, legible text, or intricate foreground-background compositions with greater reliability than predecessors.
Multi-aspect training provides consistent performance across varied image resolutions and aspect ratios, with explicit conditioning on both image size and cropping parameters.
Fine-Tuning, Control, and Use Cases
SDXL is explicitly designed to streamline fine-tuning for custom data and user-specific image styles, reducing the complexity of producing new LoRAs or custom checkpoints. Stability AI has integrated next-generation control tools, such as T2I adaptation and ControlNet extensions, providing more precise manipulation over content and style in outputs.
Applications span artistic creation, concept art, educational illustration, research on generative models, and safe deployment investigations. The model's open-access license under CreativeML OpenRAIL++-M supports broad experimentation and use.
Limitations
Despite improvements, SDXL demonstrates some limitations. The model may encounter difficulties with generating perfectly photorealistic faces, consistent hands, or long segments of legible text. Intricate compositionality—such as complex object arrangements or nuanced interactions—remains challenging and subject to further enhancements. "Concept bleeding," where distinct features may unintentionally overlap, can also occur, often influenced by encoder compression and contrastive training losses.
Additionally, SDXL follows the two-stage approach for optimal outputs, which can require loading two large model checkpoints, presenting accessibility and resource constraints. Like other large-scale image generators, SDXL may inadvertently reinforce or reflect biases present in its training datasets and does not guarantee robust safeguards against all forms of misuse.
Comparison with Previous Stable Diffusion Models
SDXL marks a departure from the earlier Stable Diffusion 1.5 and Stable Diffusion 2 lines by utilizing a much larger UNet backbone, dual text encoders, and a two-stage generation pipeline. Its outputs are consistently preferred in user studies, including in scenarios testing prompt adherence and compositional capabilities.
Additional models in the family, such as the dedicated SDXL refiner, are specialized for enhancing fidelity in difficult areas—particularly backgrounds and facial details—demonstrating the modularity and flexibility of the SDXL ecosystem.
Release, Licensing, and Resources
SDXL 1.0 was officially launched as an open model on July 26, 2023, with the scientific preprint made available on arXiv earlier that month. The model, its codebase, and refined weights are provided under the CreativeML OpenRAIL++-M License, emphasizing responsible and transparent deployment.
Developers and researchers can access the SDXL model, code, and documentation through GitHub and Hugging Face. Optimized support is available for frameworks such as Hugging Face Diffusers, Optimum, OpenVINO, and ONNX Runtime.