Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Diffusion 1.5 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
stabilityai / Stable Diffusion 1.5
Stable Diffusion 1.5 is a latent text-to-image diffusion model that generates 512x512 images from text prompts using a U-Net architecture conditioned on CLIP text embeddings within a compressed latent space. Trained on LAION dataset subsets, the model supports text-to-image generation, image-to-image translation, and inpainting tasks, released under the CreativeML OpenRAIL-M license for research and commercial applications.
Explore the Future of AI
Your server, your data, under your control
Stable Diffusion 1.5 is a latent text-to-image generative diffusion model developed for synthesizing high-quality images from text descriptions. Released in October 2022 by RunwayML, the model builds upon previous advancements in latent diffusion, offering a balance of photorealistic generation capabilities and computational efficiency. Its open access and adaptable framework have supported a broad range of creative and scientific applications, including image modification, inpainting, and research into generative modeling techniques.
Image generated by Stable Diffusion 1.5 from the prompt: 'a photograph of an astronaut riding a horse'.
Stable Diffusion 1.5 is constructed upon the latent diffusion model (LDM) architecture, initially developed by the CompVis research group at the Ludwig Maximilian University of Munich. LDMs introduce an efficient solution to diffusion-based generative modeling by applying the diffusion process within a compressed latent space rather than directly on pixel data, reducing memory and computational overhead significantly.
Diagram of the Stable Diffusion inference pipeline, illustrating the transformation from a text prompt and latent seed to the final generated image.
The model is primarily composed of three interconnected modules. Firstly, a Variational Autoencoder (VAE) encodes input images into a lower-dimensional latent representation, preserving essential semantic content. During inference, the VAE decoder reconstructs the generated latent samples back to image space. The core of generation relies on a U-Net neural network, which performs iterative denoising guided by cross-attention mechanisms that condition the process on external information—most notably, text embeddings. These embeddings are provided by a frozen, pre-trained CLIP ViT-L/14 text encoder, which translates the input prompt into a compatible vector space.
Stable Diffusion 1.5 employs classifier-free guidance to balance adherence to the prompt and image realism, controlled by a guidance_scale parameter. Negative prompts, which specify undesirable features to avoid during sampling, further refine output control. These and other features enable both creative flexibility and precision.
Training Data and Process
Training of Stable Diffusion 1.5 leveraged a subset of the large-scale LAION-5B dataset, consisting of more than five billion image-text pairs collected from publicly available web data. The LAION datasets are curated based on criteria such as semantic content, image resolution, aesthetic scores, and language coverage to maximize image quality and diversity within the training corpus. For the v1.5 release, training was initialized from earlier Stable Diffusion 1.2 weights, then fine-tuned for 595,000 steps at 512x512 resolution on the LAION-Aesthetics v2 5+ subset, with intentional dropout of text conditioning to enhance classifier-free guidance performance.
The training regimen employed 256 Nvidia A100 GPUs, accumulating approximately 150,000 GPU-hours for completion, as detailed in the model documentation and official announcements.
Functional Capabilities
Stable Diffusion 1.5 supports diverse generative tasks. The primary function is text-to-image synthesis, where users provide a prompt to generate an entirely new image. Parameters such as the number of inference steps, guiding scale, random seed, and output size are configurable, giving users control over output variability and quality.
Three distinct Stable Diffusion outputs for the same prompt, demonstrating the diversity of generated samples.
Beyond text-to-image generation, the model can perform image-to-image translation ("img2img"), inpainting—wherein specified regions are selectively regenerated based on masks and prompts—and outpainting, which involves extrapolating new content beyond the original image boundaries. Such features enable a range of applications in creative design, scientific visualization, and data augmentation.
Image generated with 15 inference steps, highlighting artifacts and quality differences compared to higher-step outputs.
A digital watermark is embedded in each generated image for traceability. The ability to use negative prompts and tuned classifier-free guidance values helps maintain desired content boundaries and increase overall fidelity.
Photo-realistic output from the diffusion pipeline, generated using the K-LMS scheduler with 100 inference steps.
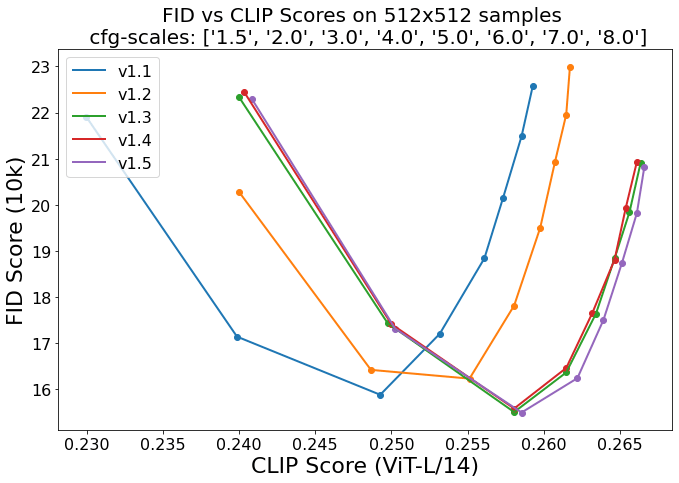
Performance metrics for Stable Diffusion models are typically reported using Fréchet Inception Distance (FID) for image realism and CLIP score for semantic alignment.
Line chart displaying FID vs CLIP scores for Stable Diffusion versions 1.1 to 1.5 on 512x512 samples.
The range of applications is broad: besides creating detailed visuals from natural language, Stable Diffusion 1.5 has been adapted for inpainting, outpainting, and masked editing. Researchers have also fine-tuned the model for specialized domains, such as medical imaging, musical spectrogram generation (e.g., Riffusion), and diverse artistic styles. Its flexible architecture allows use as a base model for downstream tasks, leveraging fine-tuning and control modules, such as ControlNet, to incorporate additional conditional information.
Limitations
Despite its broad utility, Stable Diffusion 1.5 exhibits several limitations. The model is trained at a fixed 512x512 resolution, which may result in artifacts or quality degradation when generating images at other aspect ratios or scales. It can struggle with rendering complex compositional scenes and accurately depicting fine details, especially in cases involving intricate or less-represented content from its training set. Generating precise, legible text within images remains challenging, and the model is unsuited for tasks requiring factual precision or high-stakes decision-making.
Stable Diffusion 1.5 inherits biases present in its training data, which predominantly features English-language content and may reflect Western-centric stereotypes. The autoencoding process is lossy, introducing minor inconsistencies in pixel-accurate reconstructions. Additionally, the sequential nature of diffusion sampling results in slower inference times relative to generative adversarial networks (GANs). Studies of the underlying dataset have highlighted the presence of duplicated and potentially sensitive material, raising considerations for responsible deployment and further research.
Licensing and Model Availability
Prior to version 3, Stable Diffusion models, including 1.5, are distributed under the CreativeML OpenRAIL-M license, which is a type of Responsible AI License (RAIL). The license prohibits certain use cases—such as those involving crime, harassment, or discrimination—but grants users rights to commercial usage of generated outputs, provided the content remains legal and non-harmful. The open-source release fosters transparency and auditability, supporting both research and creative experimentation within defined ethical boundaries, as described in the licensing documentation.
Comparisons with Subsequent Models
The Stable Diffusion model family has evolved rapidly since its initial releases. Notably, Stable Diffusion 2.0 introduced native 768x768 image generation and a dedicated depth-guided model. Stable Diffusion XL (SDXL) 1.0 expanded capacity with a larger architecture, enhanced context length, and improved support for high-resolution generation. More recent releases such as Stable Diffusion 3.0 and 3.5 have restructured the generative backbone and expanded scale, reflecting rapid advancements in diffusion-based generative modeling.