Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Diffusion 2 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Automatic1111's legendary web UI for Stable Diffusion, the most comprehensive and full-featured AI image generation application in existence.
Model Report
stabilityai / Stable Diffusion 2
Stable Diffusion 2 is an open-source text-to-image diffusion model developed by Stability AI that generates images at resolutions up to 768×768 pixels using latent diffusion techniques. The model employs an OpenCLIP-ViT/H text encoder and was trained on filtered subsets of the LAION-5B dataset. It includes specialized variants for inpainting, depth-conditioned generation, and 4x upscaling, offering improved capabilities over earlier versions while maintaining open accessibility for research applications.
Explore the Future of AI
Your server, your data, under your control
Stable Diffusion 2 is an open-source, text-to-image generative model developed by Stability AI and released on November 23, 2022. Building upon prior work in latent diffusion by researchers including Robin Rombach and Patrick Esser in collaboration with the CompVis Group at LMU Munich, Stable Diffusion 2 advances the capabilities of text-to-image synthesis through architectural improvements and new features. The model introduces higher image resolutions, new guidance mechanisms, enhanced inpainting, and novel depth-aware generation, broadening the scope of image synthesis and research applications. It relies on latent diffusion techniques, leveraging a pretrained text encoder, and has been trained on large, filtered datasets to facilitate both performance and responsible use.
Sample outputs from Stable Diffusion 2: "A rabbit in a beanie and sunglasses" and "An astronaut mowing a lawn," generated at 768x768 resolution.
Stable Diffusion 2 employs the latent diffusion model framework, which encodes images into lower-dimensional latent representations to improve data efficiency and computational performance, as outlined in the CVPR 2022 paper on High-Resolution Image Synthesis with Latent Diffusion Models. Images are compressed during training, allowing the model to focus on the most salient features for image generation.
A central component is the OpenCLIP-ViT/H text encoder, developed by LAION and integrated with Stability AI's support. This encoder translates user prompts into vector representations, which are then utilized by the U-Net backbone within the latent diffusion process through cross-attention mechanisms.
Significant improvements over Stable Diffusion 1.5 include expanded resolution options (512×512 and 768×768 pixels), offering enhanced output quality and detail. The model suite also introduces specialized variants, such as a 4x upscaling diffusion model for generating high-resolution images, and a depth-to-image diffusion model that conditions outputs on inferred image depth maps. These advances facilitate novel applications while preserving coherence, especially in tasks involving significant image transformations.
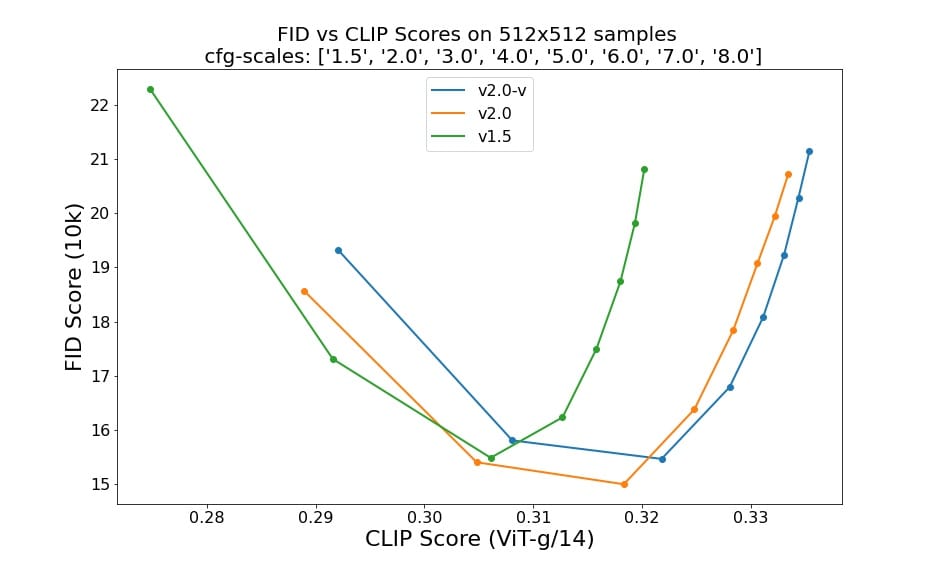
Performance metrics for Stable Diffusion v2.0 variants and v1.5, visualizing FID and CLIP evaluation scores on 512x512 samples across various guidance scales.
Stable Diffusion 2 models are trained on the LAION-5B dataset and curated subsets, filtered for safety and aesthetics. Data preprocessing includes the application of the LAION NSFW classifier (with a conservative threshold) to minimize harmful or inappropriate content, and the Improved Aesthetic Predictor for aesthetic quality.
Training follows a multi-stage regimen. For instance, the 512-base model undergoes hundreds of thousands of steps on LAION-5B, first at lower resolution and then at 512×512. The 768-v variant extends training at higher resolution, employing a v-objective to further improve sample fidelity. Specialized models, such as depth-to-image, are fine-tuned with additional input channels for depth information, based on estimates from MiDaS. Inpainting models are refined using strategies from LAMA with masked latent representations, while the upscaler uses high-resolution image crops and introduces a controllable noise level for guided upsampling.
These model checkpoints are publicly released to promote transparency and reproducibility in research, as detailed in the Stable Diffusion v2 Model Card.
Capabilities and Applications
Stable Diffusion 2 provides robust text-to-image generation, supporting intricate synthesis from textual prompts. The new models yield outputs with default resolutions up to 768×768 pixels and can upscale to 2048×2048 or higher using latent upscaling. The integration of depth-based conditioning enables transformations that preserve structural coherence and realism.
Stable Diffusion 2 output: "Photo overlooking a lush green valley," generated via text prompt.
For image editing, the inpainting diffusion model enables rapid and seamless alteration of specific image regions under textual guidance. This allows targeted modifications, such as changing clothing or objects, while maintaining surrounding coherence.
Demonstration of Stable Diffusion 2 inpainting: clothing and accessory alterations in a street scene under different text prompts.
Typical research uses encompass generative model benchmarking, art and design experimentation, educational tool development, and studies of model biases and limitations. The system supports classifier-free guidance, with common inference settings using a guidance scale of 7.5 and 50 DDIM sampling steps as referenced in the Stable Diffusion Model Card.
Limitations and Considerations
Despite its advancements, Stable Diffusion 2 exhibits several notable limitations. The model does not achieve perfect photorealism, and its ability to handle text rendering and fine compositional tasks remains limited. Generation of human faces and figures is imperfect, and the model is primarily proficient with English-language prompts due to its training data.
Biases present in the data can manifest in outputs, particularly in the representation of non-western cultures or non-English prompts. Although safety classifiers and aesthetic filters are integrated, absolute filtering is not guaranteed, and outputs may reflect societal biases embedded in the source data, as documented in the model's technical report.
The underlying autoencoding process is lossy, which can affect image fidelity, especially after repeated transformations. The developers recommend using the model for research and creative exploration rather than for applications requiring error-free or sensitive outputs.
Stable Diffusion 2 is distributed under the CreativeML Open RAIL++-M License, an open-source framework adapted from the RAIL Initiative and BigScience project. This license allows commercial and research applications, but it cautions users to implement additional safeguards in light of potential biases and limitations. The model weights are released as research artifacts.
Impact and Model Lineage
Stable Diffusion 2 is part of a broader family of latent diffusion models. The initial Stable Diffusion 1.5 set foundational standards for accessible, high-performance image generation by providing openly available, large-scale models. Both Stable Diffusion 1.5 and Stable Diffusion 2 share the latent diffusion backbone but differ in text encoder architecture, training procedures, and support for higher resolutions.
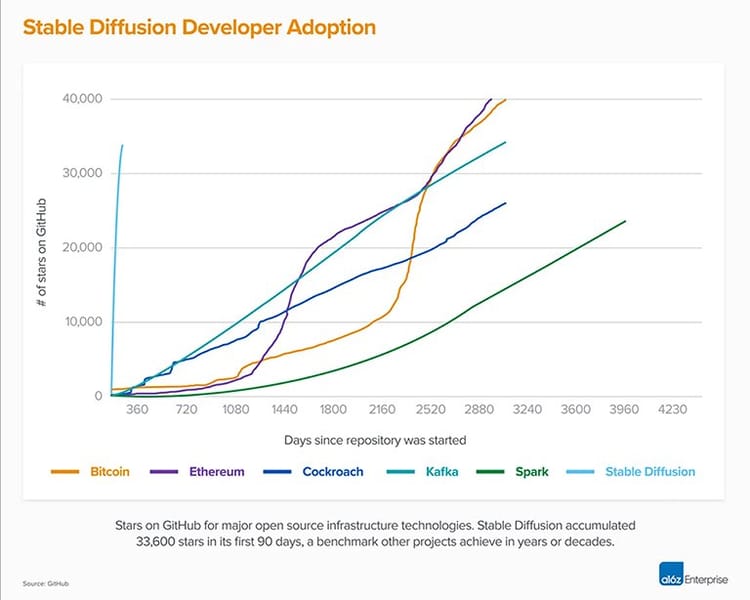
The release and open distribution of Stable Diffusion contributed to rapid community adoption, sparking significant interest in generative AI. This trend is exemplified by the sharp initial rise in developer engagement, noted in Stable Diffusion GitHub metrics.
Stable Diffusion's rapid accumulation of GitHub stars within its first 90 days, compared to other major open-source projects.