Note: Stable Video 4D weights are released under a Stability AI Non-Commercial Research Community License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Video 4D using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
stabilityai / Stable Video 4D
Stable Video 4D (SV4D) is a generative video-to-video diffusion model that produces consistent multi-view video sequences of dynamic objects from a single input video. The model synthesizes temporally and spatially coherent outputs from arbitrary viewpoints using a latent video diffusion architecture with spatial, view, and frame attention mechanisms, enabling efficient 4D asset generation for applications in design, game development, and research.
Explore the Future of AI
Your server, your data, under your control
Stable Video 4D (SV4D) is a generative video-to-video diffusion model developed by Stability AI that produces consistent multi-view video sequences of dynamic objects from a single input video. Building upon prior work in video and 3D generative models, SV4D introduces a novel approach for synthesizing temporally and spatially consistent video outputs from arbitrary user-specified viewpoints, facilitating downstream 4D (spatio-temporal) asset generation. The model’s technical report was introduced in July 2024 and published for ICLR 2025, with detailed architecture, benchmarks, and applications available through the official project page and arXiv manuscript.
Model output example from Stable Video 4D, demonstrating multi-view, temporally coherent video synthesis with a dynamically rendered 3D head.
SV4D is structured as a latent video diffusion model, leveraging both Stable Video Diffusion (SVD) and Stable Video 3D (SV3D). Its architecture centers on a multi-layer UNet backbone, where each layer integrates spatial, view, and frame attention mechanisms to jointly process multi-view and multi-frame video data. Specifically, view attention promotes consistency across synthesized camera perspectives at each timestep, while frame attention ensures temporal coherence within each viewpoint. The model incorporates sinusoidal embeddings of the camera poses and utilizes visual motion cues from the input monocular video to condition generation.
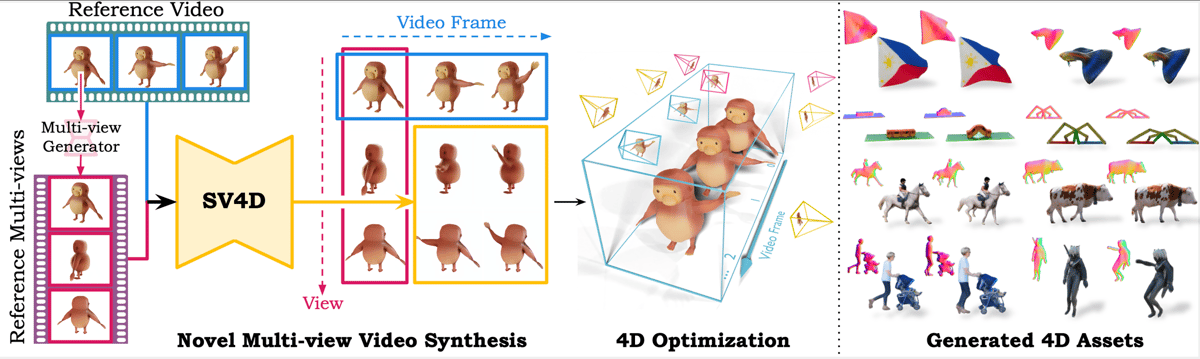
SV4D takes as input a reference video and a set of reference multi-view images—often synthesized from the reference frame via SV3D—to guide its generative process. The model is trained to output an image matrix consisting of five temporal frames across eight novel camera views at 576×576 resolution, resulting in a total of 40 frames forming a spatio-temporal grid. A distinctive feature of SV4D’s inference pipeline is its mixed sampling strategy, wherein anchor frames are first sparsely generated, then used to interpolate additional frames while maximizing spatio-temporal consistency.
SV4D pipeline: from reference video and multi-view frames, through novel multi-view video synthesis and 4D optimization, to generated 4D assets. SV4D enables joint multi-view and multi-frame video generation.
The primary dataset for SV4D's training is ObjaverseDy, a curated dynamic subset of the broader Objaverse collection, containing rendered sequences of animated 3D objects across diverse motions and categories. To ensure robust learning of temporal and spatial dynamics, ObjaverseDy was filtered for object-centricity, motion variety, and adequate sequence length. During training, SV4D’s frame attention is initialized from SVD, while view attention and other network weights are sourced from SV3D, leveraging priors from both video and 3D generation tasks.
Progressive training is employed: initial iterations focus on static camera orbits before fine-tuning with dynamic orbits, enabling gradual adaptation to more complex motion patterns. Precomputed visual and CLIP embeddings enhance training efficiency and reduce memory cost. The model utilizes efficient multidimensional diffusion losses (EMD) and photometric and geometric objectives for downstream 4D optimization, enabling consistent multi-step refinement of generated assets.
The SV4D technical report, published for ICLR 2025, details methodologies, architecture, and evaluation benchmarks for the model.
SV4D has been benchmarked on multiple datasets including ObjaverseDy, Consistent4D, and the DAVIS dataset, demonstrating high levels of multi-view and temporal consistency relative to prior methods. The model synthesizes five-frame, eight-view video matrices in approximately 40 seconds, with complete 4D asset optimization processes requiring 20–25 minutes per object—a decrease in computational demand compared to score distillation sampling (SDS)-based strategies.
Quantitative evaluation metrics include LPIPS (Learned Perceptual Image Patch Similarity), CLIP-S (semantic similarity via CLIP), and several Frechet Video Distance (FVD) variants measuring temporal and spatial cohesion. SV4D achieves strong scores across these benchmarks, for instance producing LPIPS values as low as 0.131 and FVD values such as FVD-F: 659.66 and FV4D: 614.35 on 4D generation tasks. User studies indicate preference for SV4D outputs both in novel-view synthesis (73.3% preference) and in optimized 4D assets. The model demonstrates notable improvements in spatial–temporal consistency and subject fidelity compared to SV3D, Diffusion², STAG4D, and other contemporary video synthesis approaches.
Typical Applications
SV4D’s joint modeling of time and viewpoint unlocks diverse applications across design, education, research, and creative content generation. Artists and designers can utilize SV4D to visualize objects from arbitrary perspectives and animate dynamic scenes for virtual staging or concept development. The model supports the efficient creation of 4D assets in game development and virtual reality, enabling immersive environments with high visual coherence. In research, SV4D serves as a tool for investigating generative consistency, spatio-temporal learning, and the challenges of 4D representation.
Generated multi-view videos can be further optimized into dynamic 3D representations (dynamic NeRFs) without requiring intensive, multi-stage distillation pipelines, fostering rapid prototyping of animated 3D models for simulation, education, and interactive media.
Limitations and Usage
As of release, SV4D is predominately trained on synthetic datasets like ObjaverseDy, and further work is ongoing to robustly generalize to real-world video content. Current capabilities are optimized for object-centric, non-factual input videos; generating accurate depictions of specific people or events is outside the model’s intended design. SV4D remains a research-phase model and may be subject to continuing updates in functionality and performance.
SV4D extends the generative framework pioneered by Stable Video Diffusion (SVD), which focuses on image-to-video synthesis, and Stable Video 3D (SV3D), which generates orbital multi-view videos from single images. SV4D uniquely supports joint multi-frame, multi-view generation and serves as a foundation for future advances in high-fidelity spatio-temporal asset creation.