Note: Stable Video Diffusion weights are released under a Stability AI Non-Commercial Research Community License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Video Diffusion using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
stabilityai / Stable Video Diffusion
Stable Video Diffusion is a latent diffusion model developed by Stability AI that generates short video clips from single still images. Built upon Stable Diffusion 2.1 with added temporal convolution and attention layers, the model comprises 1.52 billion parameters and supports up to 25 frames at customizable frame rates. Trained on curated video datasets, SVD demonstrates competitive performance in image-to-video synthesis and multi-view generation tasks.
Explore the Future of AI
Your server, your data, under your control
Stable Video Diffusion (SVD) is a generative video model developed by Stability AI to synthesize short video clips from a single still image. Released as a research preview on November 21, 2023, SVD exemplifies the application of latent diffusion techniques to the video synthesis domain, with a particular focus on temporal consistency, motion control, and adaptability to a range of generative video tasks. The model and its research are situated within the broader context of diffusion-based generative modeling, leveraging advances rooted in image diffusion models to address the unique challenges posed by video generation, including motion realism and frame coherence.
Sample output from Stable Video Diffusion: The model converts a single image into a short video clip with coherent motion and temporal consistency. Input prompt: a still image of an elderly man standing on a beach.
Stable Video Diffusion adopts a latent video diffusion approach built atop the Stable Diffusion 2.1 image model, extending the architecture with temporal convolution and attention layers after each spatial convolution and attention operation. This design allows SVD to model the temporal dimension of video frames in addition to spatial structure, drawing on architectural insights outlined by Blattmann et al. The full model, including both spatial and temporal modules, comprises approximately 1.52 billion parameters, with 656 million devoted specifically to temporal processing, reflecting the complexity needed for realistic motion synthesis research paper.
Key technological innovations within SVD include micro-conditioning on frame rates, an EDM-based noise scheduling framework for improved high-resolution finetuning, and classifier-free guidance with intermittent dropout of conditioning, enhancing generalization and sample diversity. For the image-to-video task, CLIP image embeddings condition the model on the input image, and noise-augmented conditioning frames are concatenated to the UNet’s input for better preservation of visual detail and to facilitate robust guidance during denoising. The model supports explicit motion control, either through direct prompting of temporal layers with motion cues or by leveraging LoRA modules trained on specific movement patterns.
Training Data and Methodology
SVD employs a multi-stage training strategy that spans pretraining on still images and large-scale uncurated and curated video datasets, followed by high-quality finetuning. The process commences with pretraining on Stable Diffusion 2.1 for strong visual representation, then advances to video pretraining on the Large Video Dataset (LVD), which originally contained 580 million annotated video pairs. Through systematic curation—using measures such as optical flow for static scene removal, OCR for filtering frames with excessive text, and CLIP/aesthetic scoring—over two-thirds of the data are excluded, resulting in a curated "LVD-F" dataset comprising 152 million high-quality examples technical methods.
For finetuning, SVD is trained on a smaller, richly captioned, high-fidelity dataset of around 250,000 video clips, increasing output resolution up to 576×1024 pixels. This multilayered training pipeline, in conjunction with classifier-free guidance techniques, provides a foundation for both high visual quality and robust adherence to conditioning signals.
The training procedure was computationally intensive, resulting in an estimated energy consumption of approximately 64,000 kWh.
Features, Capabilities, and Performance
SVD is primarily designed for image-to-video generation, producing videos up to 14 frames in length, with an extended "SVD-XT" model supporting 25 frames and customizable frame rates from 3 to 30 frames per second model details. The model maintains temporal consistency through a finetuned f8-decoder and includes a frame-wise decoder for alternate use cases.
An important characteristic of SVD is its ability to support a diverse set of generative video tasks. It demonstrates adaptability to downstream problems such as multi-view synthesis from a single image and frame interpolation for smoother motion. The underlying architecture also supports explicit motion control, leveraging LoRA adaptations trained on curated datasets that encode distinct motion cues or camera movements. "Camera motion LoRAs" have been developed for controlling horizontal pans, zooms, and static views, enabling nuanced manipulation of temporal dynamics in generated content.
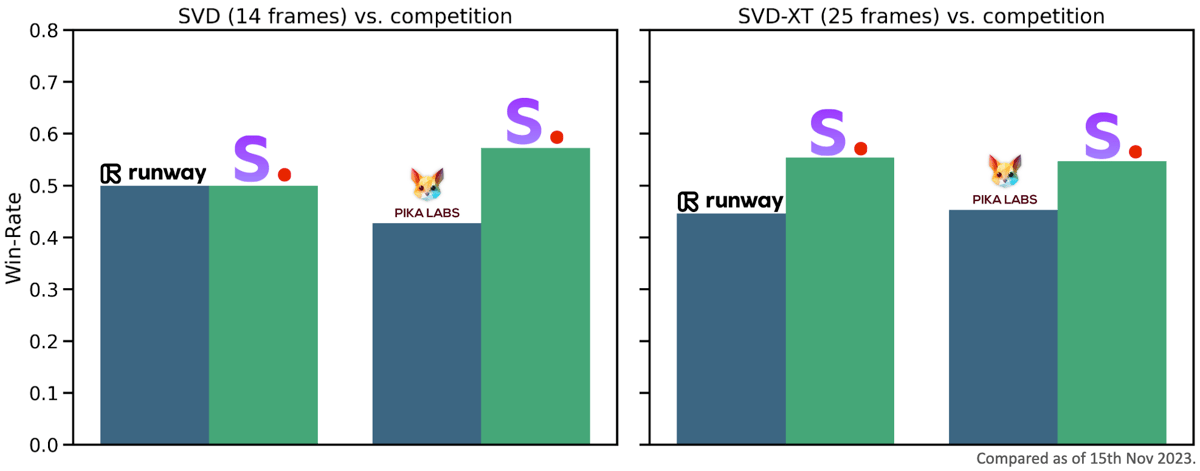
Human user preference studies indicate that SVD and SVD-XT achieve higher win-rates than competing video generation models on video quality.
Empirical evaluations underline SVD’s competitive performance. On the UCF-101 dataset for zero-shot text-to-video generation, SVD achieves an FVD (Fréchet Video Distance) score of 242.02—lower (and thus better) than scores for Make-A-Video, Video LDM, and CogVideo. In multi-view synthesis, SVD-MV (the multi-view finetuned variant) achieves state-of-the-art or competitive results on the Google Scanned Objects test set, outperforming alternatives such as SyncDreamer and Zero123XL in PSNR, LPIPS, and CLIP-S metrics benchmark table.
Use Cases and Applications
Stable Video Diffusion is intended for research and non-commercial exploration of generative video systems. Its primary applications include converting a static image to a dynamic video, rendering text-conditioned video via adapted variants, and synthesizing multiple views of objects for 3D visualization. Additional use cases encompass frame interpolation for smoother temporal transitions and explicit control over camera movement sequences in generated video. The model offers a resource for studying generative model safety, probing limitations and biases, and producing visual content for creative or educational tools.
Researchers can use SVD to analyze the generative process, evaluate the safe deployment of diffusion models, and explore their applicability to domains such as digital art or motion design.
Limitations and Considerations
While SVD advances the state of image-to-video synthesis, several key limitations persist. The generated videos are relatively short, typically extending to no more than 4 seconds. Photorealism in generated sequences remains imperfect, with occasional failures in rendering faces, text, or rapid motion. The model's variants do not currently support full open-ended text prompting for direct content control, and generated outputs may lack pronounced or complex movement unless explicitly steered via motion-specific LoRAs. SVD’s autoencoding is lossy, and inference is computationally intensive, leading to slow generation times and high memory requirements.
Stable Video Diffusion is released strictly for research use, with deployment governed by Stability AI's acceptable use policy and relevant licensing constraints license overview. The model was not trained to produce factual or real-world representations and should not be used for generating misleading or unlawful content. By default, watermarking tools are integrated to aid in output attribution.