Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek R1 (0528) using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek R1 (0528)
DeepSeek R1 (0528) is a large language model developed by DeepSeek-AI featuring 671 billion total parameters with 37 billion activated during inference. Built on the DeepSeek-V3-Base architecture using Mixture-of-Experts design, it employs Group Relative Policy Optimization and multi-stage training with reinforcement learning to enhance reasoning capabilities. The model supports 128,000 token context length and demonstrates improved performance on mathematical, coding, and reasoning benchmarks compared to its predecessors.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-R1 (0528) is an advanced generative AI model within the DeepSeek-R1 family, developed by DeepSeek-AI as part of their efforts to improve automated reasoning in large language models. This release builds upon the original DeepSeek-R1, introducing enhancements in reasoning ability, inference depth, and response reliability. The model has been evaluated against various benchmarks to assess its reasoning, coding, and general language processing capabilities, and incorporates novel training methodologies to address shortcomings observed in its predecessors.
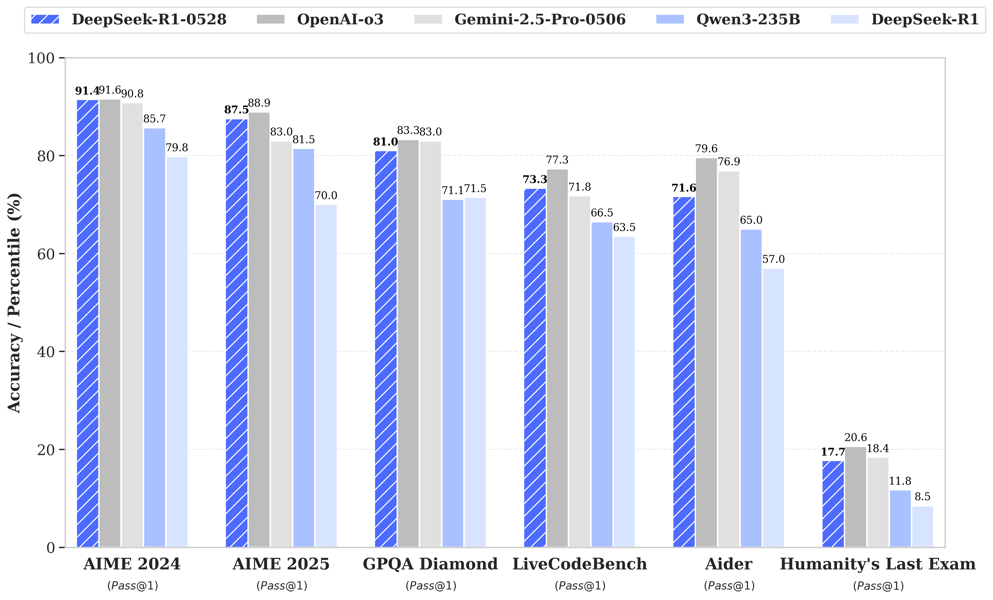
Performance comparison of DeepSeek-R1-0528 and other advanced models on diverse academic and code benchmarks, including AIME, GPQA Diamond, and LiveCodeBench.
DeepSeek-R1 (0528) is distinguished from earlier versions through its optimized post-training algorithms and the inclusion of a refined multi-stage learning pipeline. The model employs reinforcement learning methods—particularly Group Relative Policy Optimization (GRPO)—to maximize rewards without requiring a separate critic model, thereby streamlining the policy optimization process. Training proceeds through two supervised fine-tuning (SFT) stages and two reinforcement learning (RL) stages, with the initial phase leveraging "cold-start" data comprised of thousands of curated long-form Chain-of-Thought (CoT) reasoning samples.
The model incorporates a language consistency reward during reinforcement learning to mitigate language mixing, especially in multilingual prompts, enhancing readability and user preference alignment. Additionally, DeepSeek-R1 (0528) introduces support for system prompts and relaxes earlier requirements to initiate responses with explicit reasoning tags. These elements collectively contribute to reduced hallucination rates, improved function calling, and more reliable output formatting compared to earlier iterations.
Performance and Benchmark Evaluation
DeepSeek-R1 (0528) exhibits competitive results across a range of established benchmarks. Evaluations show notable improvements in reasoning-intensive tasks, code generation, and mathematical problem-solving compared to its predecessors. For instance, on the AIME 2025 mathematics benchmark, DeepSeek-R1 (0528) achieved an accuracy of 87.5%, a substantial increase over the original DeepSeek-R1's 70%. The model also demonstrates lower hallucination rates and enhanced inference depth, averaging 23,000 tokens per question—a statistic indicative of its deeper processing capability.
In comparative studies against other prominent models such as OpenAI O3 and Gemini 2.5 Pro, DeepSeek-R1 (0528) closely approaches or, in certain cases, surpasses their scores on tasks like AIME 2024, GPQA Diamond, LiveCodeBench, and complex general reasoning benchmarks.
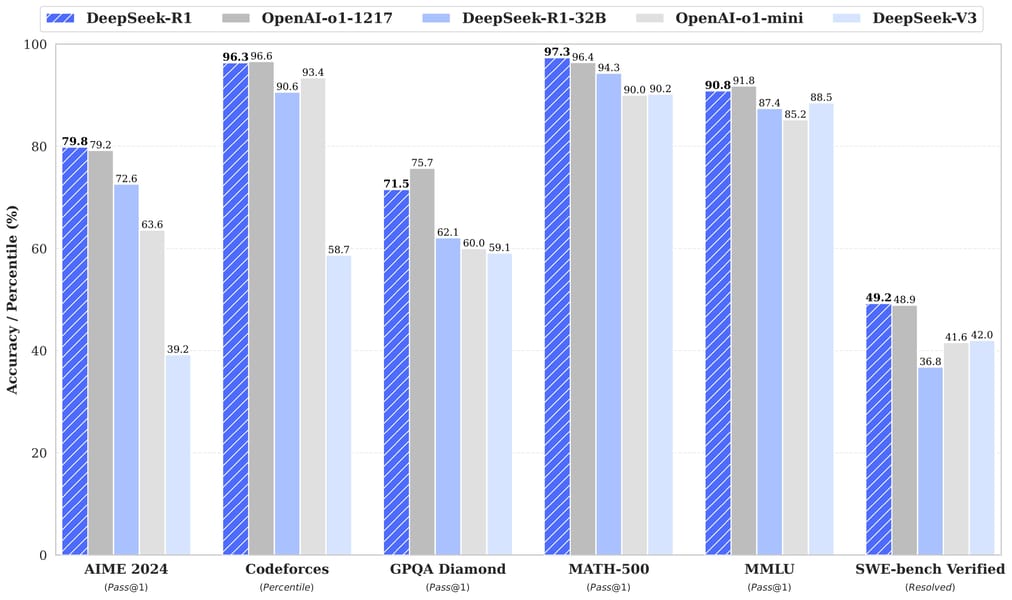
Comparative analysis highlighting DeepSeek-R1's relative accuracy on mathematics (AIME 2024, MATH-500), coding (Codeforces, SWE-bench Verified), and general reasoning (GPQA Diamond, MMLU) tasks.
Additionally, DeepSeek-R1 (0528) has shown improvements in computer science benchmarks such as LiveCodeBench and SWE-bench Verified, with enhanced support for code-related tasks and increased robustness in software engineering evaluations.
Model Architecture and Underlying Technology
DeepSeek-R1 (0528) is based on the DeepSeek-V3-Base model and utilizes a Mixture-of-Experts (MoE) architecture. The model comprises a total of 671 billion parameters, of which 37 billion are activated during inference. It supports a context length of up to 128,000 tokens, with the 0528 version specifically tailored for outputs up to 64,000 tokens per generation. The RL approach is grounded in GRPO, which facilitates efficient and stable policy improvement based on relative reward advantages.
Reward modeling primarily employs rule-based metrics, assessing both the accuracy of model outputs (such as correct answers for deterministic tasks and successful code execution feedback) and the clarity of reasoning structure. By contrast, neural reward models are generally eschewed due to the risk of reward hacking and elevated training complexity.
Data, Distillation, and Model Family
Training data for DeepSeek-R1 (0528) places strong emphasis on the quality and diversity of reasoning examples. The cold-start phase involves a curated selection of long-form CoT samples, enhanced by human annotation, to address repetitive or unreadable responses and to avoid unwanted language blending. Subsequent SFT datasets combine new reasoning samples identified through RL sampling with general language tasks, further refining the model's broad capabilities.
A significant innovation in the DeepSeek-R1 program is the use of distillation, where the model's reasoning patterns are transferred to smaller, open-source models—including the Qwen2.5 and Llama3 series. This approach allows models with parameter counts ranging from 1.5B to 70B to achieve improved reasoning performance compared to models trained via direct RL at smaller scales, demonstrating the efficacy of distilled reasoning in compact architectures.
Limitations and Model Licensing
While DeepSeek-R1 (0528) demonstrates advances in reasoning and general language processing, certain limitations persist. The model, though improved, may still be sensitive to input prompts and can exhibit language mixing outside of Chinese and English use cases. Performance in some areas, such as advanced multi-turn conversations or highly structured outputs, may not fully match that of DeepSeek-V3 or other highly specialized models.
DeepSeek-R1 (0528), along with its associated code and model weights, is released under the MIT License, permitting broad use, modification, and further derivative works. Distilled variants built on other base architectures inherit their respective open-source licenses, such as Apache 2.0 for Qwen models or specific Llama licenses for Llama-based derivatives.
Applications
DeepSeek-R1 (0528) is applicable across a spectrum of tasks requiring advanced reasoning ability, including mathematical contests (e.g., AIME, HMMT, CNMO), competitive programming (e.g., Codeforces), software engineering assessment (e.g., SWE Verified, Aider-Polyglot), and general language tasks involving long-context understanding, document analysis, creative writing, and summarization. The model's enhancements position it for effective use in research, data analysis, and problem-solving domains that demand reliable and interpretable automated reasoning.