Launch a dedicated cloud GPU server running Laboratory OS to download and run MiniMax Text 01 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
MiniMaxAI / MiniMax Text 01
MiniMax Text 01 is an open-source large language model developed by MiniMaxAI featuring 456 billion total parameters with 45.9 billion active per token. The model employs a hybrid attention mechanism combining Lightning Attention with periodic Softmax Attention layers across 80 transformer layers, utilizing a Mixture-of-Experts design with 32 experts and Top-2 routing. It supports context lengths up to 4 million tokens during inference and demonstrates competitive performance across text generation, reasoning, and coding benchmarks.
Explore the Future of AI
Your server, your data, under your control
MiniMax-Text-01 is an open-source large language model (LLM) developed by MiniMax, designed to exhibit extended context understanding and reasoning capabilities. It is part of the MiniMax-01 series, which also features the multi-modal vision-language model MiniMax-VL-01. MiniMax-Text-01 was publicly released on January 15, 2025, and its technical details have been made available to the research community.
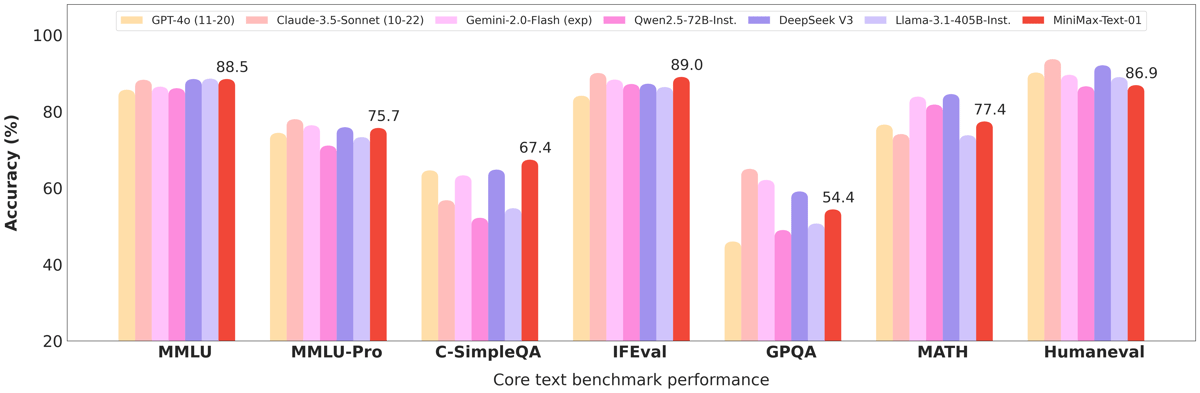
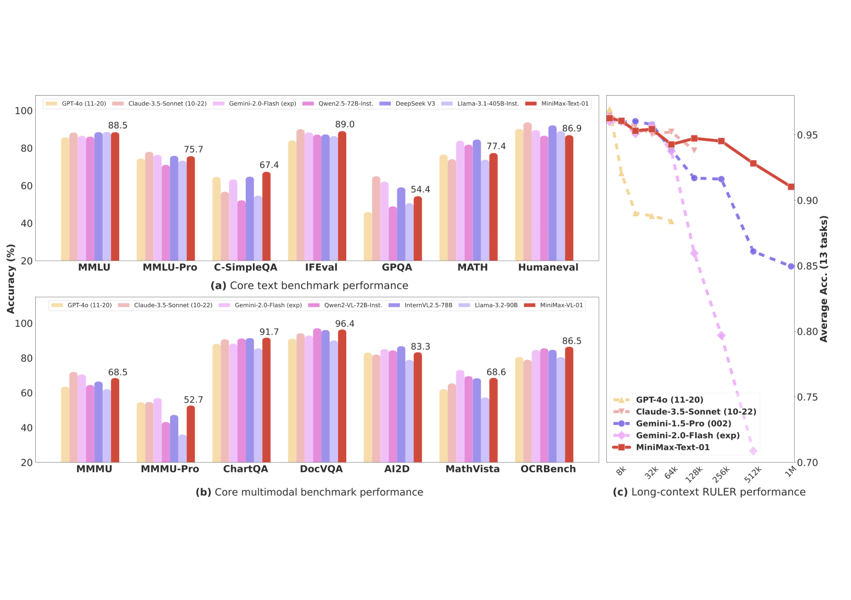
Core text benchmark accuracy of MiniMax-Text-01 compared to large language models across seven evaluation tasks.
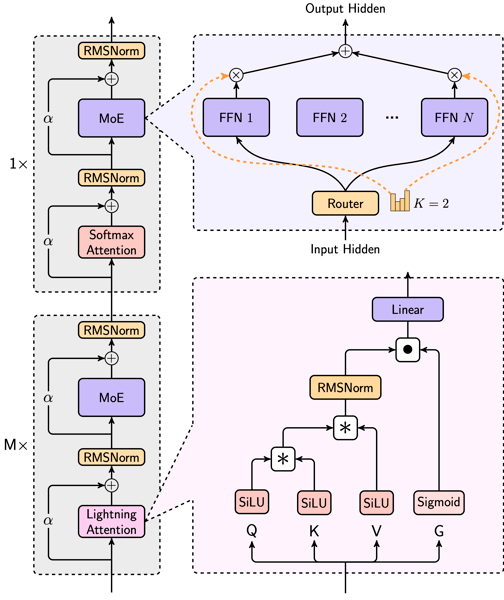
MiniMax-Text-01 encompasses 456 billion total parameters, with 45.9 billion parameters actively used per token. The architecture employs a hybrid attention mechanism that combines Lightning Attention—a linear, I/O-optimized attention variant derived from TransNormer—with periodic Softmax Attention layers. Specifically, a Softmax Attention layer is interleaved after every seven Lightning Attention layers, resulting in a total of 80 transformer layers. Each layer incorporates 64 attention heads with an attention head dimension of 128, and half of each attention head utilizes Rotary Position Embedding (RoPE) with a large base frequency, supporting long-sequence modeling.
A Mixture-of-Experts (MoE) design is employed, comprising 32 experts and using a Top-2 routing strategy. This allows each token to be routed through selected expert feed-forward networks, enhancing scalability while optimizing computational efficiency. A global routing innovation ensures balanced load distribution and prevents collapse in expert utilization. The model further integrates DeepNorm for training stability and leverages parallelization strategies such as Linear Attention Sequence Parallelism Plus (LASP+), varlen ring attention, and Expert Tensor Parallelism (ETP), enabling MiniMax-Text-01 to sustain sequence context lengths up to 1 million tokens during training and up to 4 million tokens during inference.
Architecture diagram highlighting the hybrid Lightning/Softmax Attention mechanism and the Top-2 Mixture-of-Experts design in MiniMax-Text-01.
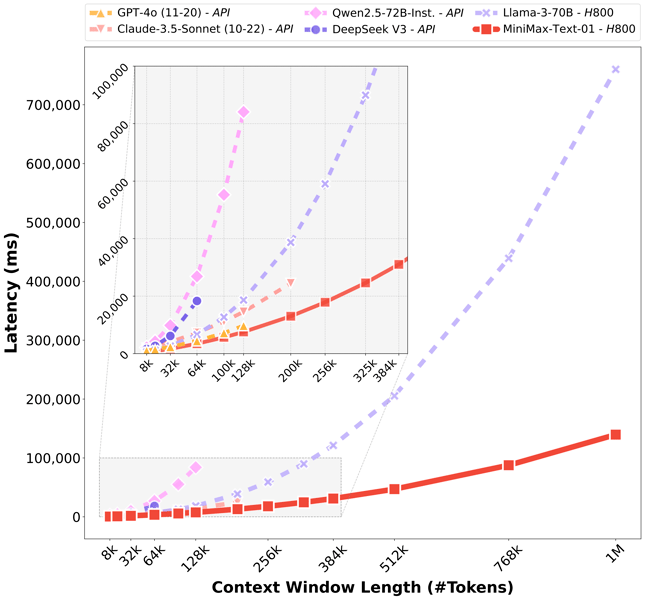
Custom CUDA kernels and inference optimizations yield efficient deployment, supporting over 75% model flops utilization on contemporary hardware platforms. Recommended quantization for loading the model is int8, balancing model size and inference speed.
Training Data and Methods
The pre-training corpus for MiniMax-Text-01 was curated from diverse sources, including academic literature, books, web content, and programming code. A well-defined filtering pipeline, using a reward labeler based on earlier MiniMax models, selects high-quality data across multiple axes such as knowledge depth and document helpfulness. Data mixture balancing and deduplication strategies ensure both diversity and consistency.
Tokenization employs byte-level Byte Pair Encoding (BPE), favoring multilingual content and a vocabulary of 200,064 tokens. The training strategy adopts a staged approach: after initial pretraining, a three-phase context extension up-samples long-sequence data, and post-training includes supervised fine-tuning (SFT), offline reinforcement learning via Direct Preference Optimization (DPO), and online reinforcement learning. Safety alignment is managed by constructing a harmless reward model that balances utility with content reliability.
Benchmark Performance
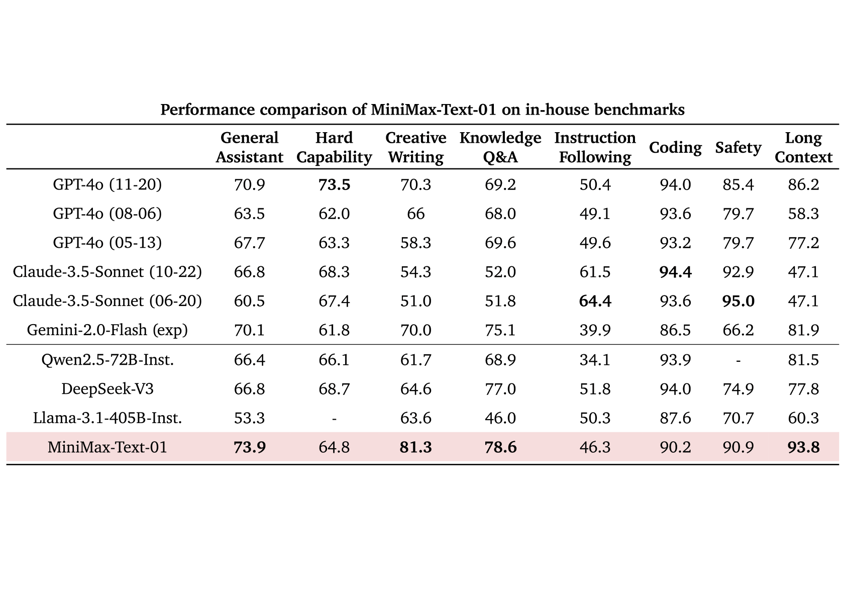
MiniMax-Text-01 exhibits performance across a broad range of academic and applied benchmarks, with results comparable to or exceeding those of other LLMs such as GPT-4o, Claude-3.5-Sonnet, and Gemini-1.5-Pro. Results in core benchmarks—including multi-task language understanding, open-domain question answering, logical reasoning, mathematical problem-solving, and code synthesis—demonstrate its general and specialized capabilities.
Benchmark comparison table showing MiniMax-Text-01's scores on core academic tasks relative to international LLMs.
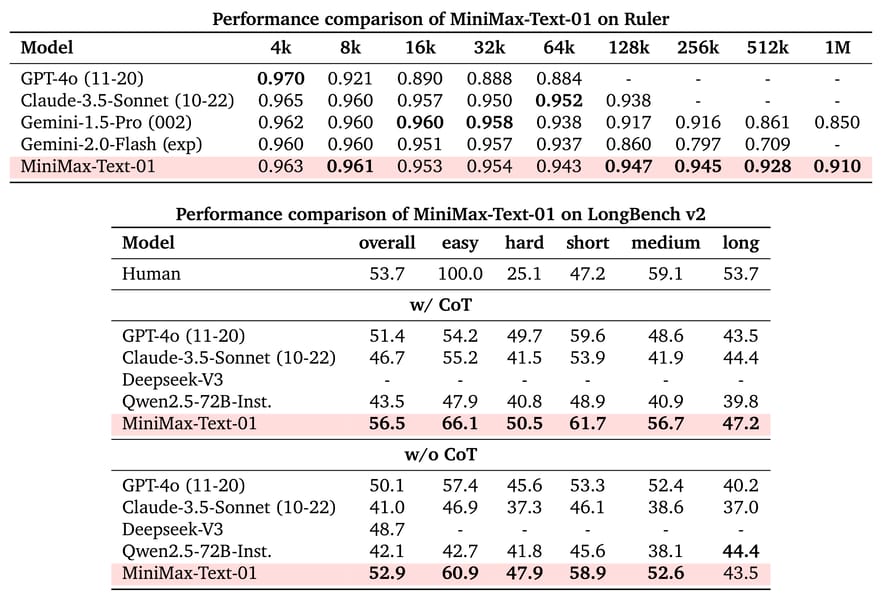
In ultra-long context evaluations, the model achieves 100% accuracy in the 4-million-token Needle-in-a-Haystack retrieval task, and maintains minimal degradation on the RULER benchmark’s 1-million-token context length. MiniMax-Text-01 also achieves high scores on the LongBench v2 benchmark, with and without Chain-of-Thought reasoning. In-house evaluations indicate its performance in creative writing, information retrieval, safety, and document analysis productivity scenarios.
Benchmark tables summarizing MiniMax-Text-01’s performance in the RULER and LongBench v2 long-context evaluations.
MiniMax-Text-01 is designed as a general-purpose AI assistant, supporting a variety of applications including complex question answering, creative writing, coding, and long-document analysis. Its ultra-long context window and robust inference optimizations make it suited for tasks such as document translation, summarization, and productivity scenarios involving large-scale information processing. The model also supports function calling, enabling integration with external tools and APIs via structured outputs in JSON format, and is compatible with the Transformers ecosystem.
Limitations and Ongoing Research
Despite its performance in most areas, MiniMax-Text-01’s capabilities in advanced programming and mathematical reasoning are constrained by current training data limitations. Its hybrid architecture retains some softmax attention layers (1/8 of total attention layers), and research continues into architectures entirely based on linear attention, aiming to facilitate theoretically unlimited context windows with further efficiency gains.
Challenges persist in evaluating long-text reasoning, as available benchmarks typically focus on retrieval or synthetic tasks. Future efforts are dedicated to enhancing in-context learning and scaling data quality for extended reasoning ability in practical, real-world applications.
Model Series and Multimodal Extensions
MiniMax-Text-01 is the foundational language model in the MiniMax-01 series. Its multimodal sibling, MiniMax-VL-01, leverages a Vision Transformer (ViT) for visual encoding, coupled with a two-layer MLP projector, and utilizes MiniMax-Text-01 as its base language model. MiniMax-VL-01 supports variable visual input resolutions and has attained scores in multiple vision-language leaderboards, although challenges remain for advanced mathematical reasoning in multimodal settings.
Comprehensive model comparison charts: (a) text benchmark performance, (b) multimodal benchmarks (MiniMax-VL-01), (c) RULER performance showing accuracy at increasing input lengths.
The MiniMax-Text-01 model weights are distributed under the MiniMax Model Agreement, and the accompanying code is available under the MIT License. Researchers and developers are directed to consult the license documentation for detailed usage and redistribution terms.