Launch a dedicated cloud GPU server running Laboratory OS to download and run Mistral Small 3 (2501) using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Mistral AI / Mistral Small 3 (2501)
Mistral Small 3 (2501) is a 24-billion-parameter instruction-fine-tuned language model developed by Mistral AI and released under an Apache 2.0 license. The model features a 32,000-token context window, multilingual capabilities across eleven languages, and demonstrates competitive performance on benchmarks including MMLU Pro, HumanEval, and instruction-following tasks while maintaining efficient inference speeds.
Explore the Future of AI
Your server, your data, under your control
Mistral Small 3 (2501) is a 24-billion-parameter instruction-fine-tuned large language model (LLM) developed by Mistral AI. Released on January 30, 2025, Mistral Small 3 is positioned in the "small" LLM category (models with fewer than 70 billion parameters), demonstrating instruction-following performance, low latency, and competitive benchmark results across a variety of natural language tasks. The model is built upon the Mistral-Small-24B-Base-2501 foundation, emphasizing efficiency and versatility while adopting an Apache 2.0 license for broad accessibility.
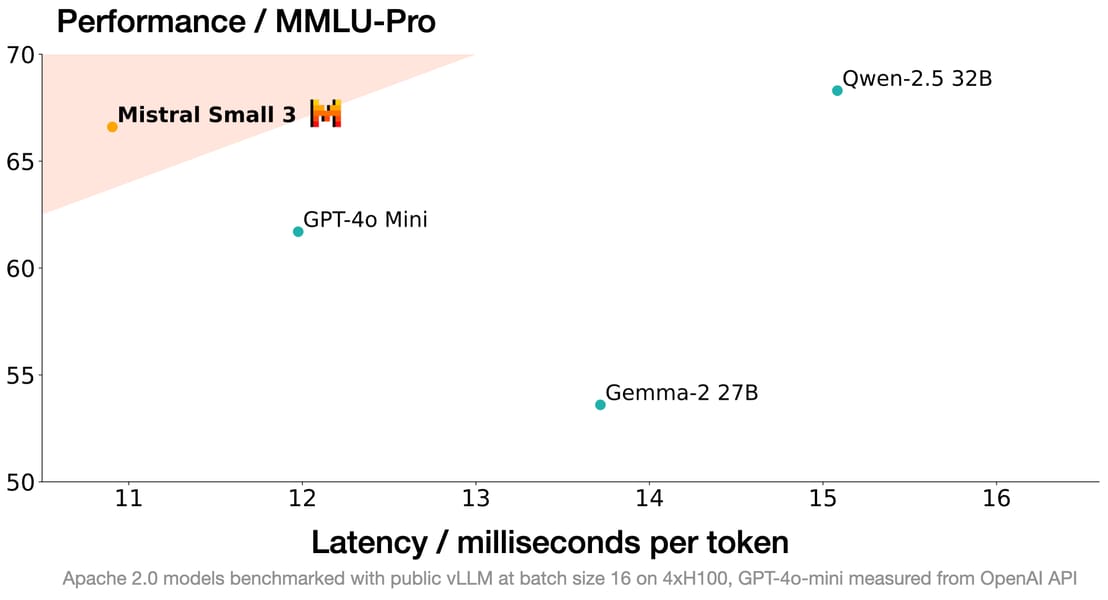
A performance versus latency scatter plot shows Mistral Small 3 positioned in an optimal region relative to peer models, according to MMLU-Pro and ms/token benchmarks.
Mistral Small 3 comprises 24 billion parameters and utilizes an architecture explicitly designed for high efficiency and responsiveness. It features a streamlined configuration with fewer layers than many competing models, which can reduce time per forward pass. The model offers a 32,000-token context window, allowing it to effectively handle extended conversations or analyses. Multilingual capabilities are intrinsic to the design; Mistral Small 3 can process and generate text in languages including English, French, German, Spanish, Italian, Chinese, Japanese, Korean, Portuguese, Dutch, and Polish.
Instruction fine-tuning is a core aspect of this model, with the training pipeline avoiding both reinforcement learning and the use of synthetic data, as documented in the official announcement. The tokenizer deployed is the Tekken tokenizer, which leverages a 131,000-token vocabulary for effective text processing. The training corpus covers data up to October 2023, with subsequent instruction tuning designed to maximize generalist performance.
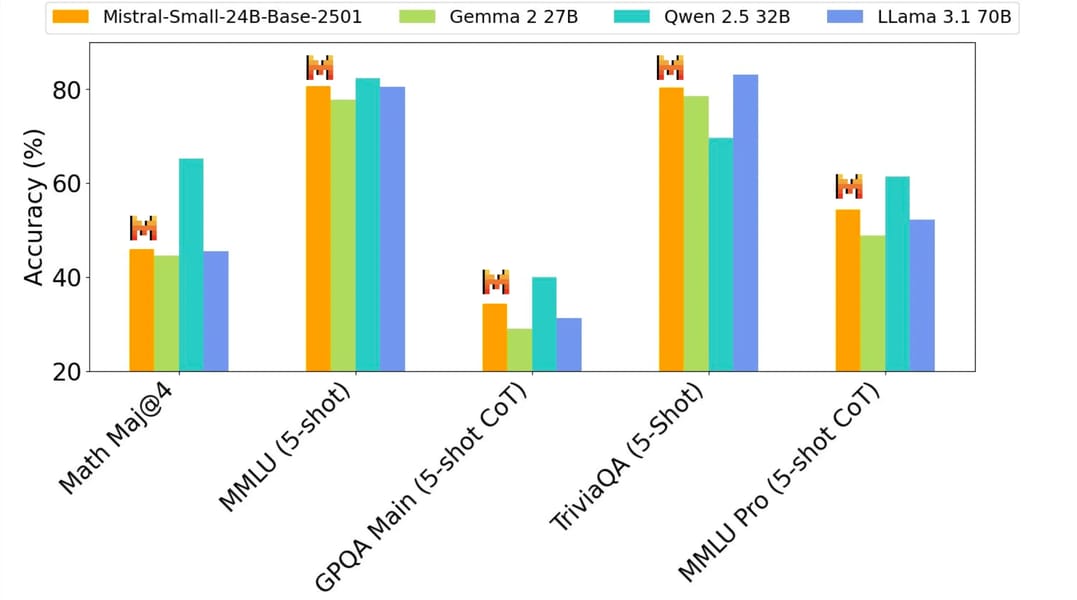
Bar chart showing comparative pretraining performance on multiple tasks, highlighting the metrics for Mistral-Small-24B-Base-2501 against [Gemma 2 27B](https://openlaboratory.ai/models/gemma-2-27b), [Qwen 2.5 32B](https://openlaboratory.ai/models/qwen-2_5-32b), and [Llama 3.1 70B](https://openlaboratory.ai/models/llama3_1-70b) across accuracy-based benchmarks.
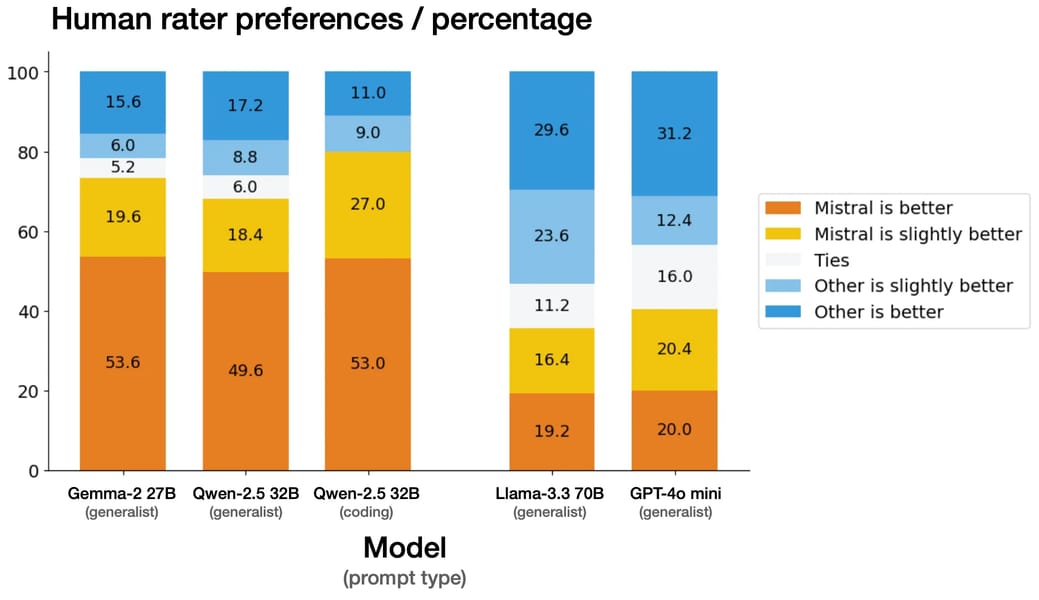
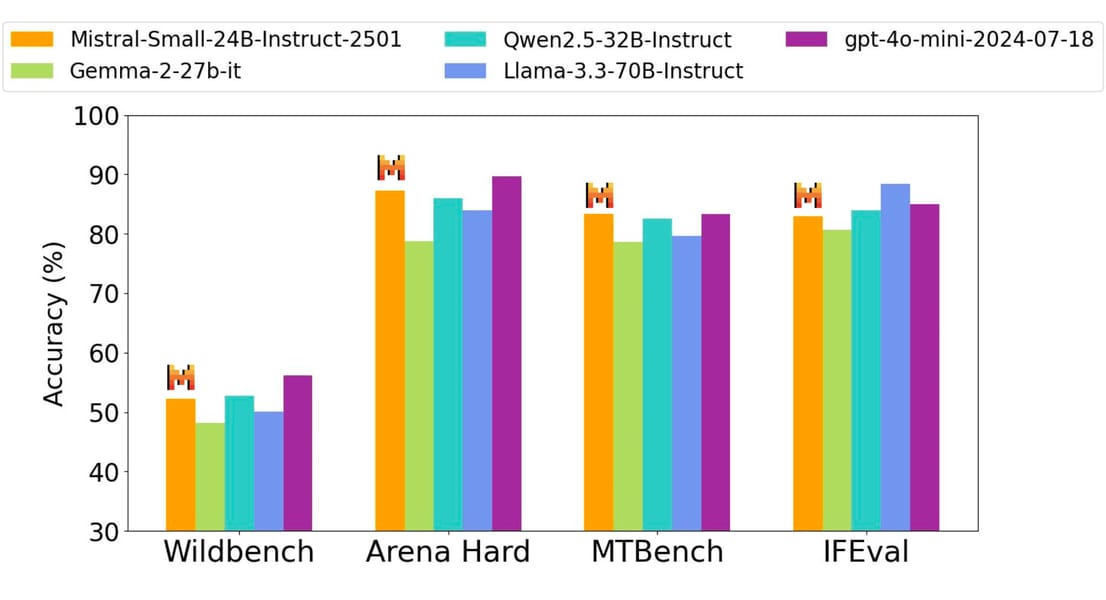
Mistral Small 3 demonstrates competitive performance according to both human evaluations and standardized public benchmarks. In human preference assessments conducted with external third-party vendors across 1,000+ prompts, responses from Mistral Small 3 were rated as preferred to those from other models, including Gemma-2 27B, Qwen-2.5 32B, Llama-3.3 70B, and GPT-4o-mini.
Human rater preferences exhibit competitive outcomes for Mistral Small 3, particularly against [Gemma-2 27B](https://openlaboratory.ai/models/gemma-2-27b) and [Qwen-2.5 32B](https://openlaboratory.ai/models/qwen-2_5-32b), as observed in this benchmark comparison.
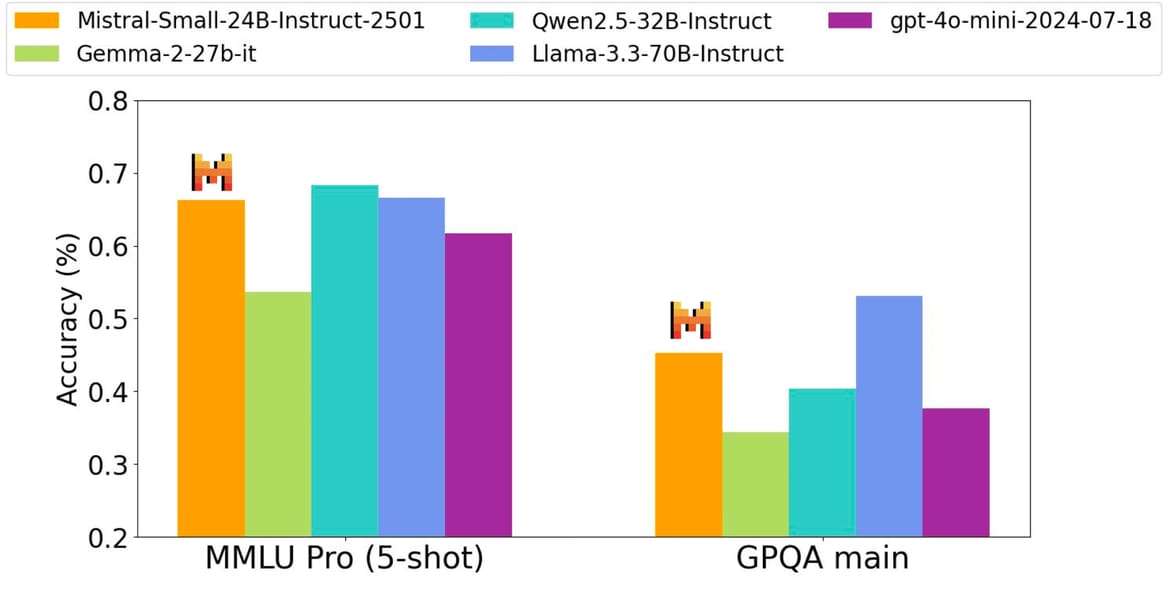
Quantitative benchmarks further support these findings. On the MMLU Pro (5-shot) and GPQA main benchmarks, Mistral Small 3 achieves scores comparable to or exceeding other models in its category:
The model's performance is visualized across general knowledge benchmarks MMLU Pro (5-shot) and GPQA main, compared to peer models.
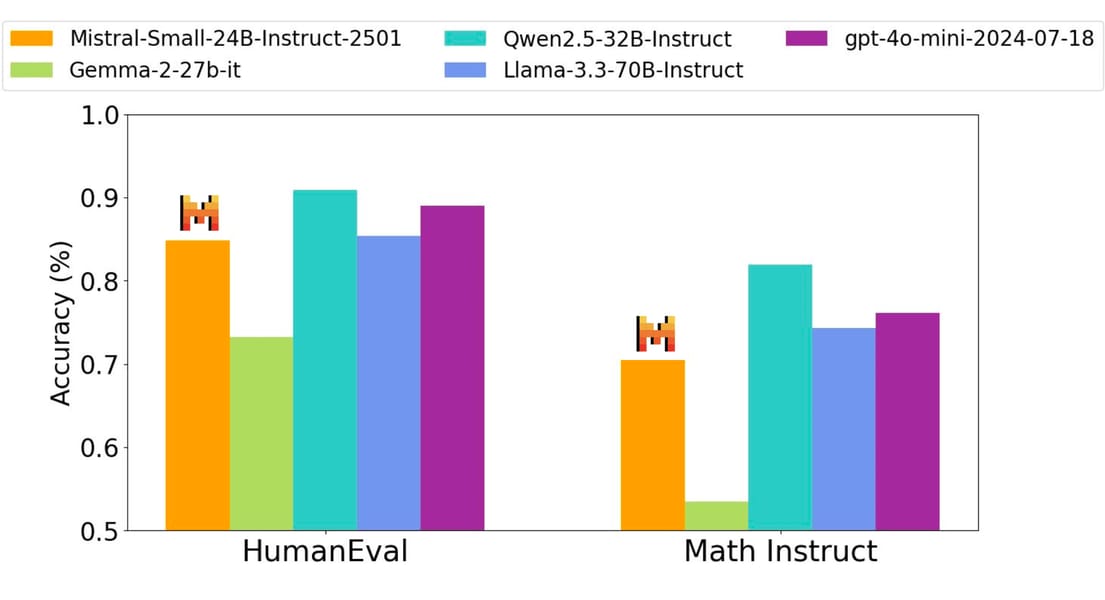
For code generation and mathematical reasoning, Mistral Small 3 demonstrates competitive results in HumanEval and Math Instruct evaluations:
Benchmarking results indicate performance by Mistral Small 3 in code and math tasks alongside models like [Llama-3.3 70B](https://openlaboratory.ai/models/llama3_3-70b) and [Qwen-2.5 32B](https://openlaboratory.ai/models/qwen-2_5-32b).
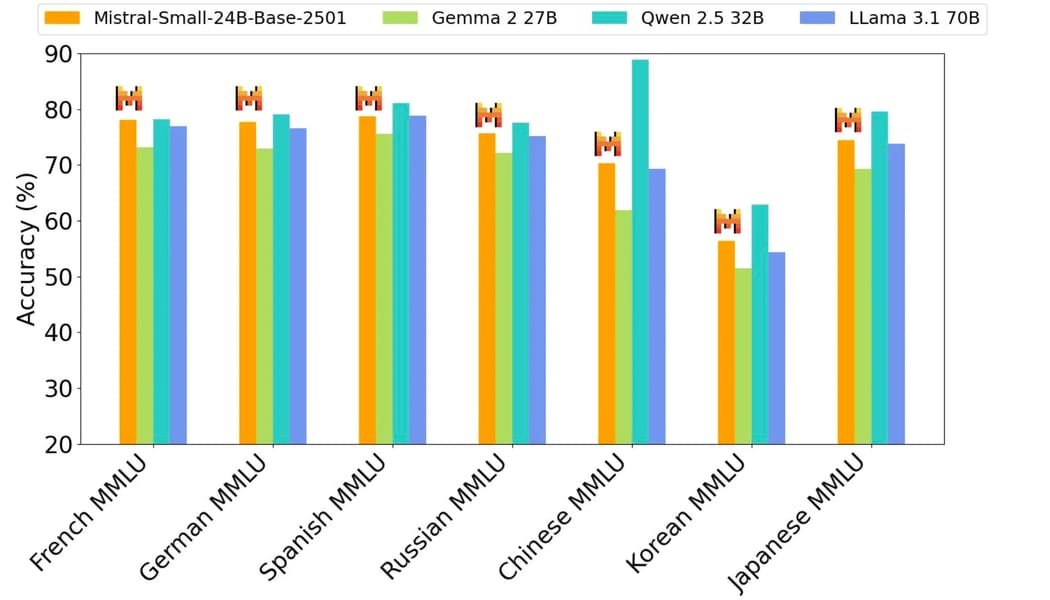
Additionally, multilingual capabilities are highlighted in evaluations on language-specific MMLU benchmarks:
The bar chart illustrates the multilingual MMLU benchmark results, where Mistral Small 3 exhibits consistent accuracy across several non-English languages.
Mistral Small 3 was optimized for low-latency inference, capable of producing up to 150 tokens per second. Its efficient architecture enables compatibility with a variety of deployment scenarios, including local and edge environments. When quantized, the model can be operated on single commercial GPUs or consumer hardware, making it suitable for privacy-sensitive and latency-critical applications. The model conforms to the V7-Tekken instruct template, supporting advanced system prompting and consistent instruction following.
The recommended inference temperature is 0.15 for production settings. System prompts can be formatted to ensure the model reliably disclaims uncertainty and requests clarification from users when required. For practical deployment, frameworks such as vLLM and Transformers are supported, as well as compatibility with Ollama for local inference.
Applications and Use Cases
Mistral Small 3 addresses a broad range of generative AI applications. Its capabilities including rapid instruction following, conversational engagement, and agentic workflows facilitate deployment as a foundation for virtual assistants, subject matter specialists through domain-specific fine-tuning, and automated function-calling agents within complex systems. The capacity for local inference supports scenarios with heightened privacy requirements, such as internal organizational workflows or industries handling sensitive data, including finance, healthcare, manufacturing, and customer service.
Limitations
While Mistral Small 3 provides generalist performance, it is not enhanced with reinforcement learning from human feedback (RLHF) or synthetic data, as noted in Mistral's technical release. This design choice positions the model in a specific segment of the generative model pipeline, focusing on reproducibility and interpretability.
Licensing and Model Access
Mistral Small 3 is distributed under the Apache 2.0 License, enabling both commercial and non-commercial modification and usage. This licensing paradigm aligns with Mistral AI’s stated intention to contribute general-purpose models to the open-source community. The model and associated resources are available via Mistral’s public repositories and documentation.