Launch a dedicated cloud GPU server running Laboratory OS to download and run AuraFlow v0.3 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Model Report
fal / AuraFlow v0.3
AuraFlow v0.3 is a 6.8 billion parameter, flow-based text-to-image generative model developed by fal.ai. Built on an optimized DiT architecture with Maximal Update Parametrization, it features enhanced prompt following capabilities through comprehensive recaptioning and prompt enhancement pipelines. The model supports multiple aspect ratios and achieved a GenEval score of 0.703, demonstrating effective text-to-image synthesis across diverse artistic styles and photorealistic outputs.
Explore the Future of AI
Your server, your data, under your control
AuraFlow v0.3 is a fully open-source, flow-based text-to-image generative model developed by fal.ai. It is the latest iteration in the AuraFlow series, building upon prior versions including AuraFlow v0.2 and v0.1. It incorporates architectural and prompt fidelity refinements compared to previous versions, for generating images from textual descriptions. This model is characterized by its support for a range of image aspect ratios, sophisticated prompt following, and scalability optimizations, all released under an open license to foster transparency and research collaboration.
Collage of six distinct images generated by AuraFlow v0.3, demonstrating its capabilities in diverse subjects and visual styles from detailed character portraits to dynamic scenes and artistic compositions.
AuraFlow v0.3 is built on a flow-based generative modeling approach, distinguishing itself from diffusion-based models commonly seen in the field. The developmental trajectory began with efforts to reimplement the MMDiT architecture, but empirical experiments led to an optimized design utilizing larger DiT encoder blocks. This improved both computational scalability and efficiency, yielding a 15% increase in model flops utilization at the 6.8 billion parameter scale.
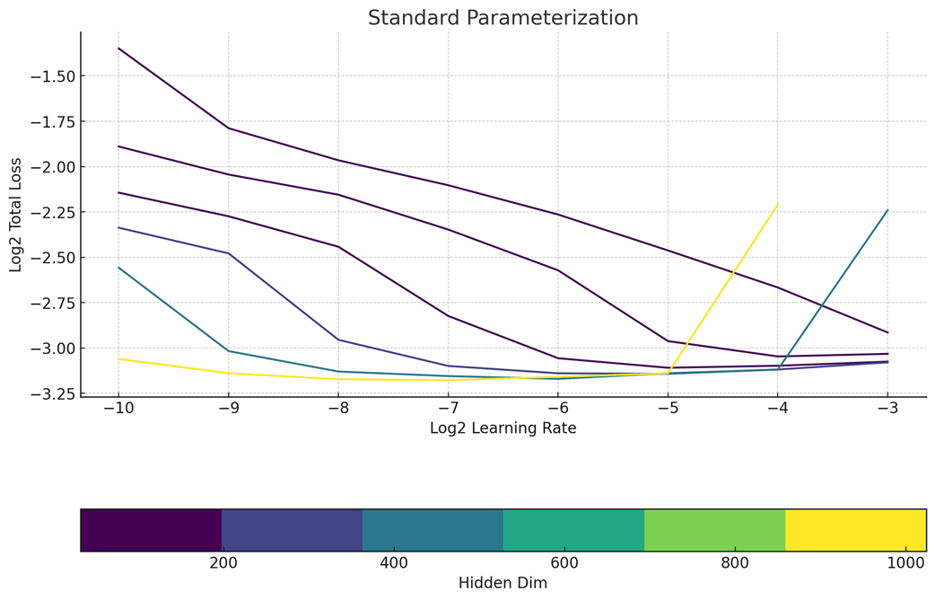
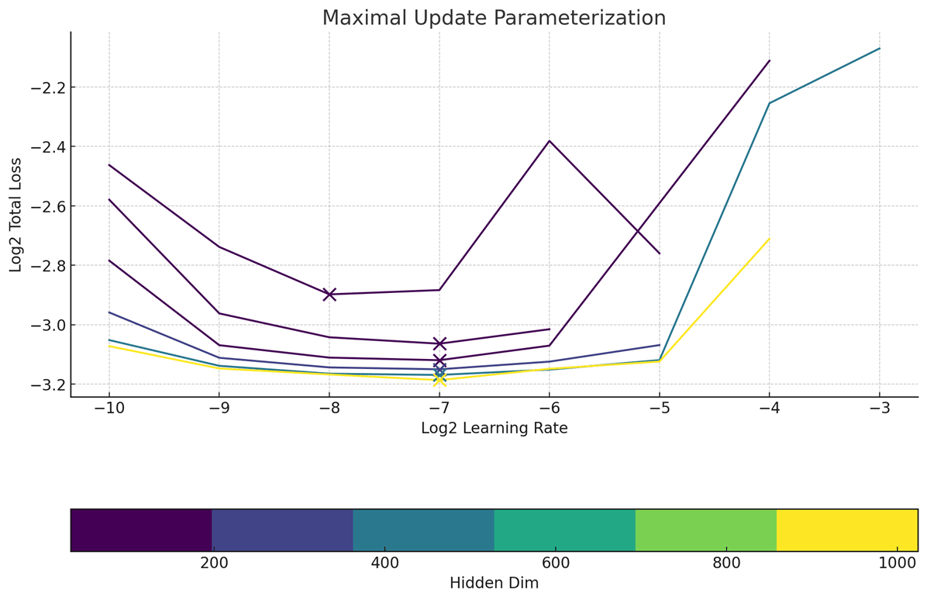
A major design focus was maximizing Model Flops Utilization (MFU). The use of torch.compile during training further optimized layer computation, contributing an additional 10–15% improvement in MFU depending on the training stage. The model employs Maximal Update Parametrization (muP) for predictable, scalable learning rate transfer across model sizes, demonstrating more consistency compared to standard parameterization approaches.
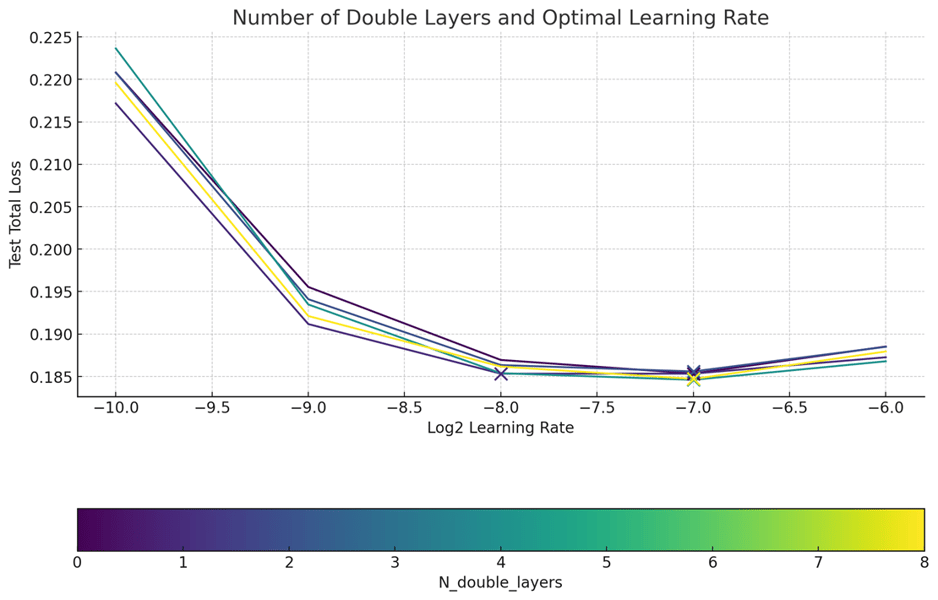
Line chart illustrating the relationship between model double layers, learning rate, and test loss, supporting architectural optimization during AuraFlow development.
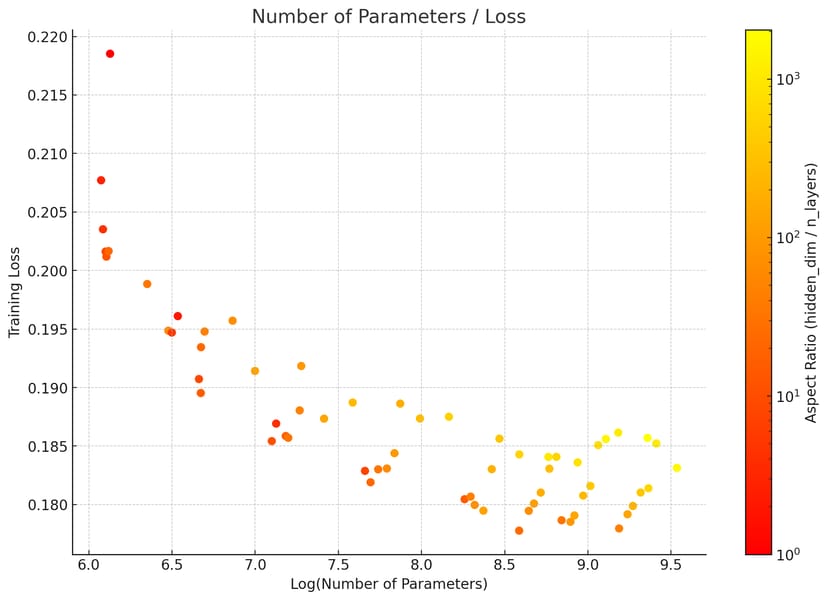
With a parameter count of 6.8 billion, AuraFlow v0.3 leverages a “fatter” design utilizing matrix multiplications divisible by 256. The team investigated optimal aspect ratios, ultimately adopting a 3072:36 hidden dimension to block ratio for this release, an approach inspired by scaling law research in generative modeling.
Scatter plot visualizing model configuration experiments; the color gradient represents how aspect ratio influences training loss for different parameter scales.
The AuraFlow v0.3 model was trained on a curated set of aesthetic datasets, further refined from those used in previous iterations. A characteristic of the training process is an extensive recaptioning pipeline: all training image captions were generated using either an in-house captioner or from reliably captioned external data, explicitly avoiding alt-texts. This methodology mirrors the approach seen in the DALL·E 3 workflow, aiming to maximize caption quality for improved prompt alignment.
To enhance the model’s ability to understand and follow intricate instructions, AuraFlow integrates a prompt enhancement pipeline. This system analyzes and expands input prompts into detailed captions, articulating object positions, colors, counts, and spatial relationships while preserving the original intent. The model translates complex textual cues into images with detail and accuracy.
AuraFlow response to a complex prompt: Includes a woman, grand piano, potted plant, and three cardboard boxes containing pink spheres, kittens, and citrus fruits—showcasing sophisticated prompt following.
The training process involved advanced distributed techniques, utilizing large-scale GPU fleets and distributed storage systems such as JuiceFS, allowing efficient streaming and staging of massive data volumes. The model underwent multi-stage pretraining—first on resolutions of 256x256, then 512x512 and 1024x1024, before final fine-tuning on varied aspect ratios. Overall, the model was trained from scratch over four weeks of compute, leveraging increased resources compared to earlier releases.
Performance Evaluation and Output Quality
AuraFlow v0.3's performance has been evaluated on standard benchmarks. In GenEval scores, the model achieved scores ranging from 0.63–0.67 during pretraining phases and reached 0.703 in the final release using the enhanced prompt pipeline, indicating prompt alignment and output quality in text-to-image generation. These metrics are consistent with the model's focus on prompt accuracy.
Example outputs include both fidelity to prompt and a variety of artistic styles, such as stylized illustrations, photorealistic scenes, and nuanced artistic compositions generated in response to detailed prompts.
Stylized illustration as generated by AuraFlow: A split-colored cat holding a martini glass, rendered in an Art Nouveau frame according to a detailed prompt.
For side-by-side visual benchmarking, users can compare AuraFlow generations with those from other models in an online comparison gallery.
Applications, Limitations, and Development
AuraFlow v0.3 is suitable primarily for text-to-image synthesis, serving research, artistic, and content generation applications. The open-source release encourages community experimentation, including finetuning, adaptation for workflows such as ComfyUI, and further model quantization or extension. The development team maintains an active stance on community feedback and iterative improvement.
Currently designated as a beta release, the model’s continued development aims to address limitations associated with compute-intensive training requirements and to improve usability for those with less powerful hardware through potential smaller model variants or mixture-of-expert architectures. The maintainers plan to supplement the release with more detailed technical documentation as the project evolves.
Model Family and Release History
AuraFlow v0.3 succeeds earlier models in the series, with each iteration incorporating architectural and data methodology refinements. The release timeline is as follows:
AuraFlow v0.1: The initial open-source release, establishing the foundation for subsequent work.
AuraFlow v0.2: An intermediary version with incremental improvements.
AuraFlow v0.3: Current release, offering greater fidelity, optimized architecture, and prompt-following enhancements.
Development has been driven by key contributors including @cloneofsimo and @isidentical, with support from the ComfyUI and HuggingFace communities. Related projects, such as Lavenderflow-v0, document earlier architectural experimentation in the context of generative transformer research.