Launch a dedicated cloud GPU server running Laboratory OS to download and run SD 1.5 Motion Model using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Automatic1111's legendary web UI for Stable Diffusion, the most comprehensive and full-featured AI image generation application in existence.
Model Report
conrevo / SD 1.5 Motion Model
The SD 1.5 Motion Model is a core component of the AnimateDiff framework that enables animation generation from Stable Diffusion 1.5-based text-to-image models. This motion module uses a temporal transformer architecture to add motion dynamics to existing image generation models without requiring retraining of the base model. Trained on the WebVid-10M dataset, it supports plug-and-play compatibility with personalized T2I models and enables controllable video synthesis through text prompts or sparse input controls.
Explore the Future of AI
Your server, your data, under your control
The SD 1.5 Motion Model is a core component of the AnimateDiff framework, enabling animation generation from existing text-to-image (T2I) models based on Stable Diffusion 1.5. This model is implemented as a standalone motion module (such as mm_sd_v15.ckpt or v3_sd15_mm.ckpt) and serves to extend still-image diffusion models with learned motion dynamics, requiring minimal or no specific tuning of the original base model. Developed and released under the Apache-2.0 license, the SD 1.5 Motion Model broadens the creative capacity of T2I models by supporting the generation of coherent video sequences from text prompts or controlled inputs.
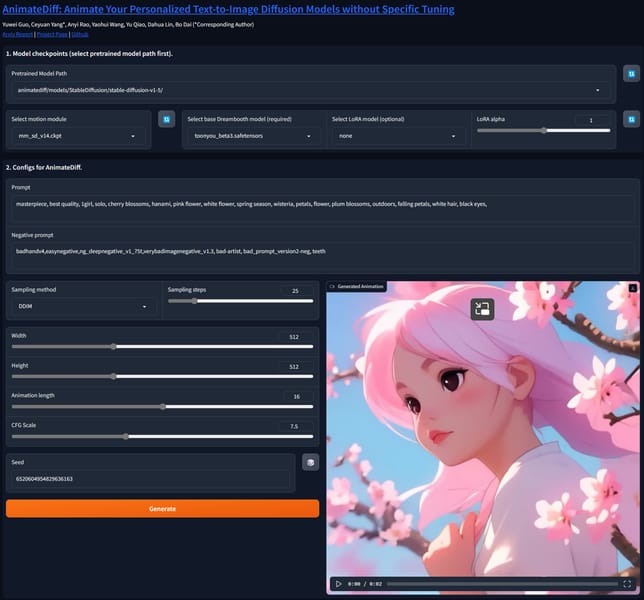
Screenshot of the AnimateDiff interface, demonstrating user input parameters and an anime-style animated output generated by the SD 1.5 Motion Model.
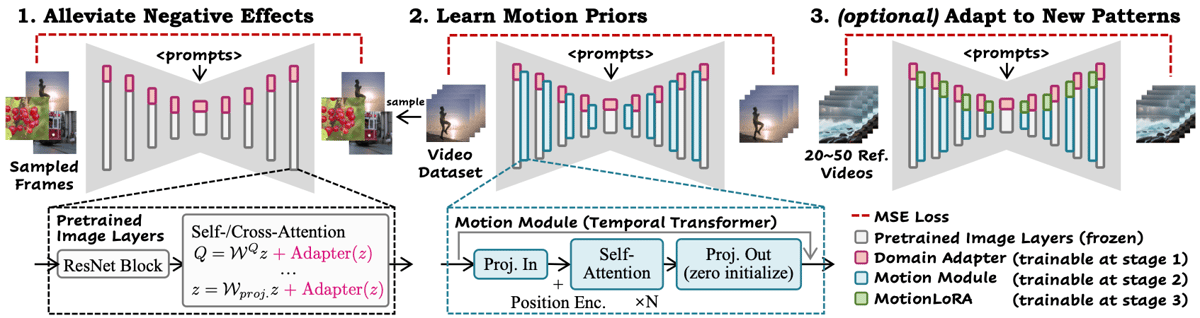
The architecture of the SD 1.5 Motion Model is grounded in the AnimateDiff framework's modular design, facilitating the addition of motion to T2I models without retraining the image generation backbone. The training pipeline comprises three distinct stages, as detailed in the AnimateDiff technical report and project documentation:
Diagram outlining AnimateDiff's three-stage training: domain adaptation, motion prior learning, and optional MotionLoRA fine-tuning, along with the structure of key model components.
The first stage involves training a LoRA-based domain adapter to minimize visual distribution gaps between T2I image data and real-world video data. This domain adapter is designed to handle dataset-specific artifacts such as watermarks that can negatively affect motion learning.
In the second stage, the motion module, implemented as a temporal transformer, is added to the frozen T2I model. The motion module is initialized so that it does not affect image generation outputs at the start of training, ensuring stable integration. Its architecture uses self-attention and positional encoding along the temporal (time) dimension, allowing it to propagate motion information across frames while maintaining per-frame image fidelity.
An optional third stage introduces MotionLoRA, a lightweight, efficient fine-tuning method that further adapts the motion module for specific motion patterns—such as distinct camera moves—using a relatively small number of reference videos.
The entire process is designed to separate visual content learning from motion learning, enabling the direct integration of control-oriented techniques, such as ControlNet, for fine-grained video synthesis.
Technical Capabilities
The SD 1.5 Motion Model is engineered for plug-and-play compatibility with a broad range of Stable Diffusion 1.5-based T2I models. It operates by learning transferable motion priors from video datasets, which can be applied to any compatible, personalized T2I model without degrading the diversity or fidelity of the underlying model. This approach supports the animation of diverse visual domains, including both cartoon and photorealistic styles, as documented in project resources.
The model's architecture allows for fine-grained and controllable video generation. By using separated visual and motion priors, the AnimateDiff framework enables users to leverage content control mechanisms, such as ControlNet, without additional extensive training. For example, the integration of SparseCtrl encoders makes it possible to guide animation based on sparse inputs, including RGB images or line drawings, as demonstrated in AnimateDiff v3.
MotionLoRA further extends control, supporting domain-specific adaptations and camera motion effects with only minimal storage and training data. This flexibility allows for composed motion effects in a parameter-efficient manner.
Training Data and Evaluation
The SD 1.5 Motion Model's motion module is trained primarily on the WebVid-10M dataset, which comprises large-scale real-world video content. The training methodology involves an initial stage of domain adaptation, followed by supervised learning of motion priors while freezing the image model and adapter parameters. For specialization, additional fine-tuning via MotionLoRA leverages small numbers of reference videos, enabling efficient adaptation to novel motion types.
Quantitative evaluations have benchmarked AnimateDiff against other contemporary text-to-video models, including Text2Video-Zero and Tune-a-Video, as well as commercial models like Gen-2 and Pika Labs. According to the AnimateDiff ICLR '24 paper, the method demonstrated superior or competitive performance in metrics such as motion smoothness and domain similarity, and robust results in user preference studies. Notably, the v2 motion module, trained at larger resolutions and batch sizes, shows improved motion quality and diversity in its outputs.
Applications and Use Cases
The principal application of the SD 1.5 Motion Model is the animation of personalized T2I models, transforming still image generators into controllable video creators. Its text-driven interface enables the direct generation of animated sequences aligned with user prompts. Additionally, the system supports more advanced workflows, such as shot-type control via MotionLoRA and animation guidance using sparse input controls as enabled by the SparseCtrl module.
The AnimateDiff framework facilitates animation spanning artistic cartoons, stylized digital art, and photorealistic rendered scenes. Additionally, the model accommodates animation interpolation tasks, provided that style alignment is maintained by sourcing frames from the same base image model.
Limitations and Known Issues
Despite its versatility, the SD 1.5 Motion Model presents some limitations. Users may observe minor flickering artifacts in generated videos—a common challenge in diffusion-based video synthesis, as reported in the project’s documentation. While the model excels in animating T2I models, it is not explicitly optimized for generic text-to-video generation; accordingly, overall visual quality may vary in such applications compared to systems trained specifically for that purpose.
In scenarios such as image animation or interpolation, consistent visual style is best achieved by using images from the same T2I source model, as discrepancies may lead to noticeable style shifts. Finally, although MotionLoRA is designed for efficiency, very limited fine-tuning data (e.g., fewer than 10 videos) can result in significant quality degradation, as the model may overfit to input textures rather than general motion dynamics.
Model Family and Releases
The SD 1.5 Motion Model belongs to a larger family of AnimateDiff motion modules. Earlier versions, such as the SD 1.4 Motion Model, targeted prior generations of Stable Diffusion, while the AnimateDiff SDXL-beta module extends compatibility to Stable Diffusion XL, supporting high-resolution video output.
The AnimateDiff framework has undergone multiple release cycles, with the initial v1 released in July 2023, followed by v2 in September 2023 (introducing improved motion quality and MotionLoRA adaptation), and v3 in December 2023, which added domain adapter LoRA and SparseCtrl inputs for enhanced content control.
Additional Resources
For further reading, technical details, and access to model weights, the following resources are recommended: