Launch a dedicated cloud GPU server running Laboratory OS to download and run ControlNet SD 1.5 Canny using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
lllyasviel / ControlNet SD 1.5 Canny
ControlNet SD 1.5 Canny is a conditioning model for Stable Diffusion 1.5 that uses Canny edge detection to control image generation structure. Part of the ControlNet 1.1 family, it processes edge maps to guide composition while preserving text-prompt flexibility. The model features improved training data quality, enhanced robustness, and supports multi-ControlNet workflows for complex conditioning scenarios.
Explore the Future of AI
Your server, your data, under your control
ControlNet SD 1.5 Canny is a model within the ControlNet 1.1 family, designed to condition image generation in Stable Diffusion 1.5 using Canny edge maps as control signals. The model leverages Canny edge detection—a classic computer vision algorithm that highlights image boundaries—to influence the composition and structure of generated outputs, facilitating precise and repeatable control over the creative process. ControlNet SD 1.5 Canny builds upon its predecessor, offering improvements in robustness and visual quality by refining its data pipeline and training protocol.
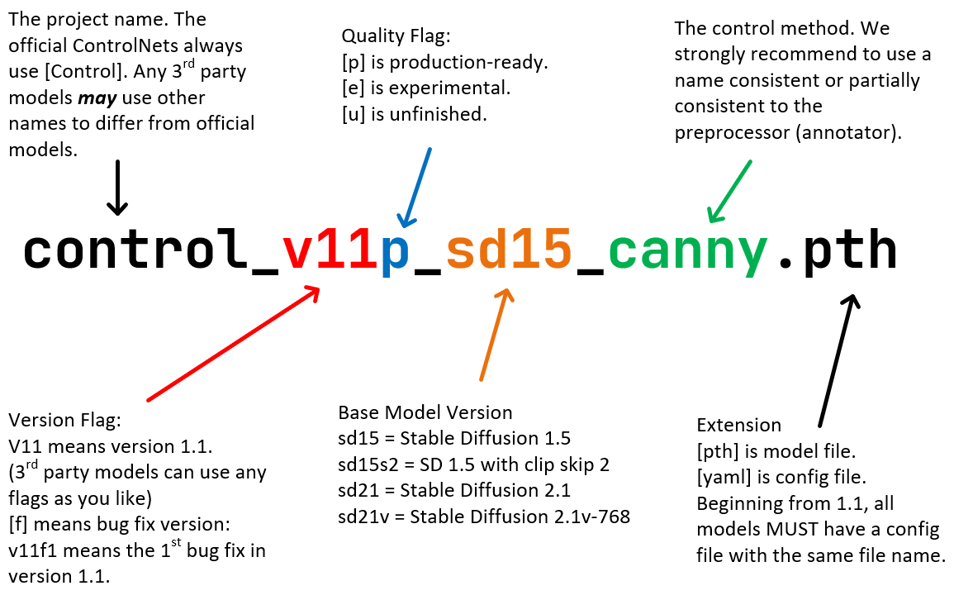
Standard ControlNet Naming Rules (SCNNRs) breakdown, shown with the model file 'control_v11p_sd15_canny.pth' as an example.
The underlying architecture of ControlNet 1.1, including the Canny variant, retains the core structure of earlier releases. The system is built around the integration of ControlNet's auxiliary encoding with the Stable Diffusion 1.5 U-Net backbone, facilitating image generation that is explicitly guided by structural information extracted via Canny edge maps. During inference, the ControlNet Encoder output is processed with a global average pooling operation before fusion with the main diffusion U-Net latent space, a design consideration outlined in the official ControlNet-v1-1-nightly repository.
A critical operational detail is that ControlNet is integrated on the conditional branch of the classifier-free guidance (CFG) mechanism in Stable Diffusion, ensuring that the edge-derived conditions robustly influence the generation process without affecting unconditional guidance. This architecture allows the user to exert granular control over image composition while maintaining the flexibility of text-conditioned generation.
The ControlNet 1.1 framework includes support for "Multi-ControlNet," where multiple ControlNet models can be used in tandem, enabling combinations of edge, pose, segmentation, and other modalities. This functionality is accessible in popular Stable Diffusion user interfaces and facilitates complex conditioning scenarios, as discussed in the main ControlNet documentation.
Training Data and Methodology
ControlNet SD 1.5 Canny underwent extensive improvements in its training dataset compared to its 1.0 predecessor. The data curation process prioritized the removal of duplicated grayscale human images—previously found to bias results toward grayscale generations—alongside thorough filtering of low-quality, blurry, or JPEG-artifacted samples. Furthermore, errors in paired prompts, stemming from processing bugs, were systematically resolved, resulting in higher-quality image-text associations during training. Details of these changes are described in the project documentation on HuggingFace.
The training process utilized a large compute budget, employing eight NVIDIA A100 80GB GPUs and a batch size of 256 over three days. This enabled robust convergence and improved generalization, as evidenced by performance benchmarks and output quality. The training procedure not only resumed weights from the earlier Canny 1.0 model but also incorporated random Canny edge thresholding for input diversities, further enhancing downstream robustness.
Model Performance and Output Characteristics
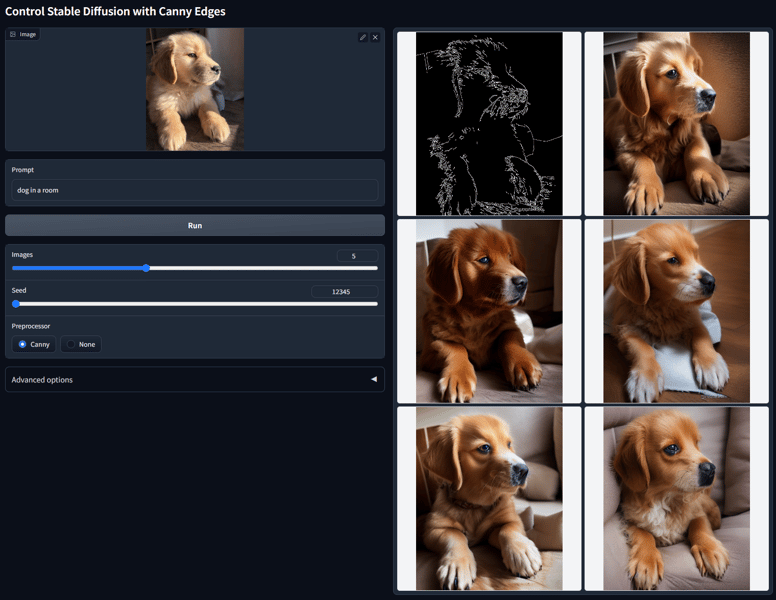
Qualitative and batch testing of ControlNet SD 1.5 Canny demonstrates marked improvements in both consistency and fidelity compared to previous versions. The model is capable of generating images that closely align with the structure established by input Canny edge maps while allowing rich variations in style and detail via text prompts. Results from systematic tests, including the frequently referenced "dog in a room" scenario, illustrate the model's proficiency at preserving spatial layout and prominent edges while synthesizing visually coherent outputs.
Batch outputs of the 'dog in a room' prompt with a Canny edge map for conditioning. The model generates variations that are structurally consistent with the detected edges.
The architecture also supports the combination of multiple ControlNet modules, enhancing possibilities for creative compositing. As a result, users are able to generate complex scenes or character variations with fine-grained structural and stylistic control, which has been demonstrated in various multi-ControlNet scenarios shared in the open-source ControlNet repository.
Generated outputs using both Canny (edge) and Shuffle (content) conditions, illustrating diverse results with consistent global structure.
ControlNet SD 1.5 Canny is primarily utilized for tasks where preserving or interpreting visual structure is essential. By conditioning image generation on edge maps, it has become a tool of choice for applications such as sketch-to-image synthesis, controlled style transfer, and content-aware modification. Artists and developers use the model to transform Canny edge-detected sketches or extracted edge maps from photographs into fully rendered outputs matching textual prompts, while reliably maintaining underlying composition.
The model further supports integration into multi-module workflows, enabling comprehensive scene control when combined with other conditioning sources such as pose estimation, segmentation, or depth maps. The supported batch inference and randomization features facilitate the rapid generation of diverse outputs from a single edge map source.
In professional and experimental contexts, this model enables workflows such as controlled data augmentation, rapid prototyping of concept art, and forensic applications where structural preservation from original images is required.
Limitations and Related Models
While ControlNet SD 1.5 Canny offers notable improvements in visual fidelity and robustness, certain limitations remain. For instance, when handling scenes with ambiguous or low-quality edge detection, the model's outputs may deviate from intended semantics. Additionally, some features—such as tiled upscaling or specific anime-trained variants—require auxiliary files or updated user interface extensions, as noted in the repository's guidance.
The broader ControlNet 1.1 family introduces several other conditioning modalities built on the same architecture, including models for depth map extraction, normal maps, semantic segmentation, scribble input, and more. Each variant is designed for specific structural signal integration, following the Standard ControlNet Naming Rules to ensure clarity in configuration and interoperability.
Licensing and Access
ControlNet SD 1.5 Canny, like its family counterparts, is released in a public repository, facilitating open research and reproducibility. While the specific license is not explicitly stated in the repository, public distribution is maintained on GitHub and HuggingFace, providing access to model weights, configuration files, and related resources. Users are advised to consult the repository for definitive licensing information before redistribution or derivative works.