Note: Stable Cascade Stage A weights are released under a Stability AI Non-Commercial Research Community License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Cascade Stage A using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
stabilityai / Stable Cascade Stage A
Stable Cascade Stage A is a vector quantized generative adversarial network encoder that compresses 1024×1024 pixel images into 256×256 discrete tokens using a learned codebook. With 20 million parameters and fixed weights, this component serves as the decoder in Stable Cascade's three-stage hierarchical pipeline, reconstructing high-resolution images from compressed latent representations generated by the upstream stages.
Explore the Future of AI
Your server, your data, under your control
Stable Cascade is a text-to-image generative model developed by Stability AI, based on the Würstchen architecture. It utilizes a three-stage hierarchical pipeline with a high compression factor, which can lead to faster inference and more resource-efficient training while maintaining output quality. Introduced in February 2024, this model serves as a research preview and is released under a non-commercial license, encouraging academic and creative exploration while maintaining restrictions on commercial deployment.
A collage of diverse scenes, characters, and styles, showcasing the breadth of output generated by Stable Cascade.
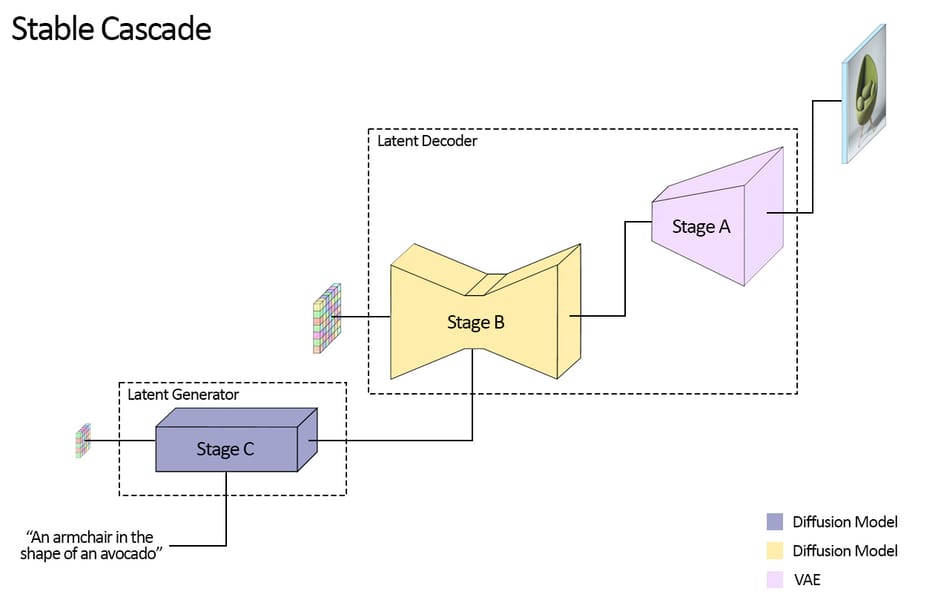
Stable Cascade employs a three-stage pipeline—Stages A, B, and C—each fulfilling specific roles in compressing, generating, and decoding images. Stage A is a vector quantized generative adversarial network (VQGAN) encoder, taking high-resolution images (1024×1024 pixels) and reducing them to 256×256 discrete tokens using a learned codebook. With 20 million parameters, Stage A's compactness and fixed weights facilitate efficient deployment and support for rapid downstream tasks.
Stage B further compresses the representation by leveraging a latent diffusion model conditioned on semantic information, shrinking the token grid to a 24×24 spatial size, thus achieving a 42-fold reduction in data dimensionality relative to pixel space. The semantic compressor within Stage B incorporates an EfficientV2 (S) backbone, pretrained on ImageNet1k, providing high-precision semantic mappings to guide reconstruction.
Stage C is the principal text-conditional generator, synthesizing images from textual prompts within the compressed latent space. It operates with multiple ConvNeXt blocks and is trained directly on text-image pairs using CLIP-H embeddings for prompt conditioning. The generative process runs in reverse: Stage C creates coarse latents, Stage B refines these, and Stage A decodes the compressed signal back into a high-resolution image. This strategic separation minimizes computational demands while retaining high-quality output, as detailed in the Würstchen research paper.
Diagram illustrating Stable Cascade's three-stage architecture: Stage C (text-to-latent generator), Stage B (latent refinement), and Stage A (image decoder).
Stable Cascade is trained on a subset of the LAION-5B dataset, employing rigorous filtering for quality and safety. The final training set comprises approximately 103 million unique image-text pairs, or roughly 1.78% of LAION-5B after exclusion of watermarked, low-quality, or potentially harmful content. This stringent approach addresses ethical and legal risks associated with large-scale web data, as described in project documentation regarding responsible dataset curation.
The training process is staged and sequential. Stage A is trained as a standalone autoencoder; Stage B subsequently learns to reconstruct the intermediate latent spaces of Stage A, and Stage C is finally trained as a text-conditional generator. Training objectives incorporate cosine noise schedules and p2 loss weighting, incentivizing robustness at higher noise levels, while classifier-free guidance is implemented by occasionally dropping text conditioning to diversify outputs.
Text conditioning throughout the pipeline uses CLIP-H text embeddings, and semantic information in Stage B is encoded via a backbone updated during training for enhanced latent precision. The non-iterative inference structure and high compression rates collectively reduce the total compute footprint, making finetuning and extension feasible even on consumer hardware.
Capabilities and Supported Features
Stable Cascade supports a variety of tasks beyond simple text-to-image generation, leveraging its modular design for flexibility in research and creative workflows.
Image variation is facilitated through CLIP embedding extraction from user-provided images, allowing the model to generate diverse stylistic or conceptual renditions while preserving core visual structure.
Example of the image variation feature; multiple stylized renditions of human busts with futuristic VR headsets. Prompt: n/a (input image variation task)
Image-to-image generation is also supported, where noise is added to a supplied image and then used as the starting point for novel image creation, preserving structure while allowing stylistic changes.
Utilizing image-to-image generation, Stable Cascade can create diverse versions of a concept, demonstrated here by varied human riders on large rats. Prompt: n/a (base image plus stylistic variation)
Furthermore, Stable Cascade integrates ControlNet-based extensions, such as inpainting and outpainting—where regions of an image can be filled or expanded according to a textual prompt—and structural controls like the Canny Edge interface, which enables sketch-to-image translation.
Stable Cascade inpainting: filling masked regions with new content guided by a prompt, such as generating dog heads to replace a cat's head on a beach.
The architecture’s modularity allows Stage C to be finetuned independently—enabling efficient customization and support for research extensions such as LoRA and ControlNet.
Performance, Efficiency, and Evaluation
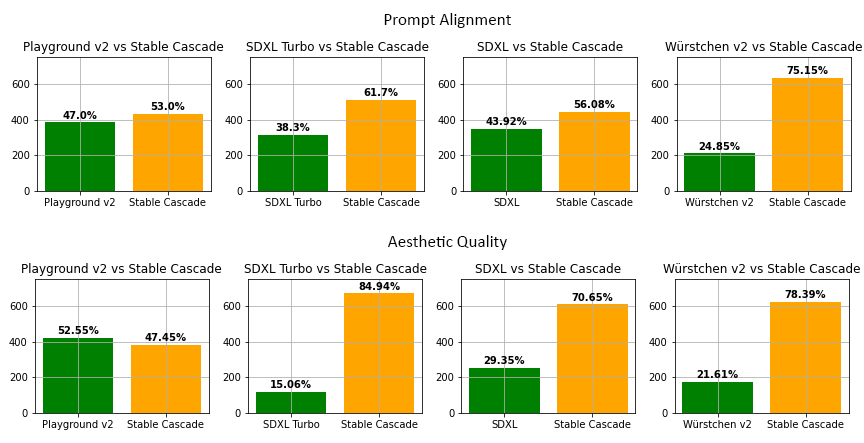
Stable Cascade demonstrates strong prompt alignment and consistent aesthetic quality according to human preference evaluations. In comparative tests against models such as Playground v2, SDXL, SDXL Turbo, and Würstchen v2, Stable Cascade maintained competitive results in both prompt fidelity and visual scoring, as documented in human evaluations (see comprehensive evaluation chart).
Stable Cascade achieves strong performance in prompt alignment and aesthetic quality versus other alternative models.
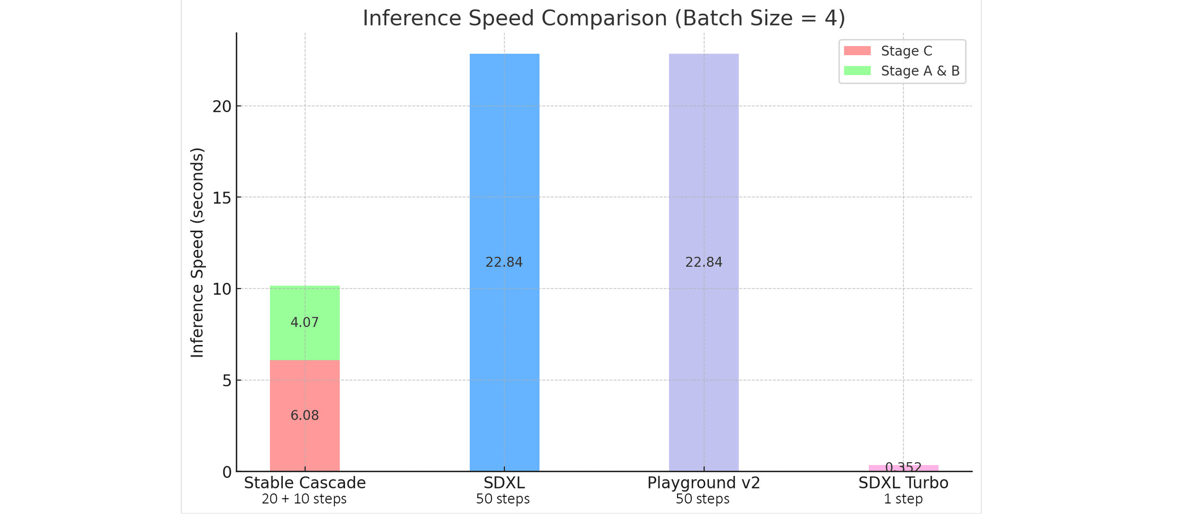
Component compression is substantial—compressing images by a factor of 42 (from 1024×1024 to 24×24)—which enables faster inference and reduces training cost. Empirical measurements suggest an over twofold reduction in inference time compared to models such as SDXL, while maintaining comparable or improved output quality. Specifically, Stable Cascade's inference for batch size four totals approximately 10.15 seconds, in contrast to 22.84 seconds for SDXL, as shown in benchmark visualizations (see model speed comparison).
Inference speed comparison (batch size = 4): Stable Cascade reduces latency relative to SDXL and Playground v2.
Quantitative evaluation metrics on COCO-30K further affirm the model's capabilities. Stable Cascade achieves a Fréchet Inception Distance (FID) of 23.6 and an Inception Score (IS) of 40.9, indicating favorable aesthetic and semantic correspondence. A slightly higher FID compared to some contemporaries (such as Stable Diffusion 2.1) reflects a tendency toward smoother visuals rather than increased artifacting or semantic drift.
In terms of resource efficiency, training Stage C required 24,602 A100-GPU hours—representing an eightfold reduction in compute compared to Stable Diffusion 2.1’s 200,000 GPU hours. This architectural efficiency is directly attributable to the drastically compressed latent space and decoupled stage-wise training.
Licensing, Limitations, and Use Cases
Stable Cascade is available strictly for non-commercial use under a custom research license, with commercial deployment not permitted. Users are expected to comply with the Stability AI Acceptable Use Policy, including restrictions on harmful or unethical applications.
The model assists in research-oriented tasks involving generative modeling, prompt analysis, and exploration of controllable image synthesis in educational and creative contexts. Its aggressive filtering results in a distinctive output style, while its abstracted composition may present challenges for fine-grained tasks such as text rendering and precise object counting. Further, the lossy compression inherent to the autoencoding stage and the decoupled pixel-space decoding may limit fidelity on extremely fine details.
Stage-wise modularity supports customization and experimentation for model probing, bias analysis, and safe deployment research. The architecture is also designed to enable efficient adaptation via extensions such as LoRA and ControlNet.