Launch a dedicated cloud GPU server running Laboratory OS to download and run Playground v2 Aesthetic using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Automatic1111's legendary web UI for Stable Diffusion, the most comprehensive and full-featured AI image generation application in existence.
Model Report
playgroundai / Playground v2 Aesthetic
Playground v2 Aesthetic is a latent diffusion text-to-image model developed by playgroundai that generates 1024x1024 pixel images using dual pre-trained text encoders (OpenCLIP-ViT/G and CLIP-ViT/L). The model achieved a 7.07 FID score on the MJHQ-30K benchmark and demonstrated a 2.5x preference rate over Stable Diffusion XL in user studies, focusing on high-aesthetic image synthesis with strong prompt alignment.
Explore the Future of AI
Your server, your data, under your control
Playground v2 Aesthetic Model is a diffusion-based text-to-image generative model developed by Playground, designed to produce high-aesthetic images at a resolution of 1024x1024 pixels. Utilizing a latent diffusion framework and dual pre-trained text encoders—OpenCLIP-ViT/G and CLIP-ViT/L—the model focuses on synthesizing visually compelling images aligned with user prompts. Playground v2 was extensively benchmarked for both subjective user preference and quantitative image quality, providing a detailed view of its capabilities in comparison to established models such as Stable Diffusion XL. Its release is accompanied by visual benchmarks, curated datasets, and comprehensive documentation, supporting its role as an open research model for high-fidelity image generation.
A collage illustrating output diversity and detail produced by Playground v2, featuring a range of subjects from animals and vehicles to portrait and fantasy scenes.
Playground v2 is based on the latent diffusion approach to text-to-image synthesis, inheriting several architectural choices from Stable Diffusion XL. At its core, the model utilizes two fixed, pre-trained text encoders—OpenCLIP-ViT/G and CLIP-ViT/L—enabling robust textual prompt interpretation and more precise image-text alignment. The generation pipeline projects input text into a latent space, where iterative denoising produces an image sample with high resolution (1024x1024 pixels).
This architectural configuration allows Playground v2 to efficiently generate images that reflect both prompt semantics and high aesthetic quality. The dual-encoder setup contributes to accurate prompt grounding and nuanced visual characteristics in generated outputs, as evidenced by both human preference studies and automated benchmarks, as detailed on the Playground v2 model's Hugging Face page.
Training Datasets and Benchmarking
Playground v2 was developed and trained from scratch by the Playground research team. Although specific training datasets are not publicly enumerated, the evaluation pipeline leverages the MJHQ-30K benchmark dataset, curated for high-quality aesthetic evaluation. MJHQ-30K comprises 30,000 high-resolution images distributed across 10 categories—such as animals, fashion, food, and landscapes—ensuring both visual quality and strong image-text correspondence as validated by aesthetic and CLIP scores.
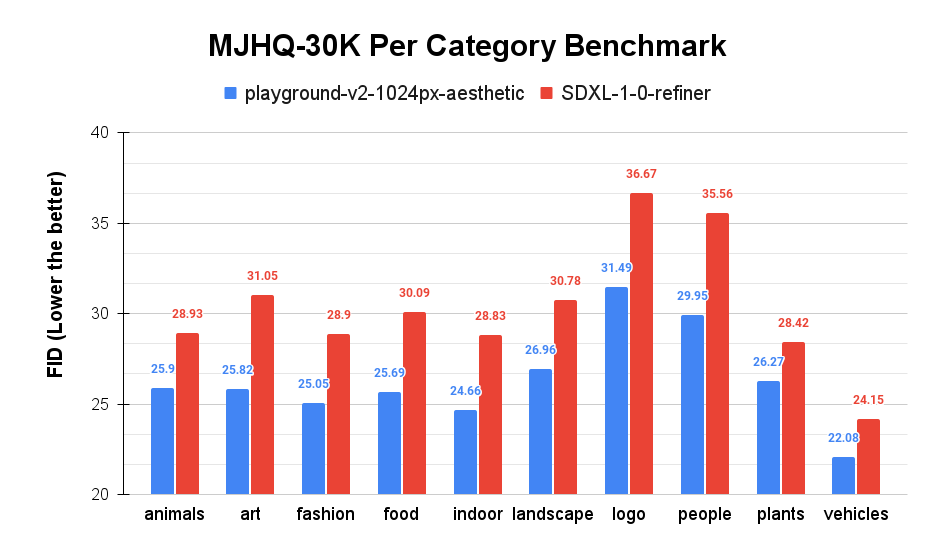
Performance benchmarking includes both automated and user study components. The model's aesthetic fidelity and prompt accuracy were evaluated using the Fréchet Inception Distance (FID) metric across all MJHQ-30K categories. Additionally, large-scale human preference studies were conducted using prompts from diverse sources, including the Google Research PartiPrompts, comparing Playground v2 outputs to those generated by Stable Diffusion XL.
Per-category FID scores on the MJHQ-30K benchmark, demonstrating the lower FID scores of Playground v2 compared to SDXL-1-0-refiner across most evaluated categories.
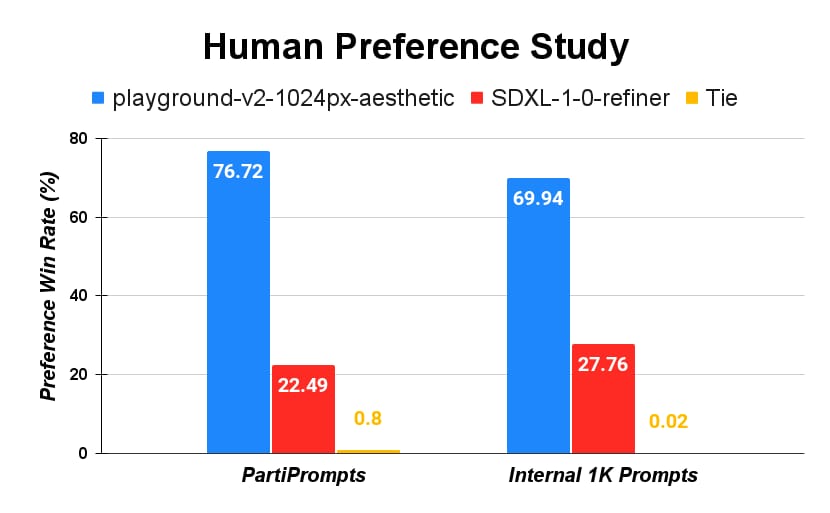
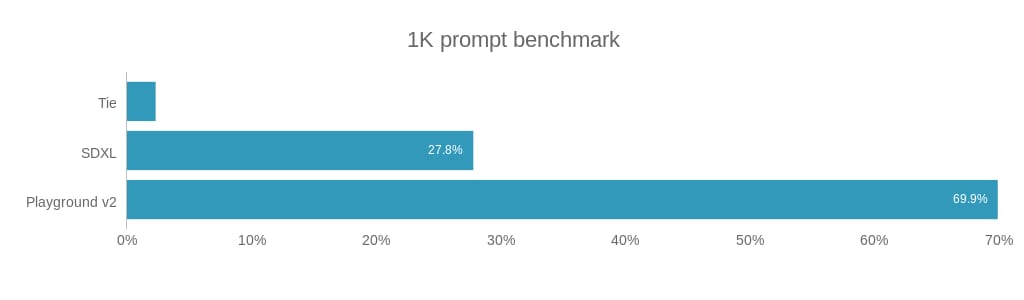
The evaluation of Playground v2 indicated gains in both subjective preference and objective image quality relative to previous models. In head-to-head user studies, involving over 2,600 prompts and thousands of participants, images created by Playground v2 were selected approximately 2.5 times more often than those of Stable Diffusion XL, considering both aesthetics and text alignment. For instance, on PartiPrompts, Playground v2 achieved a 76.7% user preference rate compared to 22.5% for Stable Diffusion XL.
An example output from Playground v2 demonstrating its ability to render stylized, character-focused artwork.
Quantitatively, the model achieved a global FID of 7.07 on the MJHQ-30K, outperforming SDXL-1-0-refiner, which scored 9.55 on the same benchmark. Playground v2 also maintained a lower FID across all ten MJHQ-30K categories, including prominent improvements in challenging classes like "people" and "fashion." Evaluations on the MSCOCO14 dataset indicated that intermediate Playground v2 models—at 256px and 512px resolution—either matched or surpassed Stable Diffusion XL in FID and CLIP scores, suggesting consistent architectural behavior throughout training stages, as detailed in the Playground Blog's Playground v2 Announcement.
User preference study comparing Playground v2 and SDXL-1-0-refiner, illustrating the higher selection rate for Playground v2 across two major prompt datasets.
Playground v2 is engineered to generate aesthetically pleasing and diverse images from natural language prompts. Its outputs span a variety of visual domains, including highly realistic renderings, stylistic portraiture, and complex scene synthesis. Example applications include image generation for artistic purposes, content illustration for digital media, and contributing to text-to-image research through the release of training checkpoints at multiple resolutions.
A detailed synthetic image of a Jeep in a snowy, mountainous landscape generated by Playground v2. Prompt: 'An orange Jeep driving through snow in the mountains at twilight.'
Cozy indoor winter scene synthesized by Playground v2, demonstrating scene composition and lighting. Prompt: 'A festive wooden table covered in star and gingerbread-man cookies in front of a snowy window.'
A stylized, synthetic portrait generated by Playground v2 showing a bride in ornate attire. Prompt: 'A woman in bridal clothing with white roses and a gold crown, looking upwards in a contemplative pose.'
Model Availability, Licensing, and Research Impact
Playground v2 is released under the Playground v2 Community License, permitting both research and commercial use. The model and its intermediate checkpoints are fully accessible, promoting transparency in benchmark reporting and reproducibility in generative AI research (Playground v2 256px Base Model, 512px Base Model).
Technical resources, including the full Hugging Face repository and detailed blog announcement, provide further guidance for integrating Playground v2 into research workflows. The release strategy, encompassing models at multiple training resolutions, enables detailed study of generative model progression and architectural scaling.
The continued release of model checkpoints and benchmarks supports further research into foundational models for high-resolution image generation.
Limitations
While Playground v2 demonstrates strong performance in both aesthetic quality and image-text alignment, common diffusion model limitations remain, such as occasional mismatches between prompts and outputs or increased computational cost for high-resolution synthesis. Explicit limitations are not detailed in the primary documentation, but considerations related to bias or incomplete prompt understanding may apply as with other generative models.