Launch a dedicated cloud GPU server running Laboratory OS to download and run SDXL Turbo using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
stabilityai / SDXL Turbo
SDXL Turbo is a text-to-image diffusion model that generates 512×512 pixel images in a single inference step using Adversarial Diffusion Distillation (ADD). Built on the SDXL framework with 3.1 billion parameters, it achieves real-time synthesis by combining adversarial and score-based distillation during training, eliminating the need for classifier-free guidance while maintaining high visual quality and prompt adherence.
Explore the Future of AI
Your server, your data, under your control
SDXL Turbo is a text-to-image generative model introduced by Stability AI on November 28, 2023. Developed atop the SDXL framework, SDXL Turbo employs Adversarial Diffusion Distillation (ADD), an approach that enables the creation of high-fidelity images in a single inference step. This design enables real-time image synthesis with efficiency and visual quality in prompt-driven image generation. The model, its research, and open weights are available through Stability AI's official announcement, the model card, and the original research paper.
A collage displaying SDXL Turbo-generated images from a range of text prompts, highlighting the model's versatility and output quality.
SDXL Turbo's advancement is its capacity for single-step image generation, contrasting with previous diffusion models like SDXL 1.0, which often necessitate up to 50 steps for similar quality. This capability is achieved through the Adversarial Diffusion Distillation technique, which merges adversarial and score-based distillation objectives during training. The adversarial component drives the model to generate images that are perceptually indistinguishable from real data at every inference, while the score distillation leverages knowledge from a pretrained teacher model to maintain compositionality and prompt adherence.
Inference in SDXL Turbo does not utilize classifier-free guidance, lowering memory requirements and optimizing speed. While the model is designed to produce high-quality images in a single step, it is also amenable to iterative refinement: increasing the number of steps (typically 2 to 4) can enhance image consistency and detail, particularly for complex prompts or compositions, as demonstrated in empirical evaluations detailed in the ADD paper.
Model Architecture
The backbone of SDXL Turbo is a distilled variant of SDXL 1.0, equipped with approximately 3.1 billion parameters. The ADD approach involves initializing the student network from a pretrained diffusion model and introducing two complementary loss functions: an adversarial loss, which incorporates a text-conditioned discriminator (utilizing pretrained feature networks such as DINOv2 ViT-S), and a score distillation loss that supervises the model with the output of a frozen, high-capacity teacher. This dual-objective setup addresses the common issue of loss of detail and artifacts found in many rapid distillation methods by encouraging the student generator to directly synthesize sharp, high-quality images from pure noise.
Training is performed exclusively at a 512×512 pixel resolution, conforming to the finalized architecture and optimizing for real-time synthesis at this scale. A secondary model, ADD-M, based on Stable Diffusion 2.1 and consisting of 860 million parameters, is also described in the literature for comparative and ablation purposes, but SDXL Turbo's main deployment is centered on the SDXL backbone.
Performance and Benchmarks
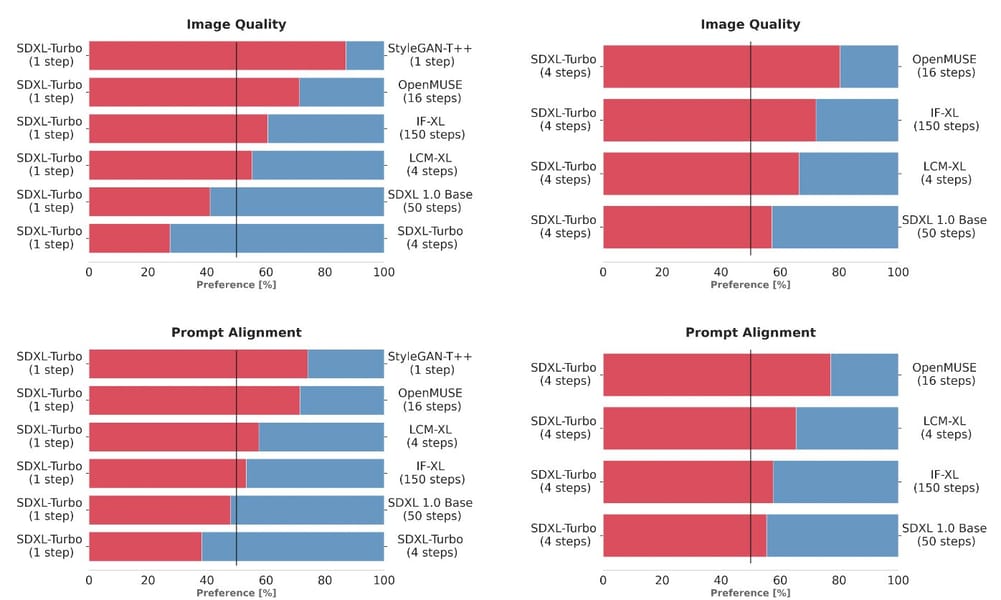
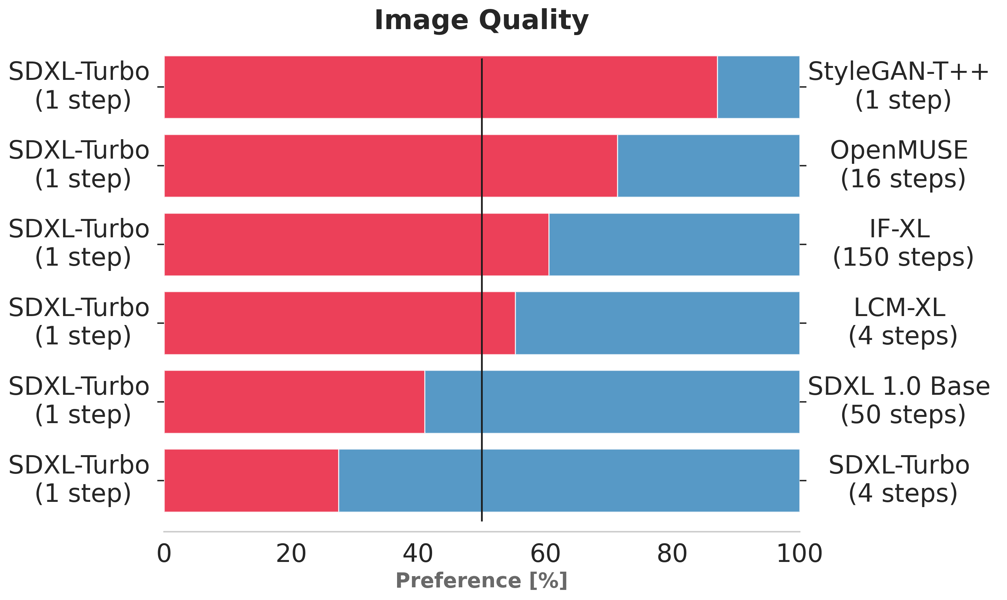
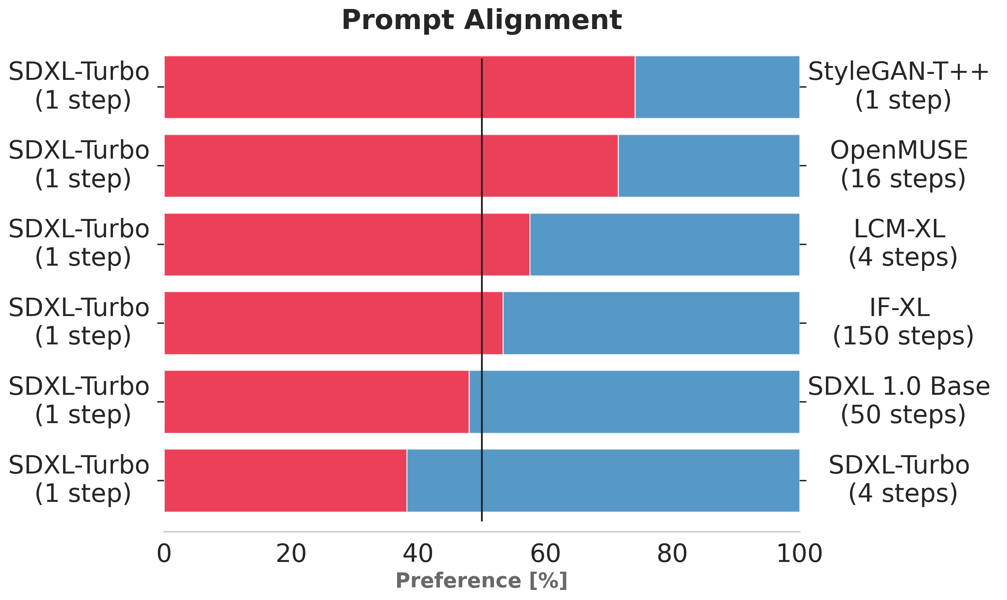
SDXL Turbo has been empirically evaluated through human preference studies and quantitative benchmarks, consistently demonstrating higher prompt alignment and image quality compared to contemporaneous one- and multi-step models such as StyleGAN-T++, OpenMUSE, IF-XL, SDXL, and LCM-XL. In preference studies, SDXL Turbo (1-step) outperformed the 4-step configuration of LCM-XL, and a 4-step configuration of SDXL Turbo (ADD-XL) exceeded the image quality and prompt adherence of the 50-step SDXL 1.0 base model.
User preference study results show SDXL Turbo achieving higher ratings in both image quality and prompt alignment over comparable diffusion models, often with fewer inference steps.
The model exhibits efficient inference speed: generating a 512×512 pixel image, including prompt encoding and decoding, takes approximately 207 milliseconds on a single A100 GPU, with the core UNet step comprising only 67 milliseconds. In zero-shot evaluations using the COCO dataset, the ADD-M model attained a Fréchet Inception Distance (FID) of 19.7 and CLIP score of 0.326 at a single step—outperforming other rapid distillation approaches such as DPM Solver and InstaFlow, as documented in the technical appendix.
Image quality comparison from user studies: SDXL Turbo (1 step) favored over multiple established models with longer inference cycles.
Despite its strengths in speed and perceptual quality, SDXL Turbo exhibits certain constraints. All generations are produced at a fixed 512×512 resolution, with performance outside this range not systematically evaluated. The model does not reliably render legible text or perfectly photorealistic imagery and may underperform on facial or person-centric scenes. The autoencoding stage introduces a lossy step, limiting recoverable detail. Moreover, SDXL Turbo's sample diversity is marginally lower than its teacher model, SDXL, and its outputs are not intended to be factual or represent real individuals or events. These aspects are further detailed in the model card.
Applications and Access
SDXL Turbo's real-time image synthesis enables use cases in creative design, educational tools, experimental research on accelerated diffusion processes, and generative model safety evaluation. While the model weights and usage instructions are open for non-commercial research under a dedicated license, for usage outside of research, the terms of use should be consulted.