Launch a dedicated cloud GPU server running Laboratory OS to download and run Mistral NeMo 12B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Mistral AI / Mistral NeMo 12B
Mistral NeMo 12B is a transformer-based language model developed collaboratively by Mistral AI and NVIDIA, featuring 12 billion parameters and a 128,000-token context window. The model incorporates grouped query attention, quantization-aware training for FP8 inference, and utilizes the custom Tekken tokenizer for improved multilingual and code compression efficiency. Available in both base and instruction-tuned variants, it demonstrates competitive performance on standard benchmarks while supporting function calling and multilingual capabilities across numerous languages including English, Chinese, Arabic, and various European languages.
Explore the Future of AI
Your server, your data, under your control
Mistral NeMo 12B is a 12-billion parameter large language model developed collaboratively by Mistral AI and NVIDIA. Released on July 18, 2024, Mistral NeMo is available as both a base pretrained model and an instruction-tuned variant. It is designed to excel across a broad spectrum of natural language processing tasks, offering high performance in multilingual contexts, code generation, extended context handling, and function calling.
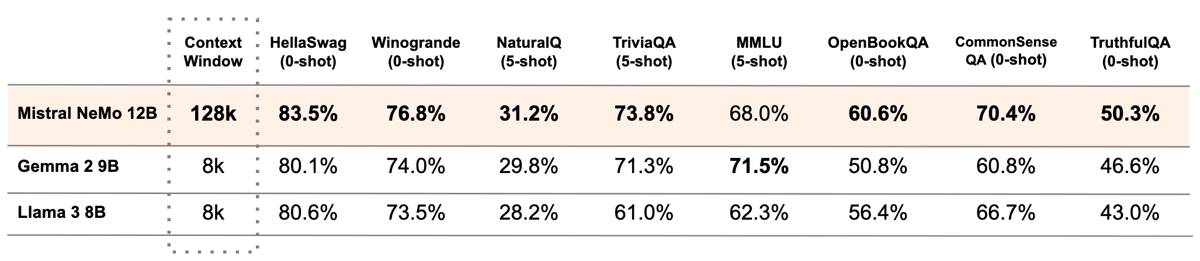
Performance comparison of Mistral NeMo 12B, [Gemma 2 9B](https://openlaboratory.ai/models/gemma-2-9b), and [Llama 3 8B](https://openlaboratory.ai/models/llama3-8b) on standard benchmarks. Mistral NeMo 12B achieves strong results, particularly in zero-shot and few-shot tasks.
Mistral NeMo 12B is based on transformer architecture, incorporating design refinements for efficiency and capability. The model utilizes 40 transformer layers, with a dimensionality of 5,120 and 32 attention heads—eight of which are key-value heads through grouped query attention (GQA) to optimize inference speed. The hidden dimension is set at 14,436, with the SwiGLU activation function enabling improvements in training dynamics. Rotary positional embeddings with a theta of one million are employed to support a substantial context window of 128,000 tokens, enabling the processing of extensive textual inputs in a single pass.
A notable aspect of Mistral NeMo's design is its quantization-aware training, supporting efficient FP8 inference without a significant decrease in model performance. This allows for reduced computational requirements during deployment, enhancing the model’s usability in resource-constrained environments.
Training Data, Tokenization, and Multilingual Capabilities
The model’s training corpus is characterized by a high proportion of multilingual and code data, supporting robust performance across numerous languages and programming scenarios. Mistral NeMo demonstrates proficiency not only in English but also in French, German, Spanish, Italian, Portuguese, Mandarin Chinese, Japanese, Korean, Arabic, and Hindi, among others.
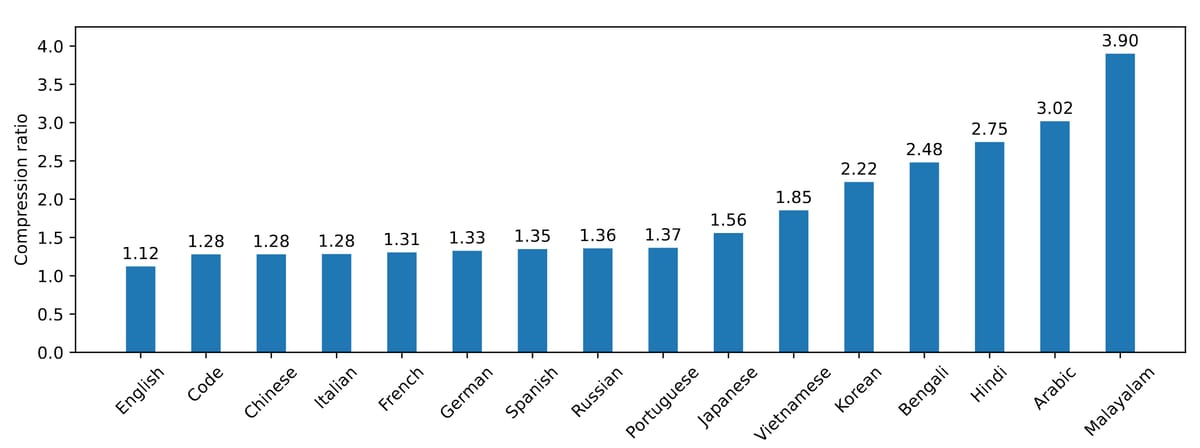
Mistral NeMo utilizes a custom tokenizer, Tekken, which is derived from Tiktoken. Tekken was trained on datasets spanning over one hundred languages, yielding notable improvements in text and source code compression efficiency. For example, the new tokenizer is approximately 30% more effective at compressing source code, Chinese, Italian, French, German, Spanish, and Russian texts. Compression efficiency is up to 2x higher for Korean and 3x for Arabic when compared to earlier Mistral models using the SentencePiece tokenizer. These enhancements contribute to its performance in language modeling for diverse linguistic data.
Bar chart illustrating the Tekken tokenizer’s compression ratios for several major languages and source code, highlighting the efficiency gains achieved in Mistral NeMo’s preprocessing pipeline.
Mistral NeMo 12B exhibits competitive results on established language model evaluation benchmarks, frequently surpassing other models in its parameter range such as Gemma 2 9B and Llama 3 8B. According to results published at the time of its release, NeMo 12B achieves notable scores across tasks including reasoning, world knowledge, and reading comprehension. For instance, zero-shot performance on HellaSwag reaches 83.5%, and the model delivers 76.8% accuracy on Winogrande. On comprehension tasks, it scores 73.8% on TriviaQA (five-shot) and 68.0% on MMLU (five-shot).
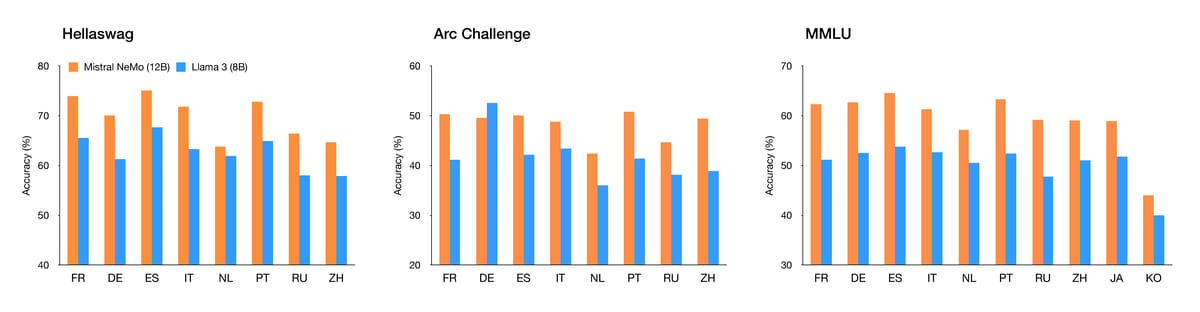
Mistral NeMo demonstrates strong multilingual performance. It maintains high accuracy across a broad set of languages on multilingual versions of the MMLU benchmark, supporting effective deployment in diverse settings.
Bar charts comparing Mistral NeMo (12B) and [Llama 3 8B](https://openlaboratory.ai/models/llama3-8b) accuracy on Hellaswag, Arc Challenge, and MMLU benchmarks for multiple languages. Mistral NeMo demonstrates strong multilingual capability, with consistently high scores across languages.
Instruction tuning further enhances the model’s effectiveness, leading to improvements in following user directions, reasoning in multi-turn dialogues, and code generation compared to earlier models like Mistral 7B.
Features, Applications, and Use Cases
Mistral NeMo 12B includes several practical features. The model is trained to handle function calling, facilitating integration into systems that require structured tool use or automated workflows. Its extended context window allows for processing longer conversations, documents, or codebases than many contemporaries.
With its foundational multilingual and code training, the model is suitable for applications in global communications, technical support, document summarization, multi-language conversational agents, and automated code generation. Instruction-tuned variants are optimized for precise instruction following, reasoning capabilities, and engagement in sustained multi-turn dialogues.
The model’s architecture maintains compatibility to serve as a drop-in replacement for Mistral 7B within existing pipelines, simplifying transitions and integration into previously built systems.
Limitations and Licensing
The pretrained Mistral-Nemo-Base-2407 model does not include integrated content moderation mechanisms, necessitating careful evaluation and post-processing in domains with stringent safety or compliance requirements. The model and its variants are released under the Apache 2.0 License, enabling broad use across research and industry.