Launch a dedicated cloud GPU server running Laboratory OS to download and run SDXL Motion Model using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Automatic1111's legendary web UI for Stable Diffusion, the most comprehensive and full-featured AI image generation application in existence.
Model Report
conrevo / SDXL Motion Model
The SDXL Motion Model is an AnimateDiff-based video generation framework that adds temporal animation capabilities to existing text-to-image diffusion models. Built for compatibility with SDXL at 1024×1024 resolution, it employs a plug-and-play motion module trained on video datasets to generate coherent animated sequences while preserving the visual style of the underlying image model.
Explore the Future of AI
Your server, your data, under your control
AnimateDiff is a generative framework designed to animate personalized text-to-image (T2I) diffusion models while maintaining high fidelity to the original image domain. Presented as a spotlight paper at ICLR 2024, AnimateDiff builds on the principles of plug-and-play modularity, enabling the direct insertion of a trained motion module into various personalized diffusion models. This approach allows static models, such as those based on Stable Diffusion, to generate coherent video outputs without the necessity of model-specific fine-tuning. AnimateDiff is released for academic and research use under an Apache-2.0 license.
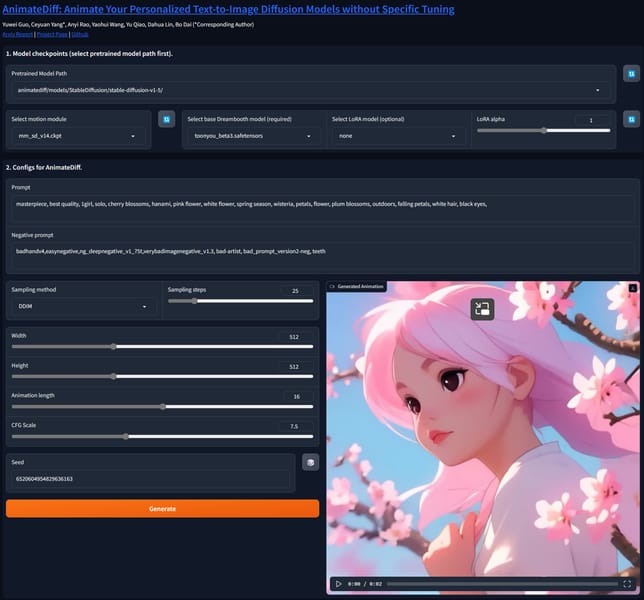
The AnimateDiff Gradio application provides interactive controls for model selection, animation parameters, and prompt specification, with real-time preview of generated animations.
At the center of AnimateDiff is a motion module designed for seamless integration with existing T2I diffusion models. Once trained, this module can be reused across a wide variety of personalized models that share the same foundational architecture, such as Stable Diffusion 1.5. The module captures motion priors from real-world videos, enabling it to impart realistic animation dynamics to static images generated by the base models.
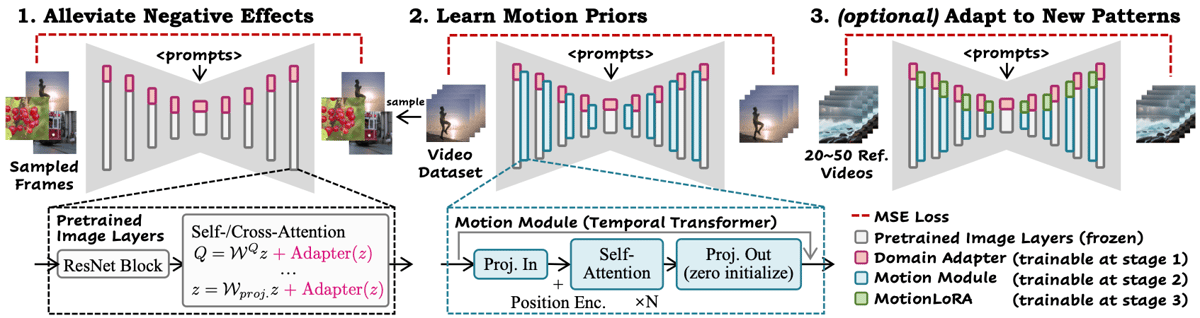
AnimateDiff employs a three-stage training pipeline:
A domain adapter is first trained to address visual artifacts and align the model’s output with the distribution of the target video dataset.
The motion module is then trained on short video clips to learn transferable motion priors. This module expands the static 2D diffusion process to the temporal domain, using a Transformer-based architecture for efficient sequence modeling.
Optionally, the MotionLoRA technique is applied to adapt the motion module to novel and specific motion patterns—such as camera zooms, pans, and tilts—with minimal data requirements and low training cost. MotionLoRA checkpoints are lightweight and can be composed for complex motion styles.
Three-stage AnimateDiff training pipeline: domain adaptation addresses dataset artifacts, the motion module learns motion priors from video, and MotionLoRA enables efficient adaptation to new motion styles.
AnimateDiff also supports the SparseCtrl mechanism for animation control, allowing users to guide generative video outputs with sparse inputs such as edge maps or sketches.
Model Architecture
AnimateDiff's architecture is anchored on the widely adopted Stable Diffusion 1.5 model, with support for both the original V1.5 and the high-resolution SDXL variants. The core innovation lies in the temporal extension of the diffusion model: a temporal Transformer module is injected into the denoising process, where it attends to temporal relations across video frames. This Transformer is initialized to function as an identity operator, ensuring stable convergence during early stages of training.
The three-stage pipeline works as follows:
The domain adapter, implemented as a Low-Rank Adaptation (LoRA) module, corrects for defects such as watermarks in the training data, ensuring that the motion module need not learn domain-specific artifacts.
The frozen base image model is augmented with the motion module, which is exclusively responsible for temporal modeling across frames.
MotionLoRA enables parameter-efficient adaptation to diverse and specific video motions using limited reference data.
This design preserves the underlying style, content, and diversity of the source text-to-image models while imparting them with coherent temporal dynamics.
Training Data and Methodology
The motion module is principally trained on large-scale video datasets such as WebVid-10M, which consists of millions of real-world video clips. This exposure enables the model to distill broad motion priors without overfitting to specific content or domains.
For targeted adaptation, MotionLoRA leverages a small set of reference videos—typically between 20 and 50—to specialize the motion module for unique motion types, such as specific camera movements. Data augmentation techniques, such as simulated cropping dynamics, can be used to artificially expand the reference set, further reducing data requirements.
The SparseCtrl extension integrates control signals in the form of sparse image inputs, such as edge maps or sketch-like guides, ensuring fine-grained control over the structure and content of the generated animation.
Evaluation and Performance
AnimateDiff has been evaluated against prominent video synthesis models, including Text2Video-Zero and Tune-a-Video, using both quantitative metrics and user studies. Key evaluation metrics include text-image alignment, domain similarity, and perceived motion smoothness.
In controlled user studies, AnimateDiff demonstrated favorable rankings for motion smoothness and domain preservation, maintaining the aesthetic and stylistic properties of the source personalized models. Quantitative metrics based on CLIP similarity further support these findings, with AnimateDiff delivering strong performance on measures of semantic alignment and visual coherence.
The method is robust to diverse prompts and personalized styles, making it compatible with a wide range of community-trained models, such as ToonYou, Lyriel, majicMIX Realistic, and others.
Use Cases and Limitations
AnimateDiff is primarily utilized for animating static images produced by personalized T2I diffusion models, enabling the creation of diverse, artistically consistent video sequences from single prompts. Applications extend to creative industries such as animation, film pre-visualization, and dynamic digital illustration. Fine-grained animation effects—including camera shots and smooth scene transitions—can be achieved with MotionLoRA and SparseCtrl.
Nonetheless, like all video synthesis models, AnimateDiff has known limitations:
Minor flickering can occur in generated videos, particularly for long or complex sequences.
Overall visual quality for generic text-to-video (T2V) tasks may be lower compared to models optimized specifically for this setting, as AnimateDiff prioritizes compatibility with custom community models.
For optimal style alignment in image interpolation or animation, input images should be generated using the same model checkpoint.
The quality of specialized animations via MotionLoRA degrades if too few reference videos are used during adaptation.
Computational requirements for high-resolution SDXL generation are substantial.
Development Timeline and Availability
The AnimateDiff project has seen several major releases:
Version 1 debuted in July 2023, with foundational support for personalized model animation.
Version 2, released in September 2023, improved motion quality and introduced MotionLoRA for explicit motion control.
The SDXL-beta branch, launched in November 2023, enables high-resolution (1024×1024) video generation.
Version 3, available from December 2023, introduced the domain adapter LoRA and SparseCtrl for advanced animation control.
The project is available under open-source terms, with code, documentation, and pre-trained weights accessible for research and non-commercial use.