Launch a dedicated cloud GPU server running Laboratory OS to download and run Llama 3 70B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / Llama 3 70B
Llama 3 70B is a 70-billion-parameter decoder-only transformer language model developed by Meta and released in April 2024. The model employs grouped query attention, an 8,192-token context length, and a 128,000-token vocabulary, trained on over 15 trillion tokens from publicly available data. It demonstrates strong performance on benchmarks including MMLU, HumanEval, and GSM-8K, with specialized instruction tuning for dialogue and assistant applications.
Explore the Future of AI
Your server, your data, under your control
Meta Llama 3 70B is a large language model (LLM) developed by Meta and released on April 18, 2024. As part of the Llama 3 family, Llama 3 70B is an instruction-fine-tuned, decoder-only transformer model comprising 70 billion parameters. It is primarily optimized for dialogue and assistant-style interactions in English, with a focus on improved alignment and reasoning capabilities. Its design and training leverage recent advances in tokenizer efficiency, attention mechanisms, and responsible AI deployment frameworks. Llama 3 70B is released under the Meta Llama 3 Community License, facilitating both commercial and research use while emphasizing responsible deployment practices.
Introduction to Meta Llama 3, highlighting its architecture, training, and intended applications. [Source]
Model Architecture and Training
Llama 3 70B utilizes a decoder-only transformer architecture, which is standard among contemporary large language models. Several technical enhancements distinguish this iteration from prior models in the Llama series. The model implements a tokenizer with a vocabulary size of 128,000 tokens, contributing to efficient language encoding and reduced inference overhead. Grouped Query Attention (GQA) is incorporated to increase scalability and inference speed without substantial accuracy trade-offs, an approach present in both the 8B and 70B parameter versions (Meta technical blog).
Training was conducted on sequences of up to 8,192 tokens, using masking strategies to prevent self-attention across different document boundaries, thereby preserving data integrity and contextual relevance. The model underwent supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), including techniques such as rejection sampling, Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO) to align outputs with human preferences concerning helpfulness and safety (training details).
The pretraining phase utilized more than 15 trillion tokens sourced from publicly available data, representing a sevenfold increase over the dataset size used for Llama 2, and included a significant proportion of high-quality code and non-English language text. Data-quality pipelines employed heuristic filters, semantic deduplication, and Llama 2-powered text quality classifiers, with detailed scaling laws applied to predict model performance and optimize data mixing across domains (Meta AI documentation).
Significant infrastructure was committed to training, leveraging custom-built GPU clusters for data and model parallelization. Training efficiency and reliability were improved through automated hardware health monitoring, attaining an effective training time above 95% and throughput upwards of 400 TFLOPS per GPU in large distributed settings (Meta infrastructure details).
Evaluation and Benchmark Performance
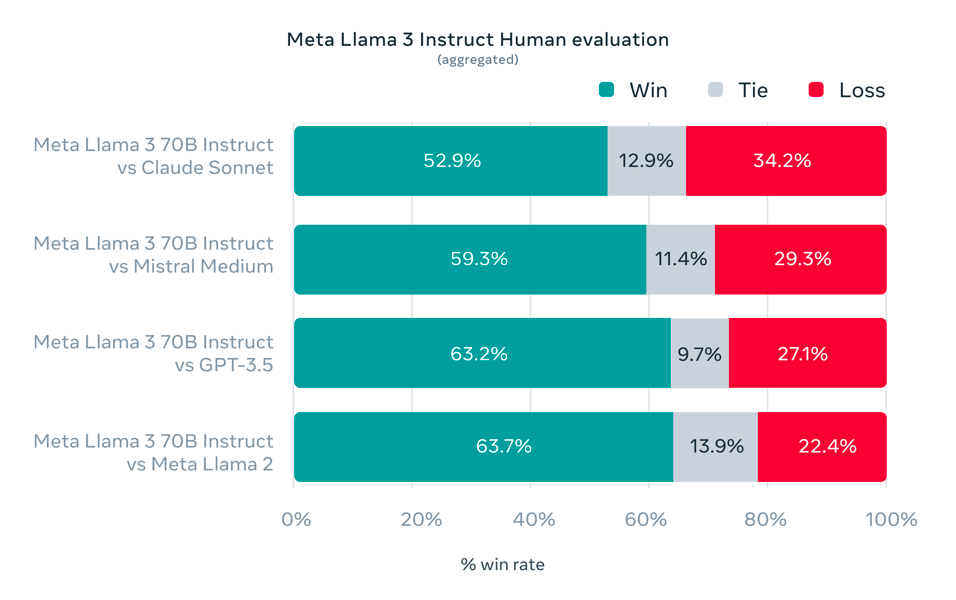
The Llama 3 70B model achieves competitive results across a broad range of benchmarks, particularly in instruction following, reasoning, and code generation tasks. Meta introduced a new high-quality human evaluation set comprising 1,800 prompts across twelve core use cases, enabling systematic comparison with other advanced LLMs such as Claude Sonnet, Mistral Medium, and GPT-3.5 (Meta Llama 3 evaluation methodology). Aggregate human preference assessments consistently favored Llama 3 70B Instruct model in side-by-side comparisons.
Aggregated human evaluation results: Llama 3 70B Instruct achieves a majority win rate compared to Claude Sonnet, Mistral Medium, GPT-3.5, and Llama 2 across broad use cases.
Standardized benchmarks further validate these findings. On tasks such as MMLU (Massive Multitask Language Understanding), GPQA (Graduate-Level Physics Questions), HumanEval (code generation), GSM-8K (math word problems), and MATH, Llama 3 70B demonstrates strong performance relative to previous open models and competitive proprietary systems.
Benchmark results for Llama 3 70B across MMLU, GPQA, HumanEval, GSM-8K, and MATH, highlighting comparative performance among contemporary large language models.
For instance, Llama 3 70B Instruct records scores such as 82.0 on MMLU (5-shot), 39.5 on GPQA (0-shot), 81.7 on HumanEval, 93.0 on GSM-8K, and 50.4 on MATH, substantially outperforming Llama 2 70B (benchmark data). These evaluations underscore the improvements achieved through expanded datasets, refined training, and enhanced instruction tuning.
Responsible Deployment and Safety
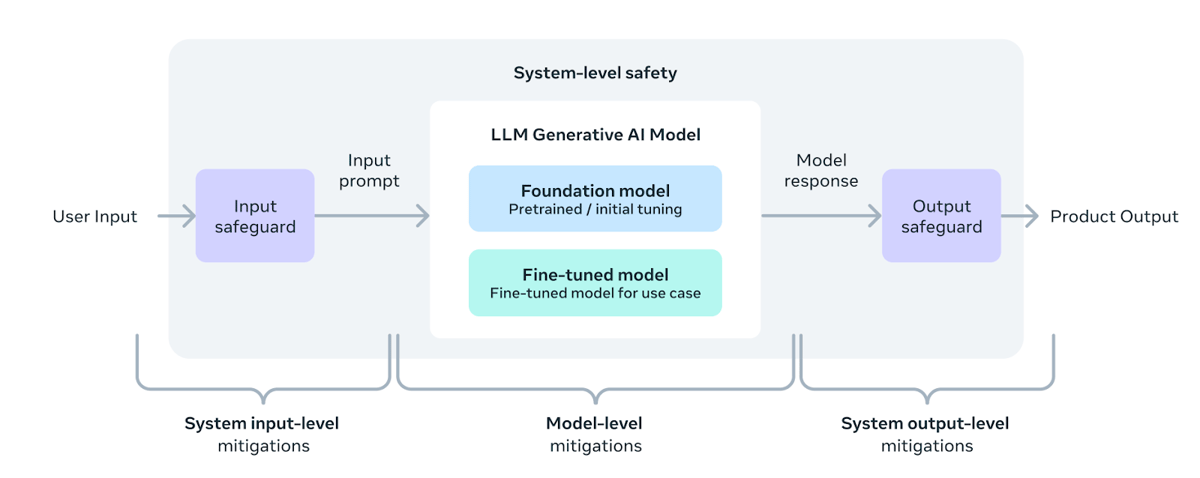
Meta emphasizes a layered, system-level approach to safety in deploying Llama 3 70B. This methodology incorporates safeguards at three stages: system input, model-level, and system output. Before reaching the model, user inputs are filtered through input safeguards, which may include tools such as Llama Guard. After the model generates an output, the result passes through output safeguards to further minimize risks prior to delivery to the user. These measures address known challenges such as hallucination, inappropriate refusals, and the handling of unsafe or out-of-scope instructions (Meta AI responsibility).
System-level approach to safe LLM deployment, featuring input and output safeguards around the core LLM model.
Guidance for responsible deployment advises developers to implement additional safety checks, customize moderation systems, and use open-sourced tools such as Code Shield for code-related use cases (PurpleLlama repository). Meta’s Acceptable Use Policy defines prohibited use cases, such as unlawful or high-risk applications, and encourages disclosure of AI system risks to end-users. Feedback mechanisms, output reporting tools, and collaborative vulnerability programs supplement post-release safety monitoring (Meta AI responsibility post; Llama output feedback).
Applications and Use Cases
Llama 3 70B is designed for a broad range of natural language understanding and generation applications. Key use cases include assistant-style chatbots, creative writing, code generation, summarization, classification, and open-ended reasoning tasks (Meta AI announcement). The model has also been introduced in Meta AI applications embedded in Facebook, Instagram, WhatsApp, and Messenger, powering advanced assistant capabilities.
The model’s general-purpose pretraining enables further adaptation for domain-specific tasks, including research, enterprise automation, and educational technology. Developers may fine-tune Llama 3 for additional languages, compliance-checked domains, or particular dialog modes, subject to licensing and responsible AI guidelines (Llama 3 model card). Notably, Llama 3’s improved handling of refusals—balancing safety and utility—enhances its adoption in interactive settings where reliability and transparency are crucial.
Limitations and License
Despite its strengths, Llama 3 70B maintains several important limitations. The model's primary design focus is on English-language tasks, and while its dataset includes a non-trivial quantity of other languages, performance in non-English use cases is lower. As with all large language models, Llama 3 70B may generate inaccurate, biased, or factually outdated outputs, with a pretraining knowledge cutoff in December 2023. Developers are thus encouraged to rigorously test, monitor, and, if necessary, further align the model for target tasks (Meta AI documentation).
Llama 3 70B is distributed under the Meta Llama 3 Community License Agreement (official license text). This license allows broad use in research and commercial settings, with specific requirements for attribution and redistribution and explicit prohibitions on improving other large language models with Llama 3 outputs. The Acceptable Use Policy outlines boundaries for responsible deployment, addressing compliance, safety, attribution, and intellectual property considerations. Entities exceeding threshold usage volumes must seek a license from Meta per the license’s commercial terms.
Future Directions
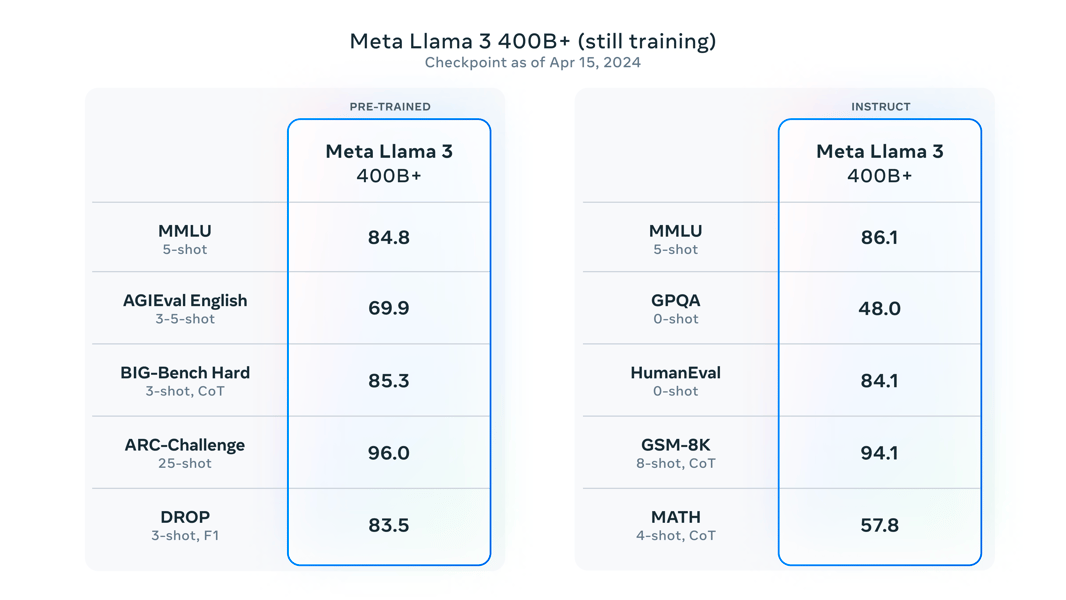
Meta has publicly shared plans to further expand the Llama 3 family, including models with larger parameter counts and extended context windows. Early benchmarks for forthcoming models, such as those with over 400B parameters, indicate continued improvement on established benchmarks and diverse tasks (Meta Llama 3 blog). Multilingual and multimodal capabilities, as well as integration with augmented reality hardware, are also under exploration for future releases.
Benchmark progress of Llama 3 models under training, including future releases such as the 400B+ parameter version.