Note: FLUX.1 [dev] weights are released under a FLUX.1 [dev] Non-Commercial License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run FLUX.1 [dev] using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
black-forest-labs / FLUX.1 [dev]
FLUX.1 [dev] is a 12-billion-parameter text-to-image generation model developed by Black Forest Labs, utilizing a hybrid architecture with parallel diffusion transformer blocks and flow matching training. The model employs guidance distillation from FLUX.1 [pro] and supports variable aspect ratios with outputs ranging from 0.1 to 2.0 megapixels, released under a non-commercial license for research and personal use.
Explore the Future of AI
Your server, your data, under your control
FLUX.1 [dev] is a generative artificial intelligence model developed by Black Forest Labs for text-to-image synthesis. As part of the FLUX.1 suite, it is designed to produce images from textual descriptions, balancing performance, efficiency, and broad accessibility for research and creative workflows. The model leverages a hybrid generative architecture and introduces several technical innovations to improve visual quality and computational efficiency.
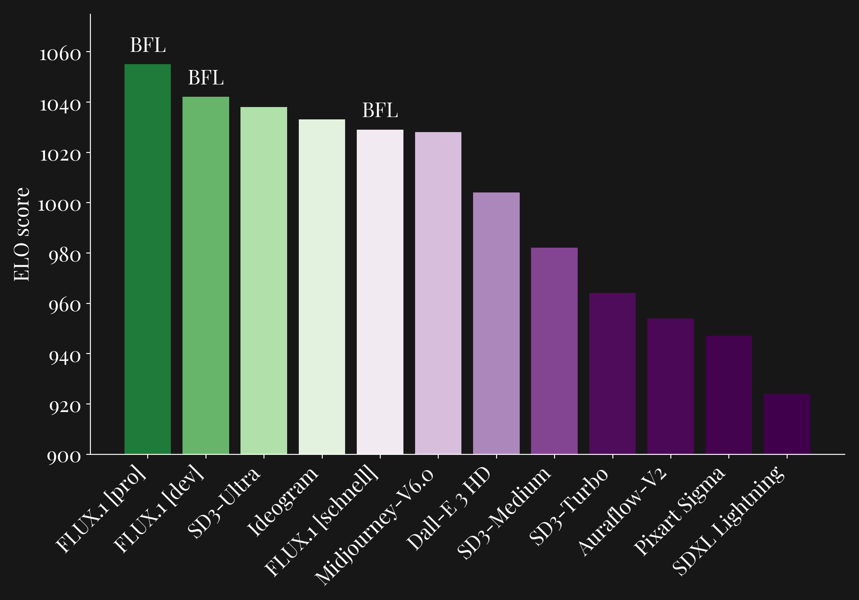
ELO benchmark scores comparing FLUX.1 [dev] and other leading text-to-image models, illustrating performance across the model landscape.
FLUX.1 [dev] is built on a hybrid architecture, incorporating both multimodal and parallel diffusion transformer blocks as foundational components. This architecture is heavily inspired by recent advances in parallel diffusion transformers and multimodal learning, with technical details drawing from approaches such as parallel diffusion transformer blocks and multimodal transformers. A key innovation in FLUX.1 [dev] is the use of flow matching, a generalized training method for generative models that unifies and extends traditional diffusion processes.
Enhancements for efficiency and scalability are central in this model. Rotary positional embeddings, introduced in this foundational research, and parallel attention layers—optimized as described in recent work—are integrated into the architecture to maximize hardware utilization, speed up inference, and improve model convergence at scale. FLUX.1 [dev] comprises 12 billion parameters, similar in scale to other openly released models exhibiting high parameter counts.
Model training utilizes guidance distillation, in which FLUX.1 [dev] is distilled directly from the FLUX.1 [pro] model. This guidance distillation approach contributes to efficiency, reducing resource demands while maintaining high fidelity in output.
Performance and Benchmarking
FLUX.1 [dev] exhibits performance comparable to other text-to-image models. According to benchmarks based on ELO scoring systems, it achieves scores comparable to proprietary industry leaders, with only the FLUX.1 [pro] variant exhibiting marginally higher scores in most evaluations.
Abstract trend chart representing cumulative improvements across the FLUX.1 model family.
Benchmarking studies consistently report that FLUX.1 [dev] matches or exceeds the visual quality and prompt adherence of other leading models, including Midjourney v6.0, DALL·E 3 (HD), and SD3-Ultra. These evaluations assess key criteria such as prompt-following accuracy, output diversity, typography, visual fidelity, and support for variable aspect ratios and resolutions.
Visual demonstration of the range of aspect ratios and output sizes supported by FLUX.1 models.
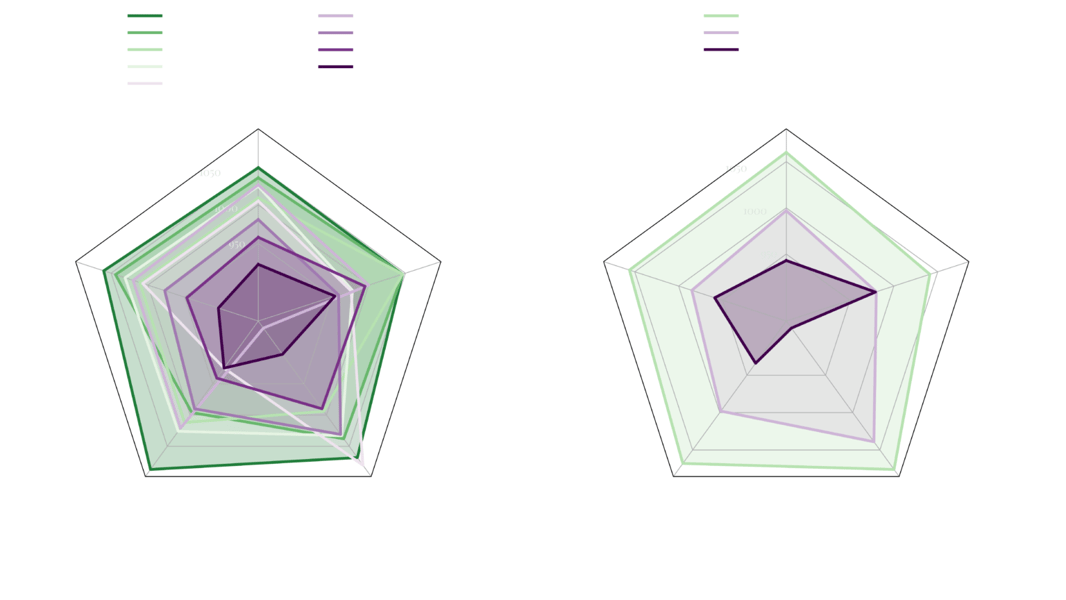
Quantitative and qualitative results have been visualized through radar charts, illustrating comparative performance among major text-to-image systems. In such visualizations, FLUX.1 models—specifically FLUX.1 [dev]—exhibit performance across prompt following, visual quality, typography, and adaptability.
Capabilities and Use Cases
FLUX.1 [dev] generates novel images from textual prompts, providing control over output style, content, and composition. Its support for a wide range of aspect ratios and output resolutions (from approximately 0.1 to 2.0 megapixels) allows for applications in diverse creative, scientific, and research workflows. These capabilities are particularly relevant for domains requiring high variability in output formats, such as digital illustration, visual communication, and rapid design prototyping.
A sample collage illustrating FLUX.1 [dev]'s ability to generate diverse images from text prompts—featuring typographic design, stylized characters, and intricate architectures.
The open-weights release of the model facilitates access for research communities and enables experimentation, extension, and benchmarking. Typical use cases include personal projects, scientific workflows, artistic creation, and research experimentation. However, users must adhere to restrictions and licensing conditions described in the model’s non-commercial license agreement and acceptable use policy.
Model Family and Related Variants
FLUX.1 [dev] is one of several variants within the FLUX.1 suite. The FLUX.1 [pro] model is trained with an emphasis on image quality, diversity, and prompt fidelity, intended for enterprise and premium use cases. For increased inference speed and local experimentation, FLUX.1 [schnell] offers a streamlined architecture. The FLUX.1 [pro] model demonstrates strong performance relative to other major systems in several core areas, according to benchmarks. Collectively, the FLUX.1 model suite was conceived as part of Black Forest Labs’ effort to contribute to the development of open generative media standards.
Limitations and Responsible Use
While FLUX.1 [dev] provides prompt following and high visual fidelity, it is not intended to generate factual information or serve as a ground-truth source. Like other large-scale generative models, it may amplify existing societal biases in data and can exhibit variation in performance depending on prompting style and complexity.
Strict usage limitations are enforced via the model's license and policies. The model and its outputs may not be used for harmful, illegal, deceptive, or exploitative purposes, including automated decision-making that affects legal rights, harassment, dissemination of private information, or large-scale disinformation. The model is available for non-commercial applications, with provisions for research, educational, and personal use under the terms laid out in the FLUX.1 [dev] Non-Commercial License Agreement. Commercial users are required to contact Black Forest Labs for inquiries regarding broader deployment rights.



![Collage showcasing image outputs from FLUX.1 [dev]](https://openlaboratory.ai/cdn-cgi/image/width=1200,height=600,quality=80/https://media.openlaboratory.ai/model-reports/model-images/967d803e1c45017178fa6fa29a6cb817dcfb43915af04a68c2ec522ac1b49d72.jpg)