Launch a dedicated cloud GPU server running Laboratory OS to download and run Wan 2.1 T2V 14B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
Wan-AI / Wan 2.1 T2V 14B
Wan 2.1 T2V 14B is a 14-billion parameter video generation model developed by Wan-AI that creates videos from text descriptions or images. The model employs a spatio-temporal variational autoencoder and diffusion transformer architecture to generate content at 480P and 720P resolutions. It supports multiple languages including Chinese and English, handles various video generation tasks, and demonstrates computational efficiency across different hardware configurations when deployed for research applications.
Explore the Future of AI
Your server, your data, under your control
Wan 2.1 T2V 14B is a generative AI model designed for video creation and editing tasks, forming a component of the comprehensive Wan2.1 video foundation model suite. This model incorporates architecture, datasets, and evaluation techniques to address a range of applications in text-to-video, image-to-video, and video editing. The design of Wan2.1 emphasizes spatio-temporal efficiency, support for multiple languages, and versatility across resolutions. Model assets and technical documentation are made openly available to the research community, fostering further exploration and development in video generation.
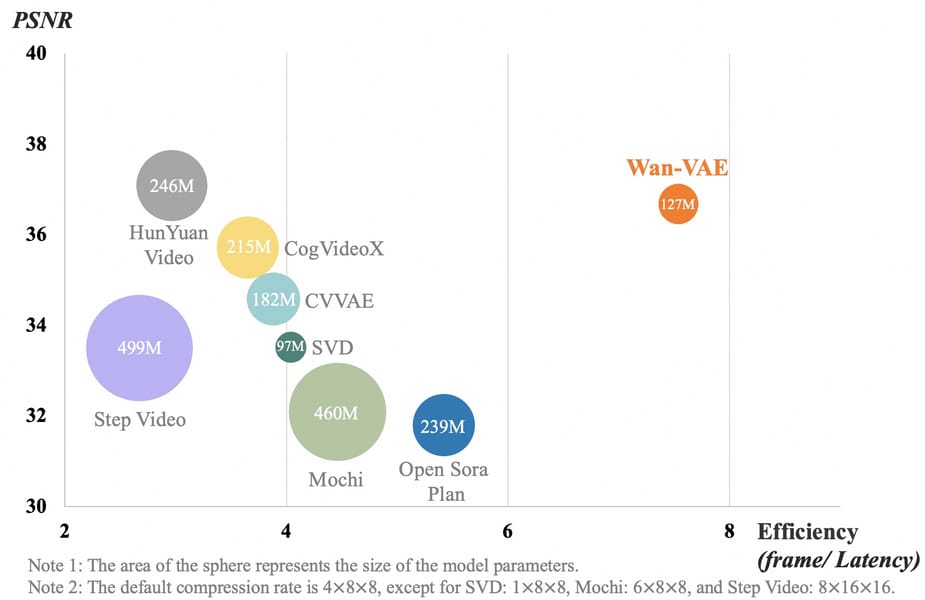
Scatter plot comparing the performance and efficiency of 3D causal VAE architectures for video generation, highlighting the memory usage and compression gains of Wan-VAE relative to contemporary models.
At the center of Wan 2.1 T2V 14B’s design is a spatio-temporal variational autoencoder (Wan-VAE) that enables efficient handling of high-resolution videos while preserving temporal dynamics. The architecture utilizes the diffusion transformer paradigm, specifically a Flow Matching framework within Diffusion Transformers, as detailed in the technical report. Textual information, including both Chinese and English content, is processed through a T5 encoder using cross-attention in transformer blocks, permitting semantic conditioning during generation.
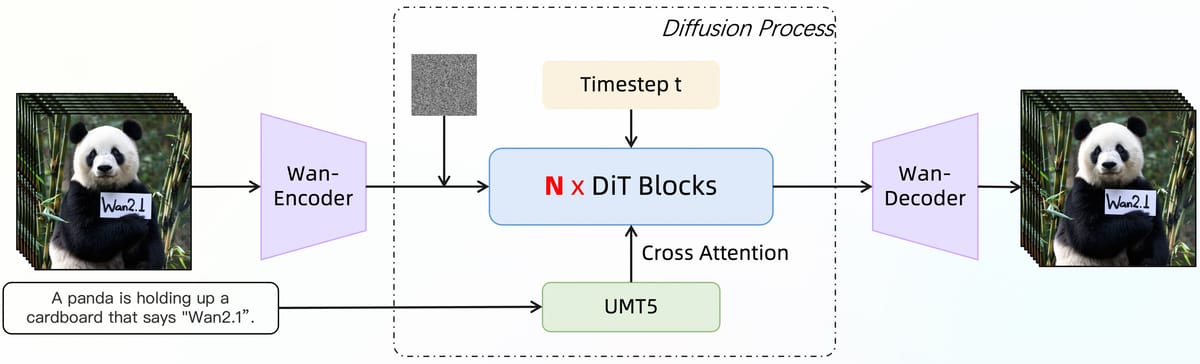
The diffusion process is orchestrated by a sequence of DiT (Diffusion Transformer) blocks, further modulated via a multi-layer perceptron (MLP) that predicts temporal parameters, enabling fine control of the diffusion trajectory. This approach combines global and temporal context for latent representation and video synthesis.
Flowchart illustrating the Wan2.1 diffusion process, with cross-modal connections between T5 (UMT5) text encoders and video DiT blocks in the generative pipeline.
Wan 2.1 T2V 14B comprises 14 billion parameters, with architectural specifications including a model dimension of 5120, feedforward dimension of 13824, 40 transformer layers, and 40 attention heads, supporting input and output dimension of 16 and a frequency dimension of 256. This configuration underlies the model's scalability and capability across tasks.
Data Collection and Training Methodology
The training dataset for Wan2.1 is constructed from a range of sources. The development process incorporated a data curation pipeline, as described in the official documentation. Data sources included images, videos, and textual information, which were filtered through multi-stage pipelines to address duplicity, visual fidelity, and motion quality.
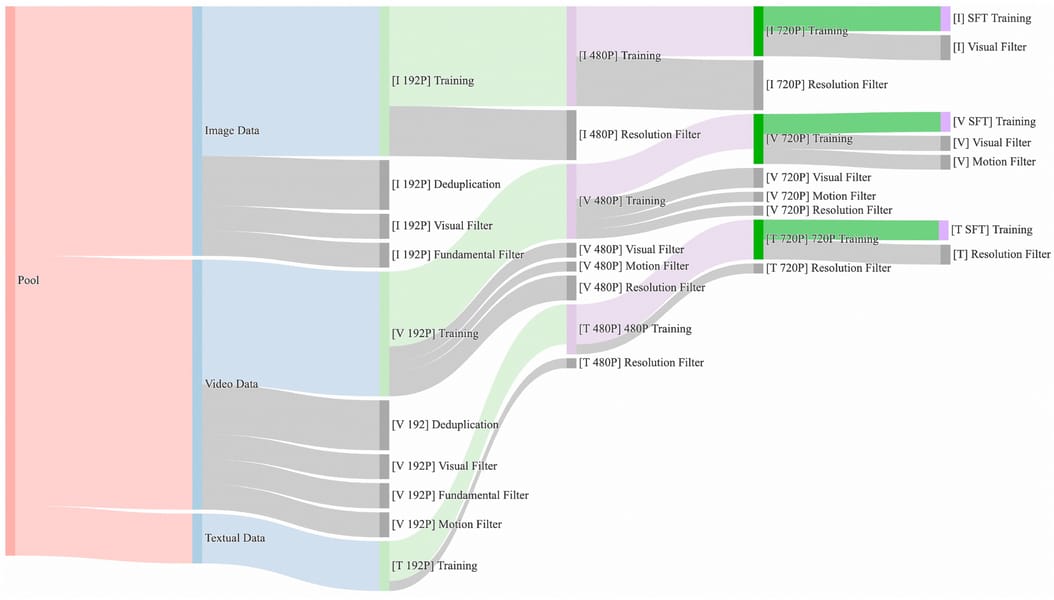
The curation workflow utilizes deduplication, visual and motion-based filtering, and tailored resolution sampling at multiple stages. This approach yields datasets aligned with the requirements of text-to-video, image-to-video, and multimodal generation tasks.
Sankey diagram outlining the multi-stage data filtering and deduplication procedures for the training corpus used in Wan2.1.
Wan 2.1 T2V 14B has undergone quantitative and qualitative evaluation against other video generation models. The Wan-Bench benchmark was developed to score outputs across 14 dimensions—such as motion generation, stability, physical plausibility, and multi-object handling—using a suite of 1,035 evaluation prompts and weighted human preference scoring.
Comparison table showing benchmark scores for Wan-14B and peer models across a range of video generation quality dimensions.
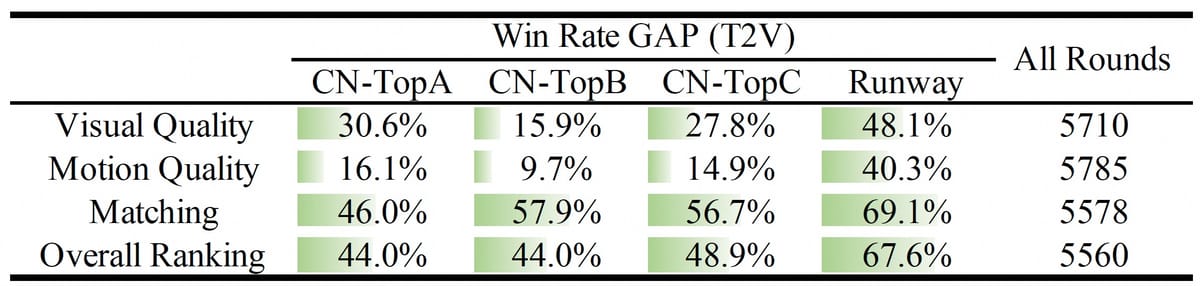
In comparative studies, Wan2.1 T2V 14B performance is reflected by outcome tables in both text-to-video and image-to-video tasks. The model's evaluation results are further detailed through automated and human-in-the-loop evaluations.
Tabular summary of win-rate gap for text-to-video generation, showing the advantage of Wan2.1 following prompt extension strategies.
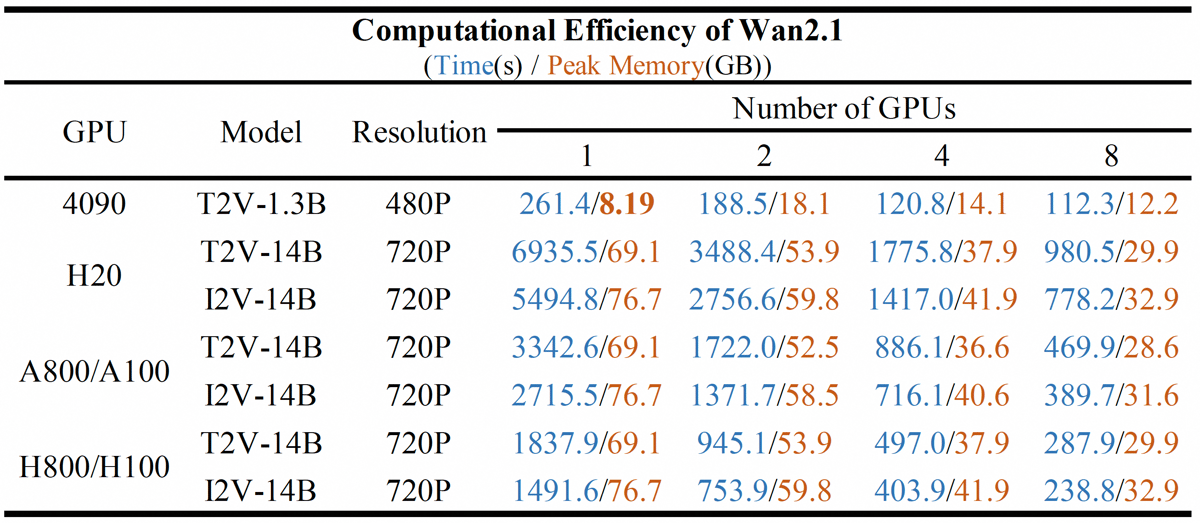
Computational efficiency metrics across various hardware platforms are provided and openly compared. For instance, T2V-14B achieves a total time of 242 seconds and a peak memory usage of 23.63 GB on a single GPU for 720P generation, with further reductions in inference time when using multiple GPUs.
Computational efficiency for Wan2.1 models across hardware and GPU allocations, detailing runtime and peak memory usage.
Wan 2.1 T2V 14B is optimized for a spectrum of generative and editing tasks, notably text-to-video, image-to-video, video editing (VACE), first-last frame video interpolation (FLF2V), and text-to-image. The model supports video synthesis at 480P and 720P, and generates visual text content in both Chinese and English within videos, expanding its practical scope.
Demonstrations of model capabilities include video synthesis from textual descriptions and the editing or transformation of existing video or image content.
Demonstration video highlighting Wan2.1 text-to-video and image-to-video generation results. [Source]Text-to-video generation demo, illustrating the model's ability to synthesize coherent video sequences from textual input. [Source]
Sample outputs produced by the model demonstrate its capacity for visual detail in diverse contexts including portrait and environmental scenes.
Generated portrait from the Wan 2.1 T2V 14B model, demonstrating synthesis of lighting and detailed rendering.
The Wan2.1 family encompasses models at different parameter scales, including smaller variants such as T2V-1.3B—designed for use in resource-constrained environments—and specialized architectures for video creation and editing (VACE), image-to-video (I2V), and first-last frame interpolation (FLF2V). Each is tailored to specific resolution targets and generative tasks, as described in the model documentation.
The T2V-14B model supports both 480P and 720P. Dedicated training at these resolutions affects its output. Model limitations include 720P support in smaller parameter configurations, which may exhibit reduced quality. Additionally, for frame-interpolation tasks trained predominantly on Chinese datasets, output quality is higher with Chinese-language prompts.
All Wan2.1 models, including T2V-14B, are distributed under the Apache 2.0 License, allowing for extensive research, development, and application, provided use remains compliant with relevant legal and ethical standards.
Development Timeline and Resources
Project milestones include the open release of inference code and model weights in February 2025, integration into ComfyUI and Hugging Face Diffusers in March, release of the technical report in March, and subsequent extensions in FLF2V and VACE through April and May, respectively.
For further technical elaboration, benchmarks, and practical guides, users are directed to the resources linked below.