Launch a dedicated cloud GPU server running Laboratory OS to download and run Wan 2.1 I2V 14B 720P using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
Wan-AI / Wan 2.1 I2V 14B 720P
Wan 2.1 I2V 14B 720P is a 14-billion parameter image-to-video generation model developed by Wan-AI that converts single images into 720P videos. Built on a unified transformer-based diffusion architecture with a novel 3D causal VAE (Wan-VAE) for spatiotemporal compression, the model supports multilingual text prompts and demonstrates competitive performance in video generation benchmarks while maintaining computational efficiency across various GPU configurations.
Explore the Future of AI
Your server, your data, under your control
"Wan 2.1 I2V 14B 720P" is a generative image-to-video (I2V) model developed within the Wan2.1 suite by the Wan-Video team. Specializing in the synthesis of high-definition, 720P videos from single input images, the model leverages a unified transformer-based diffusion architecture and a novel 3D causal VAE (Wan-VAE) for efficient spatiotemporal compression and video generation capabilities. Its design supports prompt extension for richer visual storytelling and employs scalable, multilingual text encoding, making it applicable for a broad range of creative and research-driven use cases. This article details its capabilities, architecture, datasets, performance metrics, and its place within the broader Wan2.1 model family.
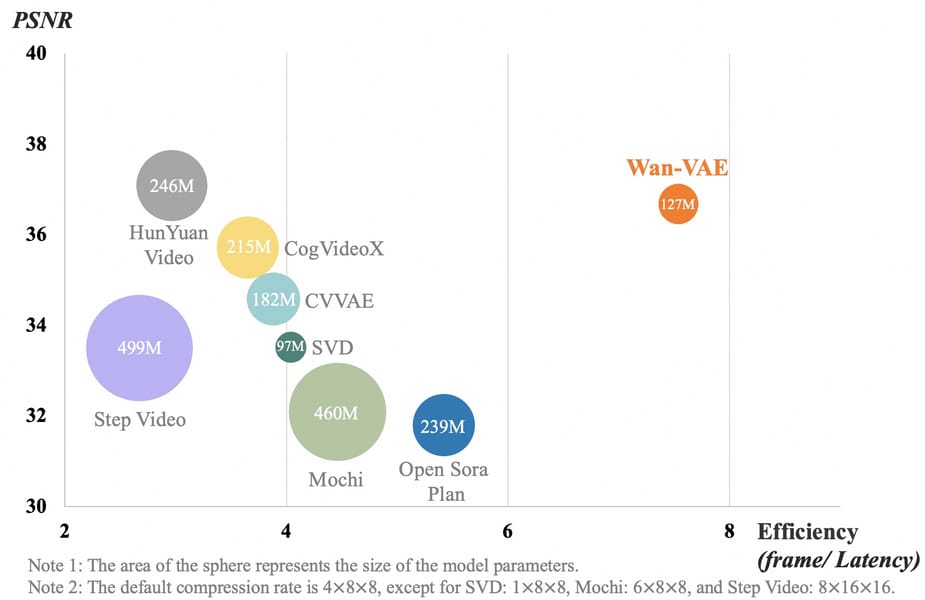
Scatter plot illustrating the spatio-temporal compression and efficiency of Wan-VAE relative to other 3D causal VAE models for video generation.
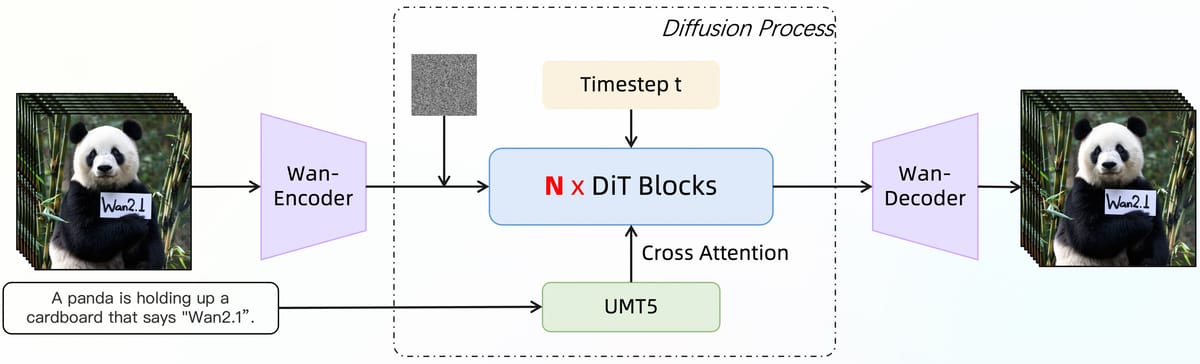
"Wan 2.1 I2V 14B 720P" is built on the diffusion transformer paradigm, integrating several notable architectural components to enhance video generation and computational efficiency. At the core of its compression strategy is the Wan-VAE, a 3D causal variational autoencoder that enables the encoding and decoding of unlimited-length videos at 1080P while preserving temporal causality and reducing memory consumption.
The primary pipeline begins with the Wan-Encoder, which extracts hierarchical spatiotemporal features from the input image. The encoded representation enters a diffusion process governed by stacked DiT (Diffusion Transformer) blocks, where temporal noise is gradually removed and new frames synthesized. To enhance language-guided video generation, a T5-based encoder is incorporated for multilingual prompt understanding, where text representations are integrated into each transformer's block via cross-attention mechanisms.
A shared multi-layer perceptron (MLP) processes temporal embeddings and predicts modulation parameters applied across transformer layers. This mechanism allows fine temporal control, with each block maintaining distinct learned biases for effective generative diversity. The DiT implementation for the 14B model features a dimension of 5120, input/output dimensions of 16, a feedforward size of 13824, 256 frequency dimensions, and consists of 40 heads and 40 layers.
Diagram of the Wan2.1 model pipeline, illustrating the interaction between the Wan-Encoder, diffusion process, and UMT5-based multilingual prompt encoding.
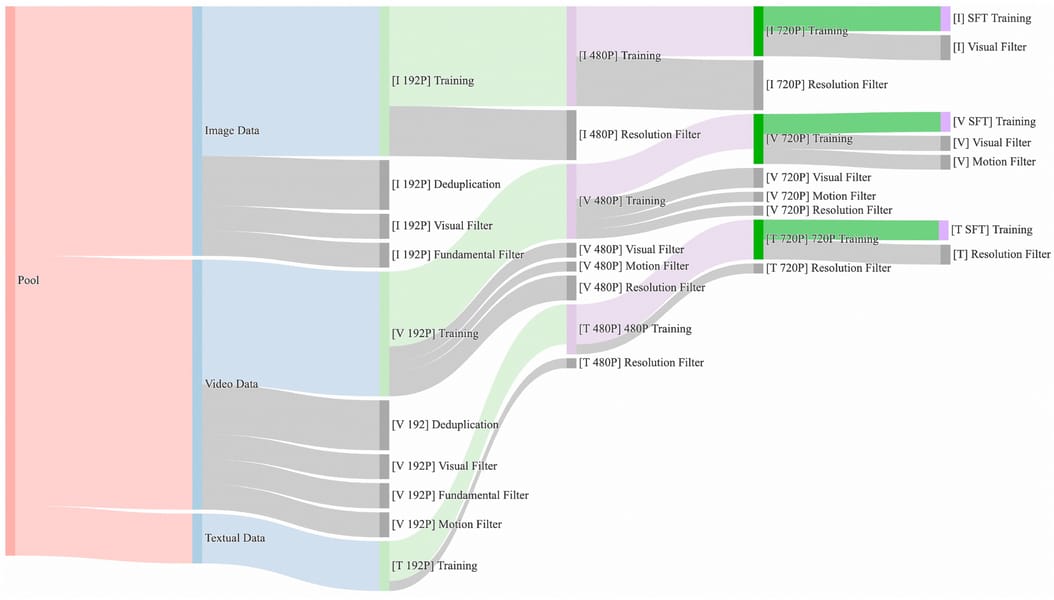
The Wan2.1 I2V model is trained on a large-scale, rigorously curated dataset encompassing still images, videos, and associated textual descriptions. The data curation pipeline is explicitly structured to ensure high quality, diversity, and deduplication throughout training. Initial data pools are filtered and separated into image, video, and textual data streams. Subsequent processes include visual and motion filtering, deduplication, and targeted resolution filtering, culminating in training-ready data for supervised fine-tuning and validation tasks.
The scalable training strategy, described in the technical report, enables robust model convergence and supports high-resolution output. The presence of multilingual data supports both Chinese and English text prompts for video and image generation.
Sankey diagram representing the multi-stage data processing and curation workflow for constructing the Wan2.1 training dataset.
The effectiveness of Wan 2.1 I2V 14B 720P is demonstrated through comprehensive benchmark tests across various video generation criteria. Its performance is evaluated in comparison to contemporary open-source models and leading commercial solutions through quantitative metrics such as PSNR, efficiency (frame latency), and comprehensive 'Wan-Bench' dimensions including large motion generation, human artifacts, pixel-level stability, object and scene quality, and camera control.
Human evaluations, involving thousands of prompts and subjective scoring across 14 major and 26 sub-dimensions, highlight the model's strength in generating visually coherent, temporally consistent, and high-quality content. The model shows competitive results in these benchmarks, as shown in publicly released evaluation tables.
Tabular comparison of leading video generation models across 14 Wan-Bench dimensions, illustrating the performance of Wan2.1 I2V 14B 720P.
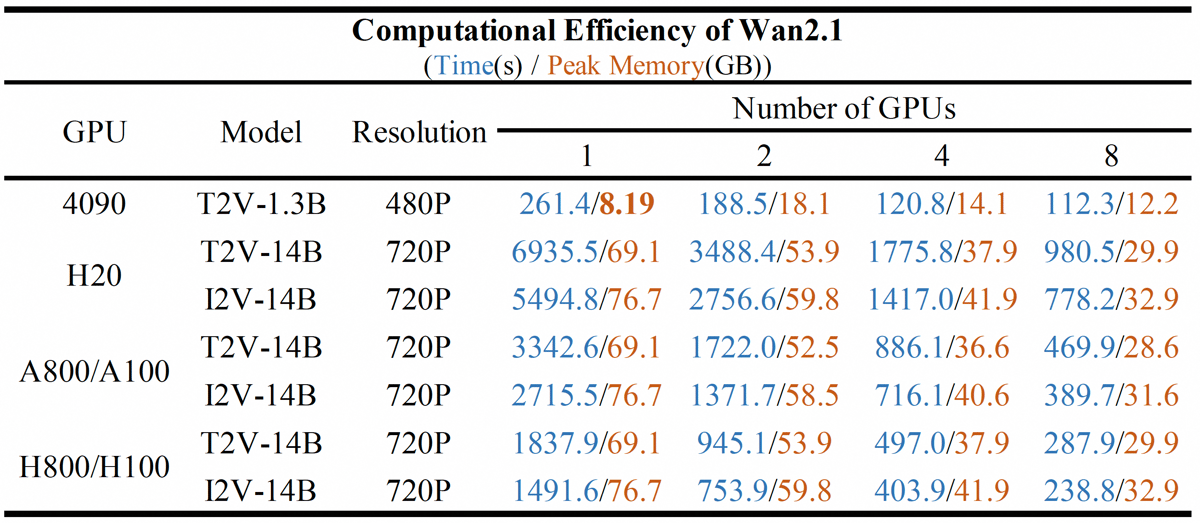
In terms of computational efficiency, the model demonstrates competitive inference speed and memory utilization. On a single GPU, generating a 1280x720 video takes approximately 56.7 seconds using 27.5GB of memory. This efficiency improves with increased parallelism; for instance, an 8-GPU setup can reduce generation time to 7.7 seconds and memory usage to 4.4GB, enabled by Fully Sharded Data Parallelism and DiT Unified Sampling Path.
Computational resource utilization of Wan2.1 models at different resolutions and GPU configurations.
The Wan 2.1 I2V 14B 720P model has been optimized for direct image-to-video synthesis. Its unified framework also supports related modalities such as text-to-video, text-to-image, and interactive video editing, extending its versatility across creative, entertainment, and research-oriented domains.
Typical applications include cinematic content generation from a single reference image, animated storytelling, and video prototyping. The model also facilitates research into spatiotemporal scene understanding and generative modeling of complex dynamics.
Demonstration video showcasing synthesized video samples generated by Wan2.1 models. [Source]Sample output from Wan 2.1 I2V 14B 720P, demonstrating image-to-video synthesis capabilities. [Source]
Example still from model-generated video, showing a cat in a realistic setting.
"Wan 2.1 I2V 14B 720P" is part of a broader Wan2.1 suite that encompasses models for text-to-video (T2V), image-to-video at 480P, first-last-frame-to-video (FLF2V), and the VACE model, which enables both video creation and editing. All models employ the unified diffusion transformer and Wan-VAE architecture, with different sizes and specializations to meet diverse computational and application needs.
Current limitations include partial integration of prompt extension and distributed inference in some deployment toolkits, such as Diffusers, and reduced stability for higher-resolution output in the smaller model variants trained primarily at lower resolutions. The FLF2V 14B model exhibits strong performance on Chinese prompts, reflecting the focus of its pretraining data.
All models in the suite are distributed under the Apache 2.0 License, granting broad usage rights, provided that users comply with relevant laws and do not disseminate harmful or prohibited content.
Timeline and Development
The Wan2.1 suite has seen progressive releases and ecosystem integrations throughout 2025, including the introduction of inference code, integration with ComfyUI and Diffusers, and the release of all-in-one solutions such as VACE for video creation and editing. The open availability of research and code supports ongoing community-driven advancement and transparency.