Note: Seamless weights are released under a CC-BY-NC 4.0 License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Seamless using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Model Report
Meta / Seamless
Seamless is a family of multilingual translation models developed by Meta that performs speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation across 100 languages. The system comprises four integrated models: SeamlessM4T v2 (2.3 billion parameters), SeamlessExpressive for preserving vocal style and prosody, SeamlessStreaming for real-time low-latency translation, and a unified model combining expressivity with streaming capabilities for natural cross-lingual communication.
Explore the Future of AI
Your server, your data, under your control
Seamless is a family of generative AI models developed by Meta's Fundamental AI Research (FAIR) group, designed to perform expressive, multilingual, and real-time speech and text translation. By unifying multiple modalities—spanning speech-to-speech, speech-to-text, text-to-speech, and text-to-text tasks—Seamless models are designed to enhance cross-lingual communication by preserving vocal style and prosodic features while minimizing translation latency. Information regarding the release of these models, code, and datasets for research use is available on the Meta AI Blog and in the research paper, with the codebase accessible on GitHub.
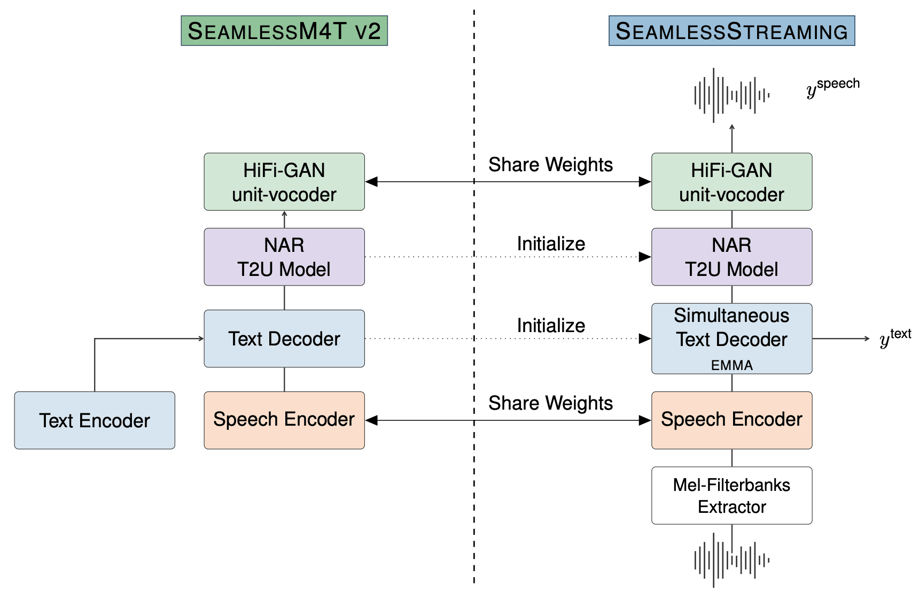
Architectural diagram illustrating the data flow and component sharing between SeamlessM4T v2 (left) and SeamlessStreaming (right), highlighting the integration of text, speech, and real-time streaming modules.
Seamless comprises four principal models: SeamlessM4T v2, SeamlessExpressive, SeamlessStreaming, and the unified Seamless model. These systems are tightly integrated to support end-to-end multilingual and multimodal translation.
SeamlessM4T v2 forms the core of this framework, featuring a multitask-UnitY2 architecture that combines a Conformer speech encoder, a Transformer-based text encoder-decoder, and a non-autoregressive text-to-unit (T2U) decoder for efficient text-to-speech generation, as described in the research paper. The large variant, SeamlessM4T-Large v2, encompasses 2.3 billion parameters and leverages a wide variety of labeled and unlabeled data, including resources from the NLLB initiative.
SeamlessExpressive extends this foundation to preserve expressive attributes such as vocal style, rhythm, and prosody in translations. It introduces two key components: PRETSSEL—a cross-lingual expressivity-preserving acoustic model—and Prosody UnitY2 for rhythm-aware speech-to-unit conversion. This enables transfer of prosodic features across languages, as detailed in the research paper.
SeamlessStreaming, derived from SeamlessM4T v2, is optimized for low-latency, real-time translation using the Efficient Monotonic Multihead Attention (EMMA) mechanism, which allows each attention head to independently determine translation boundaries, a mechanism outlined in the Efficient Monotonic Multihead Attention research. This architecture supports simultaneous translation, outputting target tokens before the source utterance has fully completed.
The unified Seamless model integrates expressivity and streaming by coupling SeamlessStreaming’s fast, partial-output generation with SeamlessExpressive’s preservation of vocal nuance, enabling real-time, high-quality, and naturalistic speech translation, as discussed on the Meta AI Blog.
Training Data and Methods
Seamless models are trained using diverse and large-scale datasets, leveraging both supervised and self-supervised sources. Central to this effort, the w2v-BERT 2.0 model is pre-trained on 4.5 million hours of unlabeled speech audio—substantially expanding upon previous iterations, as reported on the Meta AI Blog.
The multimodal SeamlessAlign corpus underpins the translation tasks by providing hundreds of thousands of hours of automatically aligned speech-text pairs across 76 languages. This dataset incorporates human-labeled content, pseudo-labeled resources created by ASR and machine translation models, and specifically curated expressive speech material, such as the multilingual mExpresso and mDRAL collections for prosodic transfer research.
Pseudo-labeling techniques are utilized to address data scarcity for rare languages and modes, such as using NLLB models for generating text translations and specialized T2U models for discrete unit representations, as noted in the research paper. Expressive translation data preparation additionally incorporates audio denoising, silence removal, and conversion of vocal styles for robust training.
Capabilities and Evaluation
Seamless enables a broad spectrum of translation and transcription tasks. Its capabilities encompass speech-to-speech (S2ST), speech-to-text (S2TT), text-to-speech (T2ST), text-to-text (T2TT), and automatic speech recognition (ASR). The unified model supports 100 languages for speech input, 96 for text input and output, and speech output for 36 languages; SeamlessExpressive covers expressive speech translation for six high-resourced languages, as described in the research paper.
Performance evaluations indicate certain outcomes when compared to preceding models and established baselines. On benchmarks such as the Fleurs dataset and CVSS, SeamlessM4T v2 exhibits higher BLEU scores in both S2TT and S2ST tasks, with up to 17% gains over cascaded systems. For automatic speech recognition, it reduces word error rates relative to models like Whisper. Non-autoregressive decoding in T2U accelerates S2ST inference.
Expressivity metrics, including ASR-BLEU, rhythm correlation, and customized measures such as AutoPCP and VSim, demonstrate SeamlessExpressive’s ability to preserve natural speech characteristics to a greater extent. Human evaluations via Prosodic Consistency Protocol and Mean Opinion Score corroborate these findings, although minor reductions in sound quality are observed for expressive modules, as presented in the research paper.
SeamlessStreaming achieves low-latency translation, maintaining competitive translation quality with only minimal degradation in metrics compared to offline models and robust output for high-resource languages. Its quality-latency trade-offs and performance across diverse language families are formally characterized in the Efficient Monotonic Multihead Attention research.
Applications, Limitations, and Responsible Use
Seamless is designed for a variety of cross-lingual communication scenarios. Use cases include:
Real-time voice and video calling, whereby participants receive live, expressive translation with minimal delay, according to information on the Meta AI Blog.
Augmented reality and virtual environments, supporting multilingual conversations for collaborative or educational contexts.
Integration into wearable devices for immediate, on-the-go translation or live captioning.
Passive content consumption, such as automatic translation of podcasts, lectures, or dubbing for multilingual multimedia production.
Despite these capabilities, several limitations are recognized. The models may demonstrate variable performance depending on language, speaker accent, or resource availability, particularly for low-resource languages, as discussed in the research paper. Expressivity modules can result in reduced sound quality in noisy conditions. The models are trained on general-domain data and may be less suited for domain-specific or long-form translation tasks. Bias in outputs and the potential for toxic or misleading content remains a concern, despite mitigation strategies. Responsible use encompasses awareness of possible misuse for voice duplication or deepfake attacks; watermarking mechanisms are provided for detection.
Seamless and its models use a combination of the CC-BY-NC 4.0 license and custom research licenses, reflecting their intended scope for academic and non-commercial research.
Release Timeline, Comparison, and Resources
SeamlessM4T was first released in August 2023, followed by the introduction of SeamlessM4T v2, SeamlessExpressive, SeamlessStreaming, and the unified Seamless model in November 2023, as detailed on the Meta AI Blog. Compared to prior approaches, Seamless differs from cascaded translation systems by employing a unified architecture, which can speed inference and reduce compound errors. The PRETSSEL model used in SeamlessExpressive is characterized by its efficiency compared to previous models like Unit Voicebox, exhibiting lower computational demand and faster synthesis, as described in the research paper.