Launch a dedicated cloud GPU server running Laboratory OS to download and run Whisper using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Experiment with various cutting-edge audio generation models, such as Bark (Text-to-Speech), RVC (Voice Cloning), and MusicGen (Text-to-Music).
Model Report
openai / Whisper
Whisper is a transformer-based automatic speech recognition model developed by OpenAI that performs multilingual transcription, speech translation, and language identification. Trained on 680,000 hours of diverse audio data across 98 languages, it uses an encoder-decoder architecture with special control tokens to handle multiple tasks. The model demonstrates robust performance across accents and noisy environments, with variants ranging from lightweight to high-accuracy configurations.
Explore the Future of AI
Your server, your data, under your control
Whisper is a general-purpose, pre-trained automatic speech recognition (ASR) and speech translation model developed by OpenAI. Introduced in September 2022, it was described in the paper "Robust Speech Recognition via Large-Scale Weak Supervision" and designed to perform multilingual transcription, speech translation, language identification, and related tasks. Whisper leverages a large-scale, weakly supervised dataset, emphasizing robustness across accents, background noise, and technical language by training on 680,000 hours of diverse audio data.
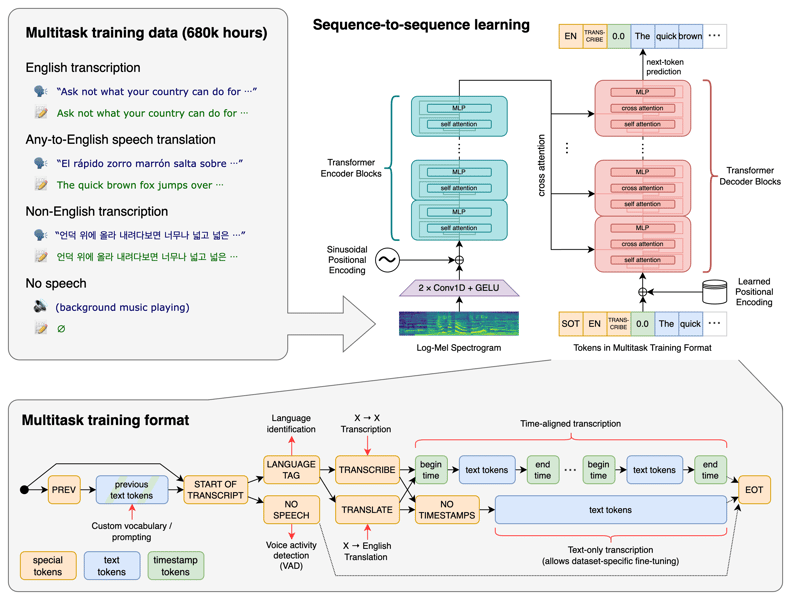
Technical diagram of the Whisper model's architecture, showing its multitask training approach, transformer sequence-to-sequence design, and data preprocessing pipeline using log-Mel spectrograms.
Whisper is built on a Transformer-based encoder-decoder architecture, which processes input audio by segmenting it into 30-second clips and converting each segment into a log-Mel spectrogram. The encoder network transforms these spectrograms into latent representations, which the decoder subsequently maps to sequences of tokens representing the transcribed or translated output.
The model is structured to handle multiple tasks through special control tokens. By prepending task- and language-specific tokens, such as indications for transcription, translation, or language identification, Whisper can switch behaviors within the same architecture. These tokens enable the model to perform multilingual transcription and speech translation without the need for fine-tuning or task-specific retraining.
Whisper's architecture parameters vary with model size. For example, in a typical configuration, the encoder and decoder each contain several layers (with model variants ranging from 4 to 32 layers), utilizing multi-head self-attention and large feed-forward networks. The vocabulary consists of approximately 51,865 tokens, accommodating a wide array of languages and annotation options.
Training Data and Multitask Learning
Whisper's multilingual and multitask capacities stem from its training on a massive, diverse audio dataset comprising 680,000 hours of labeled speech, largely sourced from the internet. The dataset includes:
438,000 hours of English audio paired with English transcripts,
126,000 hours of non-English speech transcribed into English,
117,000 hours of non-English audio aligned with transcripts in the respective languages, spanning 98 different language codes.
By alternating between transcription and translation tasks during training, Whisper's encoder and decoder are conditioned for both same-language and cross-language prediction. This data diversity allows the model to generalize effectively to new settings, demonstrating robust "zero-shot" performance across previously unseen languages, accents, and environments. However, performance remains correlated with the amount and quality of training data for each language.
Model Variants and Performance
Whisper is released in various model sizes, each providing distinct trade-offs between speed, computational resource usage, and transcription accuracy. Standard variants range from "tiny" and "base" models, designed for quick inference, to "large" and "large-v2" models that prioritize accuracy. English-only models (suffixed as .en) are optimized for high performance on English transcription, while the multilingual variants support recognition and translation across a broad scope of languages.
In benchmarks such as LibriSpeech, the large model attains a word error rate (WER) of 3.0% on the test-clean set and 5.4% on the test-other set, illustrating strong performance among state-of-the-art ASR systems. Variation in error rates is more pronounced across languages, particularly for those underrepresented in the training data.
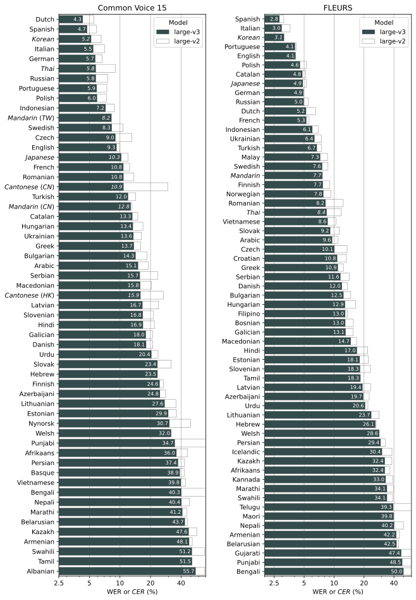
Performance comparison of the Whisper 'large-v3' and 'large-v2' models on Common Voice 15 and FLEURS datasets, demonstrating word and character error rates across a variety of languages. Lower bars indicate better accuracy.
A notable development is the large-v2 model, which was trained longer and with enhanced regularization, surpassing the accuracy of the original large model. The model family further includes the turbo variant, offering faster inference with competitive performance, and task-specific English-only versions that may yield higher accuracy for monolingual English use cases.
Functionality and Applications
Whisper supports a diverse array of speech-related tasks, including multilingual speech recognition (transcription), speech translation from various languages into English, spoken language identification, and limited voice activity detection. Its robust handling of accented speech and noisy environments makes it suitable for transcription of interviews, lectures, podcasts, and conversational recordings.
The model enables downstream applications such as accessibility tools for the hearing impaired, enrichment of voice-activated assistants, improvement of subtitle generation, and processing of large-scale audio archives. Whisper models support chunked transcription for lengthy audio, employing heuristics to maintain accuracy by conditioning segments on previously transcribed outputs and using thresholds to manage quality.
mlk.flac
Example audio file demonstrating speech that can be processed by Whisper's automatic speech recognition capabilities. [Source]
Fine-tuning is supported for domain-specific tasks or underrepresented languages, with demonstration guides available for adapting the model using custom labeled data.
Limitations and Considerations
Despite its broad capabilities, Whisper exhibits several limitations. The weak supervision and scale of training data can lead to "hallucination," where the model generates plausible but inaccurate transcriptions or translations. Word error rates tend to be higher for languages with limited training representation, and demographic or dialectal variations may impact accuracy.
Whisper's sequence-to-sequence design can produce repetitive outputs, especially for long-form audio or in lower-resource languages. Performance in real-time applications is possible but not guaranteed out-of-the-box due to system-level and computational considerations. The model is released under the MIT License, with code and weights accessible for research and development.
Ethical concerns related to the deployment of ASR systems, including privacy, surveillance potential, and disparate impact across languages or communities, are acknowledged within the Whisper research and documentation. The use of transcription for subjective or unauthorized classification is specifically cautioned against.
Timeline and Developments
Whisper's initial release in September 2022 was followed by the publication of its foundational research paper and subsequent enhancements, including the large-v2 model. Ongoing research benchmarks track its progress in multilingual and general-purpose ASR and speech translation tasks, comparing results across datasets such as LibriSpeech, Common Voice, and FLEURS.