Launch a dedicated cloud GPU server running Laboratory OS to download and run Mistral Small 3.2 (2506) using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Mistral AI / Mistral Small 3.2 (2506)
Mistral Small 3.2 (2506) is a 24-billion parameter text generation model developed by Mistral AI as an incremental update to Mistral Small 3.1. The model features improved instruction following, reduced repetition, enhanced function calling reliability, and maintained multimodal capabilities including vision processing. It supports up to 128,000 tokens context length and demonstrates performance improvements on benchmarks like Wildbench v2 and Arena Hard v2.
Explore the Future of AI
Your server, your data, under your control
Mistral Small 3.2 (2506) is a generative AI model developed by Mistral AI, released as a minor update to the earlier Mistral Small 3.1 (2503). This model belongs to the "Mistral Small" family, maintaining the same 24-billion parameter scale as its predecessor while integrating targeted improvements in instruction following, function calling, repetition avoidance, and multimodal capabilities. It builds on the architectural foundation of Mistral Small 3.1 and continues to support a broad range of languages, long context windows, and both textual and visual reasoning tasks.
Screenshot from a video game used to demonstrate the model's vision reasoning: Mistral Small 3.2 can analyze game states and recommend actions based on visual inputs. Example prompt: Analyzing a turn-based battle scenario.
Mistral Small 3.2 (2506) advances instruction following by minimizing repetition errors and enhancing robustness in function calling tasks. Compared to the previous Mistral Small 3.1 model, version 3.2 shows improved adherence to given instructions, generates more coherent and less repetitive responses, and demonstrates a more reliable implementation of external function calls—functionality critical for tool-assisted reasoning. The model maintains vision capabilities, offering the ability to interpret images for tasks such as visual diagnostics and analysis. Multilingual support continues to be strong, allowing operation across a wide range of languages.
Long-context processing is preserved, with support for up to 128,000 tokens, enabling reliable handling of lengthy documents or multi-modal data streams. The architecture remains based on the Mistral-Small-3.1-24B-Base, and the instruct tuning in the 3.2 update focuses on practical task performance and adaptability.
Handwritten mathematical expressions as input to Mistral Small 3.2 for function calling: the model leverages external calculator tools to analyze and solve equations.
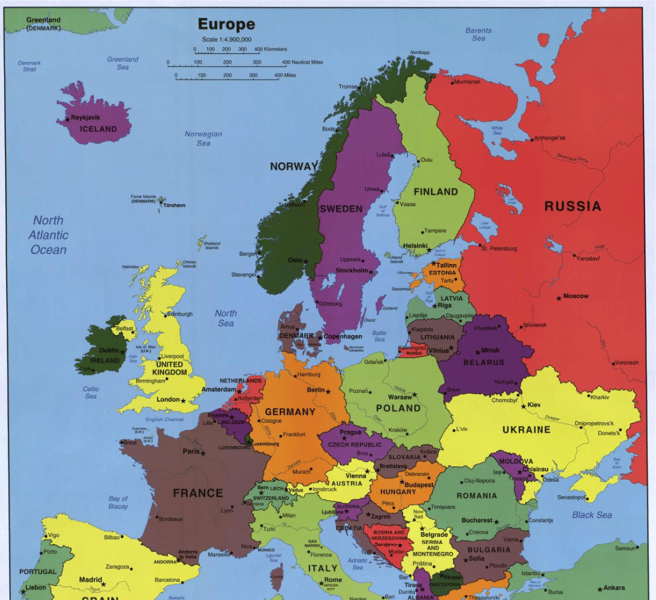
Political map of Europe used to demonstrate visual comprehension and function calling—Mistral Small 3.2 can identify information from visual input and interact with external tools, such as population databases.
Mistral Small 3.2 yields incremental yet measurable improvements over Mistral Small 3.1 across several important benchmarks. Internal evaluations show better results in instruction following and reduced instances of infinite or repetitive generations. For example, the model achieves 65.33% on the Wildbench v2 benchmark and 43.1% on Arena Hard v2, both reflecting notable gains in conversational accuracy and naturalness. Function calling reliability has been enhanced in the 3.2 update, ensuring more robust execution within automated workflows.
STEM and coding benchmarks present slight improvements, with HumanEval Plus (code generation) reaching 92.9% and MBPP Plus at 78.33%. Context-specific vision benchmarks, such as ChartQA and DocVQA, report minor gains, while others like MMMU and Mathvista register small decreases. The model's overall performance trends match or slightly exceed the previous release, with some metrics reporting small regressions that remain within standard operational variance.
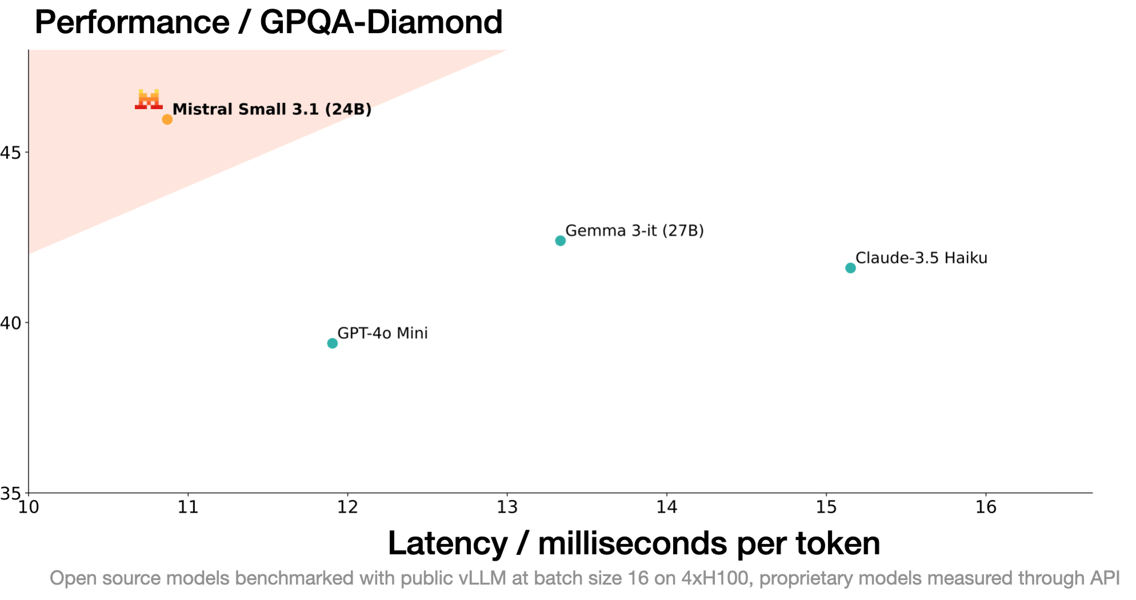
A comparison of latency and complex reasoning performance—such as the GPQA-Diamond benchmark—shows that this series maintains a strong balance between speed and capacity, outperforming models of similar size and scope.
Performance chart comparing Mistral Small 3.1 to other models on GPQA-Diamond: illustrates a favorable balance of low latency and high performance.
Mistral Small 3.2 (2506) is constructed with 24 billion parameters and leverages the transformer-based structure established by its 3.1 base variant. While the precise dataset composition for this update is not publicly detailed, the training emphasizes instruction tuning atop the pre-existing base, optimizing for general-purpose reasoning, multimodal understanding, and multilingual support.
Instruction tuning continues to be a central feature, enhancing the model's ability to follow complex prompts and integrate context-sensitive behaviors. Improvements in the function calling template are specifically targeted to reduce ambiguity and increase the reliability of integrations with external APIs or computational tools. Vision capabilities are inherited from the instruct-tuned predecessor, supporting image analysis tasks ranging from document inspection to mathematical reasoning.
Applications and Use Cases
Mistral Small 3.2 is designed for a wide range of general-purpose and specialized tasks. Its strong instruction following performance and reduced repetition make it effective in conversational AI, virtual assistance, and structured reasoning workflows. The function calling enhancements facilitate robust tool integration, applicable in scenarios such as automated diagnostics, document verification, and code execution.
Multimodal applications include both image-based reasoning—such as reading and interpreting handwritten mathematical equations—and complex visual inspection requiring context-driven conclusions. The model's multilingual capabilities make it suitable for cross-lingual question answering and content generation. Extended context handling allows practitioners to deploy the model in document parsing, long-form content synthesis, and multimodal streams where high memory capacity is required.
The model architecture and openness also enable research groups and developers to further fine-tune it for specialized domains, including legal or medical support, by leveraging the instruct and base checkpoints as foundational layers for subject matter expertise.
Limitations and Licensing
Although Mistral Small 3.2 introduces improvements in instruction handling and function calling, some metrics related to STEM and vision tasks (e.g., MMLU, GPQA Main, MMMU, Mathvista) experienced marginal declines in this release. These fluctuations are typical in iterative model development and generally do not impact the overall balance of capabilities. No model-specific or architecture-specific limitations are noted beyond those common to large language models, such as susceptibility to hallucination and domain drift in edge cases.
Mistral Small 3.2, like its predecessor, is released under an Apache 2.0 license, permitting broad use and modification for research and commercial purposes.