Launch a dedicated cloud GPU server running Laboratory OS to download and run Llama 4 Maverick (17Bx128E) using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / Llama 4 Maverick (17Bx128E)
Llama 4 Maverick (17Bx128E) is a multimodal large language model developed by Meta featuring a Mixture-of-Experts architecture with 17 billion active parameters from 400 billion total, distributed across 128 experts. The model integrates text and visual information through early fusion and was trained on approximately 22 trillion tokens across 200+ languages, demonstrating strong performance on multimodal reasoning, coding, and multilingual tasks while supporting context lengths up to 1 million tokens.
Explore the Future of AI
Your server, your data, under your control
Llama 4 Maverick (17Bx128E) is a natively multimodal, instruction-tuned large language model (LLM) introduced by Meta as part of the Llama 4 series. Developed for both research and commercial applications, Llama 4 Maverick integrates text and visual information by leveraging sophisticated model architectures and training methodologies. It is optimized for multimodal reasoning, extensive multilingual support, coding, and advanced agentic workflows. This article presents a scientific overview of its technical foundations, benchmark performance, training approaches, and intended applications, while situating the model within the broader Llama 4 family.
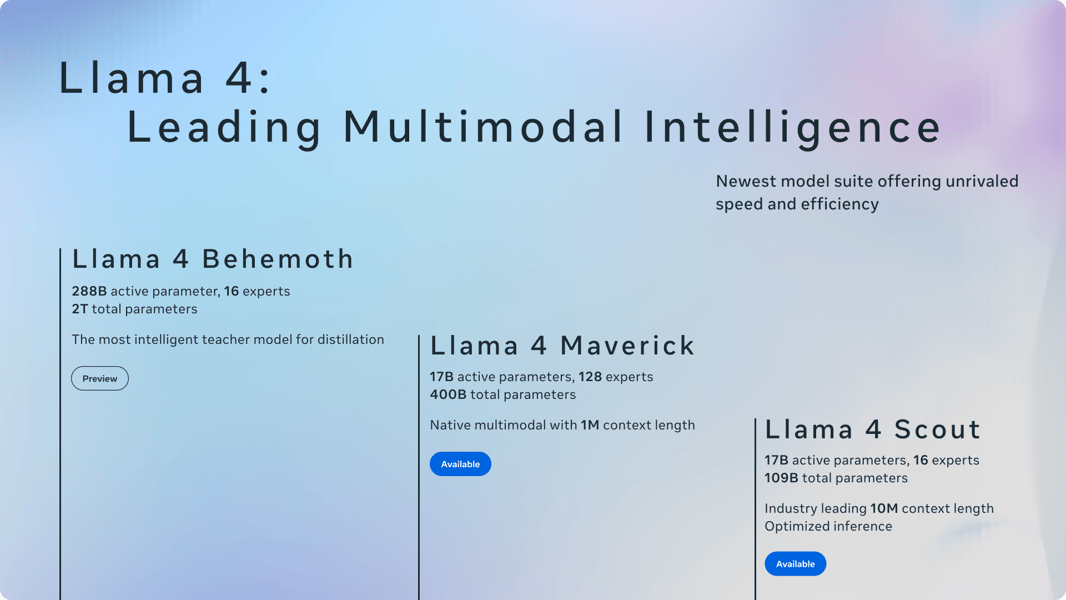
An overview infographic comparing Llama 4 Behemoth, Maverick, and Scout: active parameter counts, expert configuration, and context window sizes underline the Llama 4 suite's multimodal orientation.
Llama 4 Maverick introduces a Mixture-of-Experts (MoE) architecture featuring 17 billion active parameters from a total pool of 400 billion, distributed across 128 experts and a shared expert in each MoE layer. Each input token is processed jointly by the shared expert and one routed expert, enhancing computational efficiency by activating only a subset of model parameters at any time. The architecture leverages interleaved attention layers without standard positional embeddings, instead relying on the iRoPE (interleaved Rotary Positional Embedding) approach and inference time temperature scaling for improved generalization across long sequences.
Multimodal capabilities are enabled through early fusion, allowing seamless integration of text and vision tokens within a unified model backbone. The vision encoder, derived from MetaCLIP, is pre-trained jointly with a frozen Llama backbone to align visual and textual information effectively. Llama 4 Maverick's training pipeline incorporates FP8 numerical precision to maximize computational throughput. For hyperparameter optimization, the novel MetaP training strategy automatically configures per-layer learning rates and initialization scales for model scalability and stability.
Training Methods and Data
The model was pre-trained on approximately 22 trillion tokens of multimodal data, encompassing a broad range of publicly available, licensed, and Meta-generated text, image, and video content. Notably, over 200 languages are represented, with at least 100 languages each contributing more than a billion tokens, resulting in high-coverage multilingual support. The No Language Left Behind initiative informed the construction of these multilingual datasets.
Llama 4 Maverick employed co-distillation from a larger "teacher" model, Llama 4 Behemoth, which features 288 billion active parameters. A custom distillation loss function was developed, dynamically weighting soft and hard training targets to improve generalization. Post-training incorporates lightweight supervised fine-tuning, continuous online reinforcement learning (RL), and direct preference optimization. Additionally, training data was progressively filtered to exclude over 50% of "easy" prompts, focusing learning on more challenging instances as judged by automated model-based assessment.
Performance and Benchmark Results
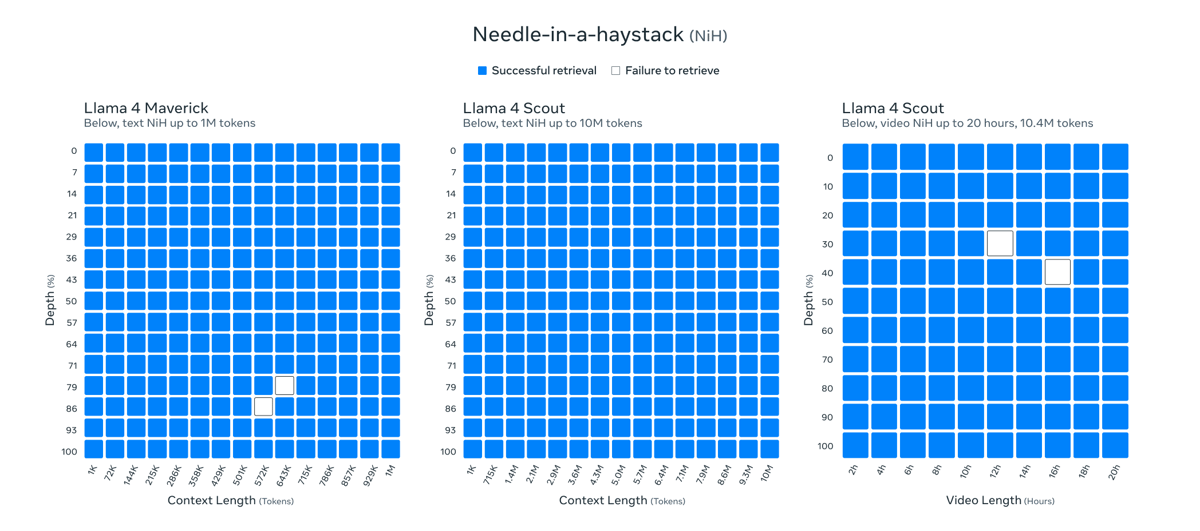
Llama 4 Maverick demonstrates strong results across a comprehensive suite of benchmarks, with particularly notable improvements in multimodal understanding, reasoning, and code generation compared to previous Llama models and contemporary competitors. In the "Needle-in-a-haystack" (NiH) retrieval evaluation, which tests the model's ability to locate relevant information within long context windows, Llama 4 Maverick achieves successful retrieval at context lengths up to 1 million tokens for text data.
Benchmark data visualizing Llama 4 Maverick and Scout's performance on 'Needle-in-a-haystack' retrieval tasks, showing reliable extraction at high context lengths in both text and video modalities. In the left grid, Llama 4 Maverick consistently achieves successful retrieval up to 1M tokens.
Comparative analyses indicate that the model performs competitively or surpasses models such as GPT-4o and Gemini 2.0 Flash on multimodal tasks, while matching DeepSeek v3 on reasoning and coding with fewer active parameters. Experimental chat deployments reported an ELO rating of 1417 on the LMArena leaderboard.
Applications and Usage
Llama 4 Maverick is designed as a general-purpose assistant well-suited for chat applications, sophisticated agentic systems, and tools requiring detailed image and text understanding. It supports multimodal prompts comprising text and up to five images in the instruction-tuned version (tested up to eight images during post-training). The model facilitates advanced use cases such as visual recognition, multi-image reasoning, code synthesis, and multilingual dialogue. Function-calling is supported in both conventional Python-like and JSON formats, enhancing its applicability to tool-enabled agentic environments and workflow automation.
As part of Llama 4's suite, Maverick's outputs are also leveraged for synthetic data generation and downstream model distillation, supporting broader research and model improvement efforts. The system prompt can be customized, aiming to avoid unnecessary refusals while maintaining conversational naturalness and balance.
Limitations and Safety Considerations
Despite improvements in response balance and reduction of refusals on contentious topics, Llama 4 Maverick retains inherent LLM challenges, including potential biases and the generation of inaccurate or harmful content. Image understanding is primarily limited to English captions and queries. While pre-training data spans 200 languages, only a subset are actively supported for high-quality output. The model's performance is validated for up to five images in multimodal input, with additional images requiring developer-led evaluation.
Deployment contexts should incorporate appropriate safety guardrails, given that Llama 4 Maverick is not intended for use in isolation. Alignment with the Acceptable Use Policy, alongside ongoing robustness and trust evaluation—such as through the Llama Guard hazards taxonomy—is recommended for any application.
Licensing
Llama 4 Maverick is distributed under the Llama 4 Community License Agreement, which grants a non-exclusive, worldwide, royalty-free right to use, modify, and create derivative works. Redistribution requires retention of the license, prominent attribution ("Built with Llama"), and compliance with the Acceptable Use Policy. Additional commercial terms apply for deployments exceeding 700 million monthly active users. The agreement does not convey Meta trademarks except where explicitly permitted for compliance. Meta reserves the right to terminate the license in case of noncompliance.
Model Family and Related Models
Llama 4 Maverick is situated between Llama 4 Scout, a compact model optimized for ultra-long context (up to 10 million tokens and 17 billion active parameters), and Llama 4 Behemoth, an experimental teacher model with 288 billion active parameters and a nearly 2-trillion-parameter pool. Performance and input capabilities vary between family members, with Scout excelling at text/video retrieval at scale and Behemoth leading in STEM benchmarks, further informing distillation and training strategies across the suite.