Note: Stable Cascade Stage C weights are released under a Stability AI Non-Commercial Research Community License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Cascade Stage C using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
stabilityai / Stable Cascade Stage C
Stable Cascade Stage C is a text-conditional latent diffusion model that operates as the third stage in Stable Cascade's hierarchical image generation architecture. It translates text prompts into compressed representations within a 24x24 spatial latent space for 1024x1024 images, utilizing CLIP-H embeddings for text conditioning. The stage supports fine-tuning adaptations including LoRA and ControlNet integration for various creative workflows.
Explore the Future of AI
Your server, your data, under your control
Stable Cascade is a generative text-to-image model released by Stability AI, designed to efficiently synthesize high-fidelity images from textual prompts. The model operates within a three-stage cascaded architecture. It incorporates principles of latent diffusion and hierarchical compression. Built upon the Würstchen architecture, Stable Cascade is designed to address inference speed, efficiency, and adaptability considerations, and it is primarily intended for research and creative applications. The model was introduced in a research preview on February 12, 2024, accompanying comprehensive documentation and open-source code to encourage further investigation into large-scale image generation systems (official announcement).
A collage illustrating the variety and artistic diversity of images generated by Stable Cascade.
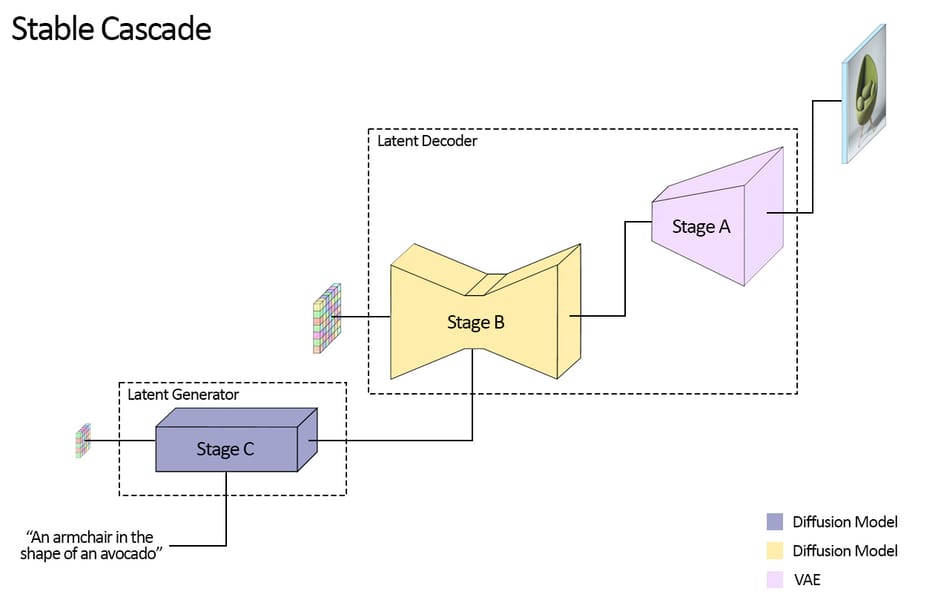
Stable Cascade is structured as a cascade of three primary stages—Stage A, Stage B, and Stage C—each fulfilling a unique role in the transformation from text prompt to high-resolution image. The architecture implements a hierarchical compression scheme, achieving a spatial compression factor of 42:1, compared to models such as Stable Diffusion, which typically achieve 8:1 compression (model architecture overview).
Diagram of Stable Cascade’s three-stage architecture, illustrating the flow from a textual prompt to the final rendered image.
Stage A consists of a VQGAN encoder which compresses images to 256x256 discrete tokens. After initial training, its quantization layer is removed, allowing Stage B access to continuous latent representations (Würstchen architecture details).
Stage B acts as a latent diffusion process, conditional on outputs from a purpose-trained Semantic Compressor and text embeddings. This stage reconstructs fine-grained details in the unquantized latent space of Stage A, employing cross-attention and noise regularization to map semantic information into image latents.
Stage C is a text-conditional Latent Diffusion Model. Operating in a compact 24x24 spatial latent space (for 1024x1024 images), it translates text prompts into the compressed representation from which image synthesis begins. This design aims to accelerate training and inference (detailed technical description).
This modular structure supports customization and downstream finetuning. Enhancements such as LoRA and ControlNet can be primarily trained on Stage C, aiming to minimize computational overhead, while Stage A and B can be adjusted for more specialized workflows.
Technical Capabilities and Key Features
Stable Cascade’s cascaded architecture is designed to support a range of image generation capabilities:
Hierarchical Compression: By encoding 1024x1024 images to a 24x24 latent space, Stable Cascade aims to address memory efficiency and computational speed relative to prior models which use less aggressive compression. This approach is reported to yield a 16-fold reduction in the cost of finetuning tasks when compared to models such as Stable Diffusion 1.5.
Fine-Tuning and Modularity: The model allows researchers and practitioners to adapt Stage C using LoRA, ControlNet, and direct finetuning. This design aims to address overall training time and hardware requirements by focusing updates on Stage C for many adaptation tasks.
Image Variation and Image-to-Image Generation: Stable Cascade provides mechanisms for generating image variations from CLIP embeddings, as well as image-to-image transformations by perturbing a given input image in latent space and synthesizing variants.
Demonstration of Stable Cascade’s image variation feature, generating stylistic and conceptual variants of a given theme.
ControlNet Integration: ControlNet support encompasses inpainting, outpainting, edge guidance, and super-resolution upscaling, facilitating various creative workflows and conditioning on annotated images (ControlNet applications described).
Performance, Metrics, and Evaluation
Stable Cascade's performance has been evaluated in quantitative benchmarks and human preference studies.
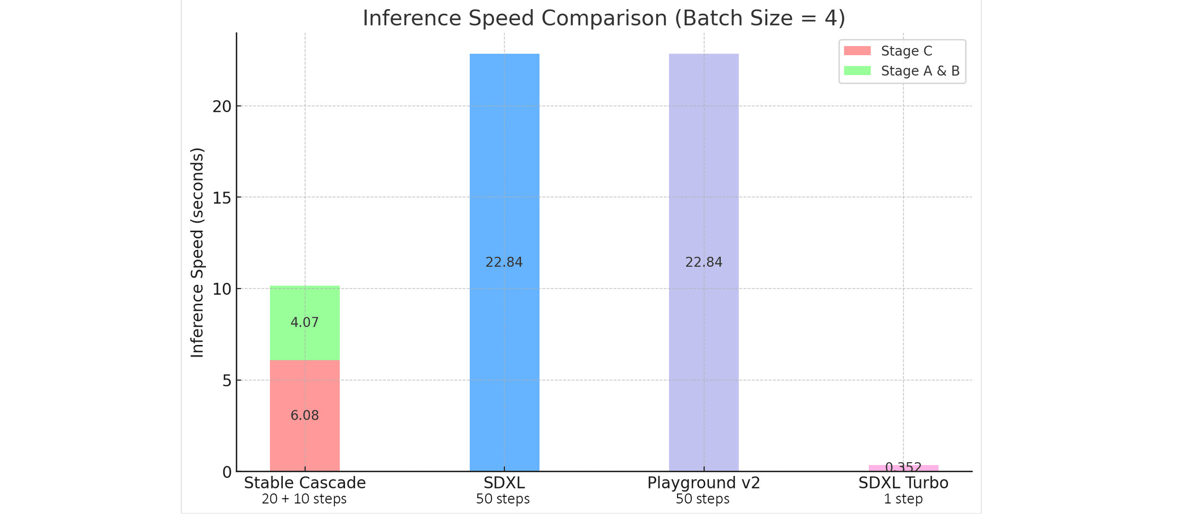
Efficiency and Speed: The model exhibits reduced inference times compared to alternatives such as SDXL and Playground v2, despite having a higher total parameter count. For 1024x1024 images, the end-to-end inference utilizes a compressed latent representation (benchmark comparison).
Bar chart comparing the inference speed of Stable Cascade to SDXL, Playground v2, and SDXL Turbo.
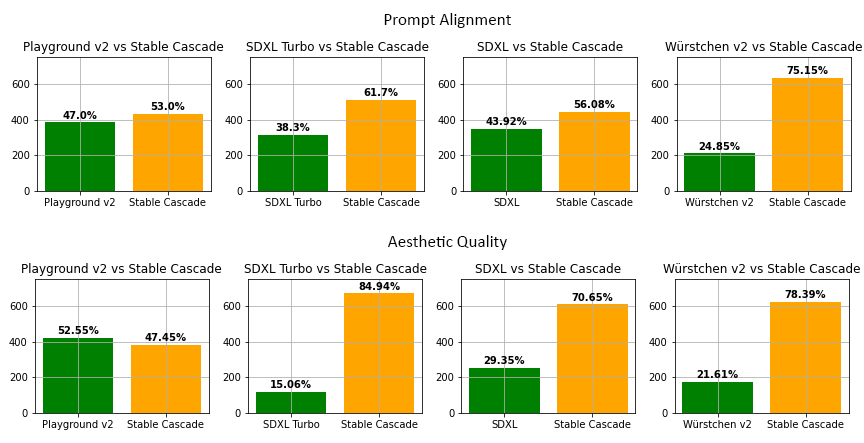
Human Evaluation: In controlled studies using parti-prompts and aesthetic judgments, human evaluators indicated a preference for images generated by Stable Cascade over those from SD 2.1 and other compared models. This was observed across prompt alignment and stylized quality metrics.
Bar charts of Stable Cascade’s performance in prompt alignment and aesthetic quality, showing human evaluation results versus other models.
Automated Metrics: On standard benchmarks such as FID (Frechet Inception Distance), Inception Score (IS), and PickScore, Stable Cascade's results are presented in comparison to several baseline models. For COCO-30K at 256x256, Stable Cascade reports an FID of 23.6 and an IS of 40.9, which is indicated to perform favorably against various latent diffusion and GAN-based models, while its absolute FID remains higher than some more recent large-scale architectures, a characteristic attributed to a tendency to produce smoother images (comprehensive metrics in paper).
Resource Requirements: Training of Stage C required approximately 24,602 GPU hours, a figure which is stated to be lower than the 200,000 GPU hours reported for Stable Diffusion 2.1, a difference attributed to compression and architectural design (training cost analysis).
Training Data and Procedures
Stable Cascade is trained on aggressively filtered subsets of the LAION-5B dataset, with approximately 103 million unique image-text pairs retained after filtering, equating to 1.78% of the raw dataset. This process aims to mitigate ethical concerns and minimize the risk of undesirable content propagation. The stages are trained sequentially in reverse to their application during inference—first Stage A, then Stage B, finally Stage C.
Text Conditioning: For textual inputs, Stable Cascade utilizes CLIP-H embeddings to facilitate correlation between prompt and output.
Semantic Compressor: An ImageNet1k pre-trained EfficientV2 backbone is leveraged for the Semantic Compressor, which is designed to aid the model's capacity to capture and reconstruct fine semantic details in compressed latent space (training procedures detailed).
Applications, Limitations, and Licensing
Stable Cascade is released for research and non-commercial use, intended for generative model research, artistic experimentation, and explorations in efficient large-scale image synthesis (full license terms). Its primary applications lie in creative content generation, educational tools, model probing, and benchmarking workflows focused on safety, efficiency, and prompt controllability.
Notable limitations include:
The model’s high compression ratio introduces a degree of lossiness, occasionally affecting fine compositional details, especially in cases involving text, small objects, or symbols (model limitations).
Images of people and faces may be less reliable compared to broader scene renderings.
Aggressive data filtering has led to a distinct stylistic signature in generated images, characterized by smoother and less textured outputs compared to some alternative models.
The system is not intended to generate factual or event-accurate imagery.
Further Resources
For more information and in-depth technical resources on Stable Cascade, see the following: