Note: Command R+ v01 weights are released under a CC-BY-NC 4.0 License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Command R+ v01 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Cohere / Command R+ v01
Command R+ v01 is a 104-billion parameter open-weights language model developed by Cohere, optimized for retrieval-augmented generation, tool use, and multilingual tasks. The model features a 128,000-token context window and specializes in generating outputs with inline citations from retrieved documents. It supports automated tool calling, demonstrates competitive performance across standard benchmarks, and includes efficient tokenization for non-English languages, making it suitable for enterprise applications requiring factual accuracy and transparency.
Explore the Future of AI
Your server, your data, under your control
Command R+ is a large-scale generative language model developed by Cohere and Cohere Labs, and is an open-weights research release with 104 billion parameters. Designed for enterprise and research applications, Command R+ is designed for Retrieval-Augmented Generation (RAG), tool-use automation, code interaction, and multilingual tasks, seeking to provide efficiency and accuracy for production-scale deployments. The model supports extensive context windows and features to facilitate grounded, transparent, and reliable outputs across a wide range of domains.
Command R+ headline image from Cohere Labs announcing the model's enterprise focus and research capabilities.
Command R+ is built as an auto-regressive transformer-based language model featuring a context window of 128,000 tokens. The model architecture combines extensive pretraining with supervised fine-tuning and preference alignment to optimize for tasks requiring factual accuracy and safe, helpful behavior. Command R+ operates in a text-in, text-out paradigm, accepting and generating only textual content.
A distinguishing aspect of Command R+ is its optimization for Retrieval-Augmented Generation (RAG). The model can integrate retrieved document snippets into its outputs, providing in-line citations to improve factual grounding and minimize hallucinations. It supports two modes for grounded generation: an "accurate" mode that sequences document selection, citation prediction, and span insertion, and a "fast" mode that expedites output with reduced grounding precision.
Advanced tool-use capabilities enable automation by allowing the model to select, call, and interact with external functions—typically APIs, databases, or search engines. Command R+ can perform both single-step (function calling) and multi-step tool use (agent workflows), leveraging iterative action-observation-reflection cycles to accomplish complex, multi-action tasks.
The model was further developed for multilingual coverage, showing evaluated performance in ten languages, with pretraining data spanning over twenty languages. Its tokenizer is specifically engineered to reduce operational costs for non-English content by encoding such text with fewer tokens relative to other models.
Additionally, Command R+ is suitable for code-related tasks, capable of generating, explaining, and rewriting code snippets, especially when using low-temperature or greedy decoding strategies.
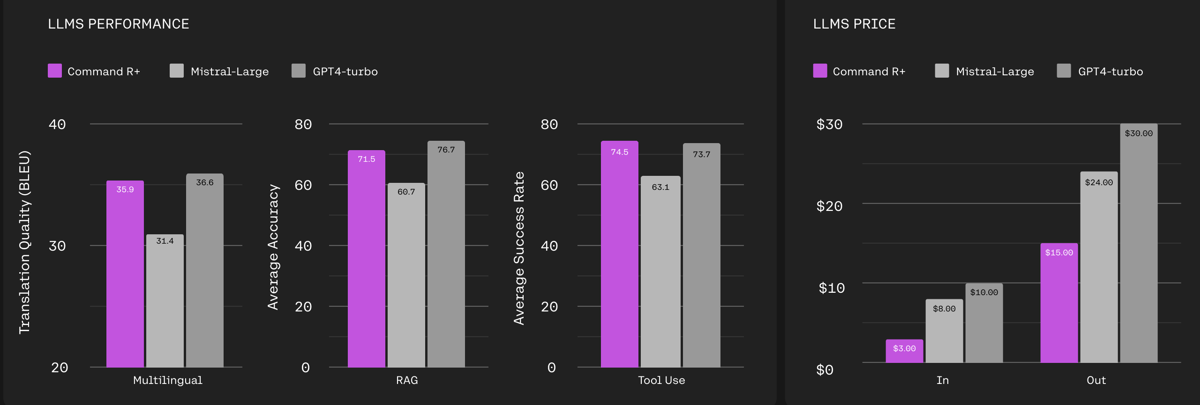
Dashboard comparing Command R+ to other LLMs in translation quality, RAG accuracy, tool use success, and token cost effectiveness.
Command R+ has been evaluated across standardized benchmarks and specialized human assessments, highlighting its strengths in RAG, tool use, and multilingual understanding. On the Open LLM Leaderboard, Command R+ demonstrates competitive results for academic metrics such as ARC Challenge, HellaSwag, MMLU, Winogrande, GSM8k, and TruthfulQA, with an average benchmark score of 74.6.
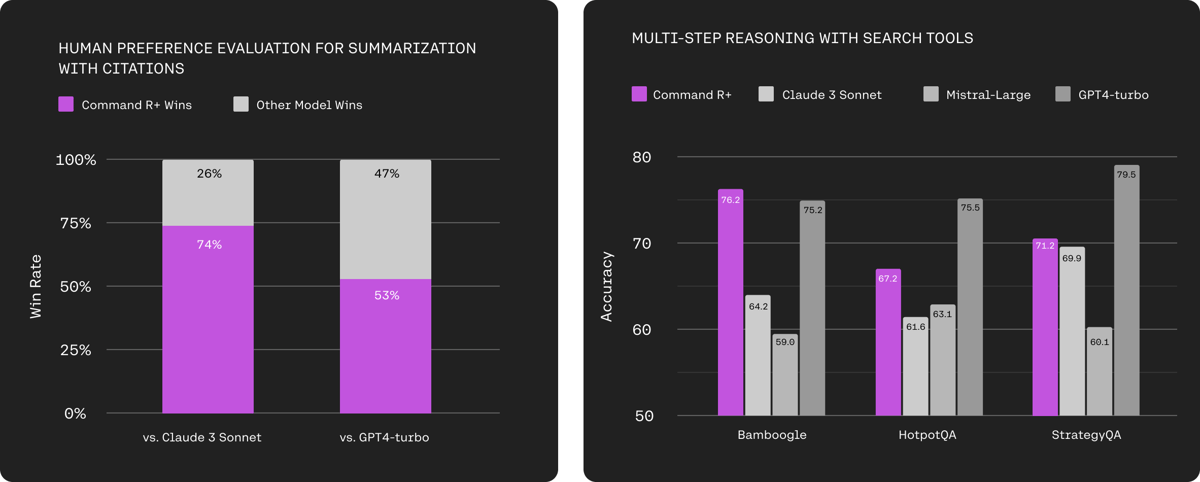
Human evaluations substantiate the model’s RAG capabilities. Command R+ demonstrates performance in tasks requiring document-grounded summarization with citations, as measured against other evaluated models in head-to-head preference assessments. These evaluations not only consider citation quality but also rate overall text fluency and utility for open-ended generation.
Charts demonstrating Command R+'s performance in human preferences for citation-based summarization and multi-step reasoning with external search tools.
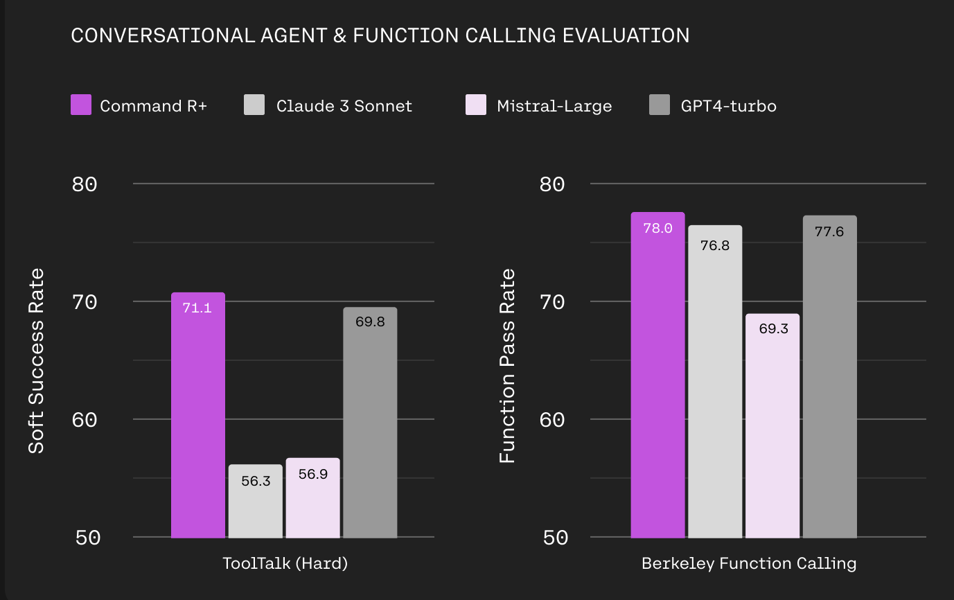
Analyses using ToolTalk (Hard) and the Berkeley Function Calling Leaderboard indicate proficiency in conversational tool use and single-turn function calling. These assessments measure the model's rate of successful function execution within dynamic agent environments.
Command R+ evaluated on ToolTalk (Hard) and Berkeley Function Calling, showing high rates of conversational tool success and function pass compared to leading models.
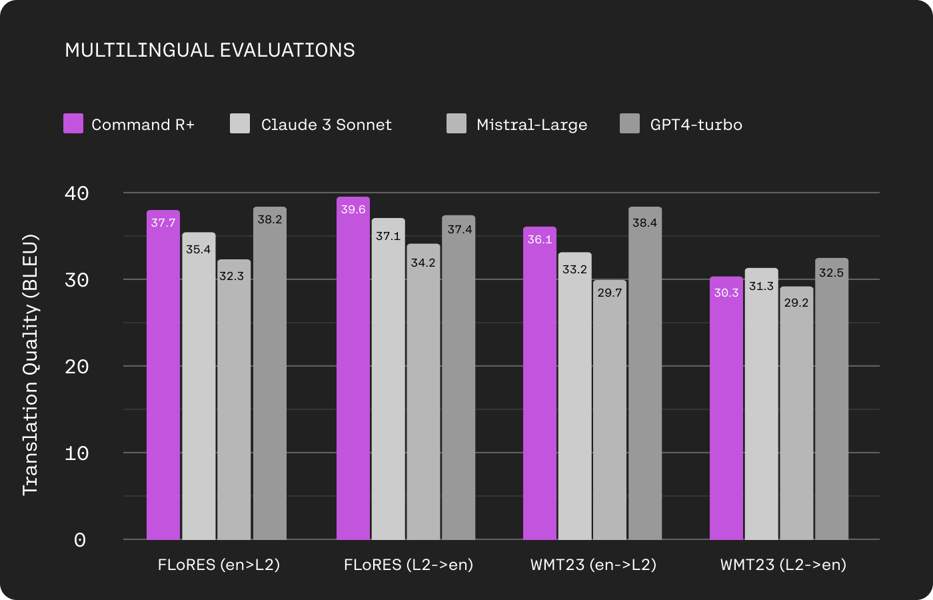
Command R+ also exhibits multilingual translation performance as evaluated on FLoRES and WMT23 tasks, demonstrating competitive BLEU scores for both English-to-L2 and L2-to-English scenarios over a range of languages.
Command R+ multilingual evaluation results across FLoRES and WMT23 translation tasks, compared to Claude 3 Sonnet, [Mistral-Large 2](https://openlaboratory.ai/models/mistral-large-2), and GPT4-turbo.
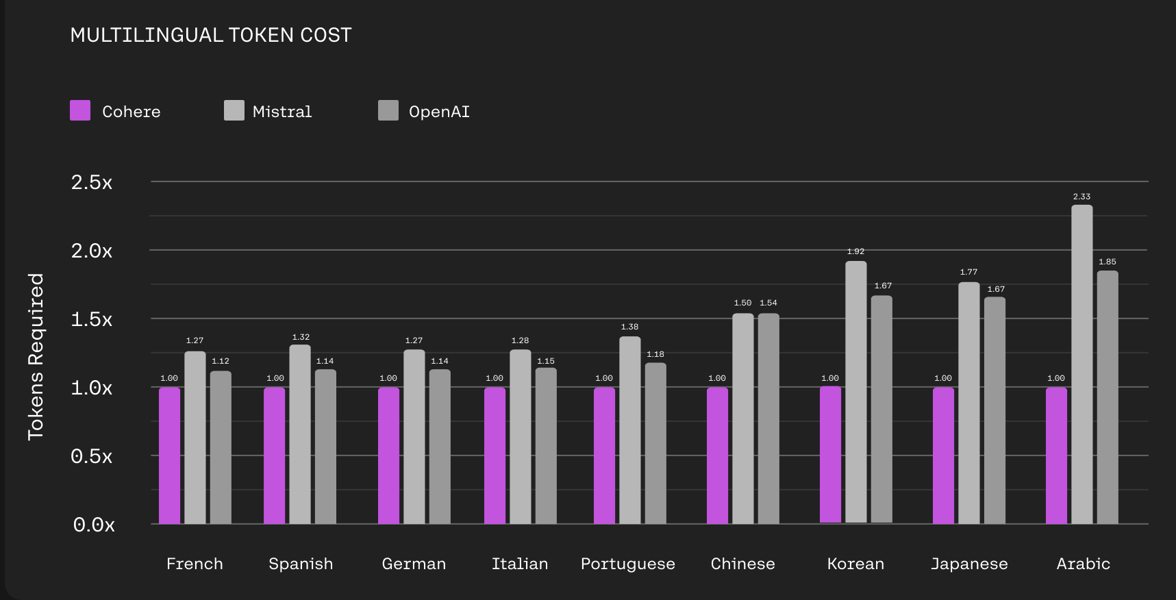
The model’s tokenizer demonstrates efficiency advantages for non-English applications, reducing required token counts—and thus operational costs—relative to Mistral and OpenAI tokenizers for various world languages.
Chart showing token cost multipliers for various tokenizers across non-English languages, highlighting Cohere's tokenizer efficiency in multilingual workloads.
Command R+ leverages an optimized large transformer architecture, pretrained on vast corpora encompassing multiple domains and languages. Its training pipeline integrates supervised fine-tuning (SFT) and preference training, which incorporates human feedback to enhance model helpfulness, factuality, and safety. The model’s RAG and tool-use specializations are a result of targeted fine-tuning, equipping it for document-grounded tasks and robust function-calling protocols.
Extensive multilingual support is achieved through both pretraining—drawing from resources covering more than twenty languages—and tokenizer engineering, yielding improved tokenization efficiency for non-Latin scripts and underrepresented languages.
Applications and Use Cases
Command R+ is tailored for enterprise tasks and research applications where reliability and factuality are considerations. Primary use cases include open-domain and document-grounded question answering, complex summarization with cited sources, agent-based workflows involving external tool invocation, and textual interactions involving code review, generation, and rewriting.
Its multilingual capabilities allow for deployment in global, cross-lingual environments. The model also supports automation scenarios, such as updating CRM records or orchestrating business workflows requiring sequential tool calls and reasoning steps. By supporting RAG with accurate, retrievable source citations, Command R+ can be used for applications demanding transparency and verifiability in responses.
For those requiring quantization, Command R+ is also available in 4-bit format to balance performance with memory efficiency.
Limitations
While Command R+ achieves results across RAG, tool use, and multilingual benchmarks, certain limitations are noted. Code completion may be less optimal, and standard LLM benchmarks do not comprehensively reflect RAG or tool-use capabilities. To preserve performance, strict adherence to specified prompt and chat templates for task-specific generation is recommended.