Note: Stable Cascade Stage B weights are released under a Stability AI Non-Commercial Research Community License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Cascade Stage B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
stabilityai / Stable Cascade Stage B
Stable Cascade Stage B is an intermediate latent super-resolution component within Stability AI's three-stage text-to-image generation system built on the Würstchen architecture. It operates as a diffusion model that upscales compressed 16×24×24 latents from Stage C to 4×256×256 representations, preserving semantic content while restoring fine details. Available in 700M and 1.5B parameter versions, Stage B enables the system's efficient 42:1 compression ratio and supports extensions like ControlNet and LoRA for enhanced creative workflows.
Explore the Future of AI
Your server, your data, under your control
Stable Cascade Stage B is a key component within the Stable Cascade generative text-to-image model suite developed by Stability AI and built upon the Würstchen architecture. This diffusion-based model system is distinguished by its highly compressed latent space and multi-stage cascaded structure, delivering improvements in computational efficiency while maintaining high output fidelity. Stage B, in particular, serves as the intermediate latent super-resolution module, bridging the low-dimensional outputs of Stage C (the text-conditional latent generator) and the reconstruction capabilities of Stage A (the pixel-space decoder).
A collage of diverse images generated using Stable Cascade, demonstrating its versatility across various subjects, compositional styles, and artistic approaches.
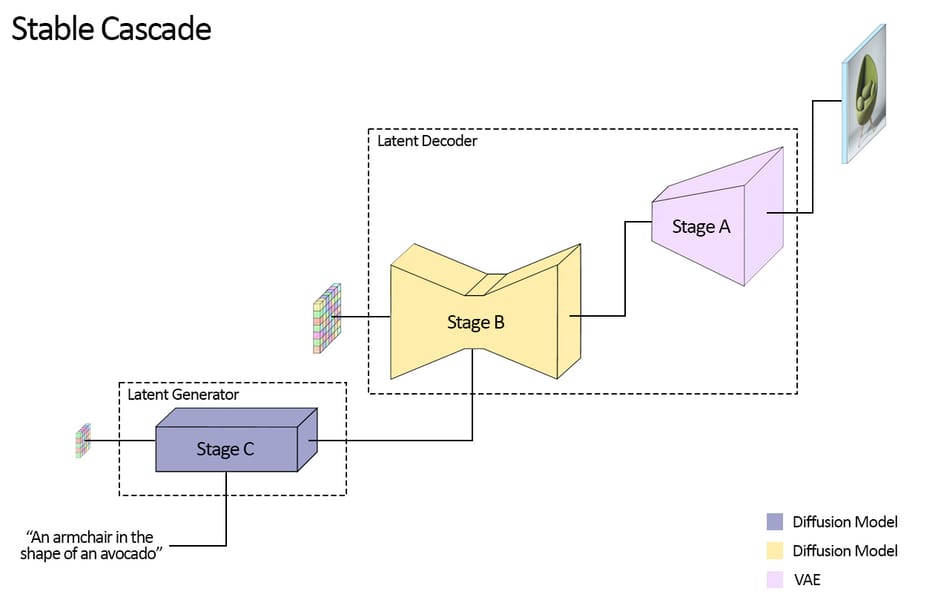
The Stable Cascade architecture is decomposed into three primary stages: Stage C (latent generator), Stage B (latent super-resolution), and Stage A (VQGAN-based latent decoder). Stage B receives compressed latents from Stage C—specifically, a 16×24×24 tensor for a 1024×1024 resolution image—and performs upsampling to a more detailed, less-compressed latent representation (4×256×256), preparing these for eventual decoding into full-resolution images by Stage A.
Diagram illustrating the three-stage architecture of Stable Cascade, with Stage C generating text-conditional latents, Stage B performing super-resolution in latent space, and Stage A decoding to final images.
Stage B operates as a diffusion model in the latent domain, functioning as a semantic compressor and super-resolver. It leverages conditioning from both the high-level latents generated by Stage C and the input text embeddings, allowing it to reconstruct small-scale features and fine-grained details that would be lost at high compression ratios. Two primary configurations of Stage B exist: a 700-million parameter version and an enhanced 1.5-billion parameter variant, the latter offering improved detail retention according to benchmark results.
The core of Stage B is a diffusion process that upscales heavily compressed representations while preserving alignment with the original text prompt and semantic content, a process referred to as "latent super-resolution" in the Würstchen architecture paper. A dedicated encoder network, initialized with ImageNet-pretrained weights, facilitates the creation of these highly informative latents.
Training Methodology and Data
All stages of Stable Cascade, including Stage B, are trained on a carefully filtered subset of the LAION-5B dataset. This subset underwent aggressive de-duplication and filtering to remove duplicate, inappropriate, watermarked, or low-quality content, ultimately yielding about 103 million unique image-text pairs from the original 5 billion. During training, images below 512×512 resolution were discarded, and further aesthetic and safety filtering was enforced to optimize for model robustness.
Stage B training utilized the Denoising Diffusion Probabilistic Models (DDPM) algorithm to facilitate iterative denoising and upsampling in the latent space. The implementation incorporated classifier-free guidance to enable more flexible and prompt-aligned sampling, with some training steps intentionally dropping the text condition to improve generalization.
Computationally, Stage B required approximately 11,000 A100-GPU hours for training, a figure notably lower than that required for earlier diffusion-based models such as Stable Diffusion, reflecting the efficiency gains of the cascaded architecture.
Technical Capabilities and Extensions
Stage B's principal function is to enhance the semantic and visual quality of intermediate latents. By operating as a bridge between a highly compressed representation and near-pixel-level detail, it enables the overall system to compress an image at a 42:1 ratio—from 1024×1024 to 24×24 at Stage C—then incrementally restore detail with reduced computational overhead. This stands in contrast to previous generative diffusion models, such as Stable Diffusion, which typically operate at a much lower compression factor (8:1 for the same resolution).
A key feature of Stage B is its modularity, supporting independent training or fine-tuning from the other stages. This design facilitates extensibility with popular conditioning and control frameworks, such as LoRA, ControlNet, and IP-Adapter, thus supporting creative workflows like inpainting, outpainting, edge conditioning, and super-resolution.
Generated image variations on a core concept, showcasing Stage B's support for semantic image transformation and detail refinement.
Visualization of the 2x Super Resolution feature, with insets highlighting the improved facial details and fur textures attributable to Stage B's upscaling.
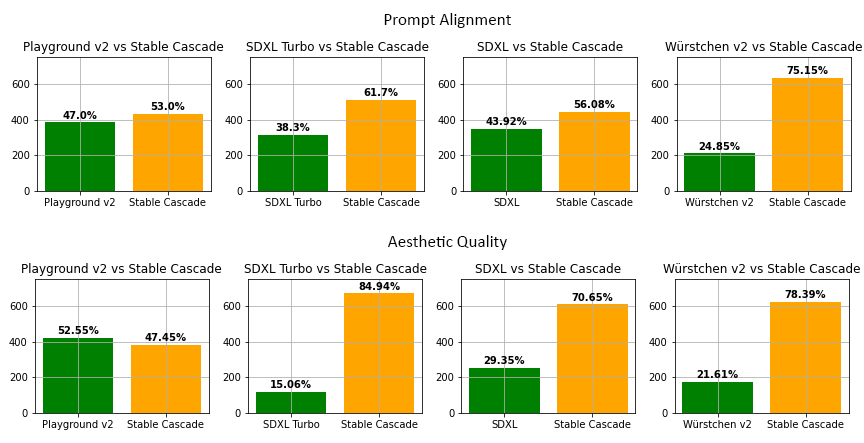
Extensive benchmarking of Stable Cascade and its constituent stages, including Stage B, has been conducted using established metrics such as Inception Score (IS), Fréchet Inception Distance (FID), and human preference evaluations. According to published evaluations, Stable Cascade demonstrates strong prompt alignment and aesthetic quality when compared to other leading generative models such as Playground v2, SDXL, SDXL Turbo, and Würstchen v2.
Bar charts reflecting Stable Cascade's comparative performance in human-rated prompt alignment and aesthetic quality against several other state-of-the-art models.
On the COCO-30k dataset, Stable Cascade achieved an Inception Score of 40.9, slightly surpassing earlier models in this comparison class, though with a higher FID of 23.6, a tradeoff attributed to smoother generated visuals. Human evaluators expressed a preference for Stable Cascade's outputs, particularly in scenarios measured by the parti-prompts dataset.
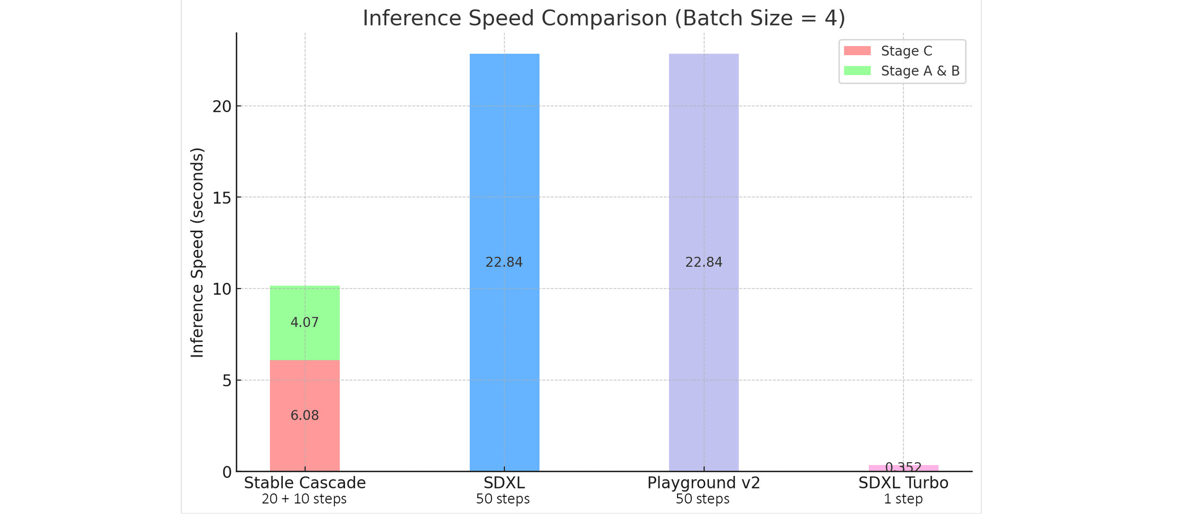
Importantly, inference speed is another domain where the system excels. Despite the large model size, the total inference latency for a 1024×1024 image is substantially reduced compared to previous generation diffusion models.
Comparison of inference speeds for Stable Cascade, SDXL, Playground v2, and SDXL Turbo at the same batch size, illustrating the efficiency gains from the cascaded design.
Stage B, while an effective module for upscaling semantic latents and integrating prompt context, does have inherent constraints. The aggressive compression used by preceding stages (especially Stage C) can challenge the fidelity of spatial compositions, such as rendering legible text or precise object quantities. Its autoencoding process remains lossy, which may limit fine-grained reconstruction in highly detailed regions. Additionally, due to the filtering of the LAION-5B dataset, certain visual styles may be over-represented in outputs.
The model is intended solely for research and non-commercial use, as governed by the Stability AI acceptable use policy. Its outputs are not guaranteed to be factual depictions of real individuals or events.
Applications
Stage B supports a range of creative and scientific workflows within the broader Stable Cascade system. Common research applications include:
Text-to-image synthesis for artistic, aesthetic, or creative design.
Image variation and transformation, using reference images or embeddings.
Image-to-image generation, including inpainting, style transfer, and edge-based guidance.
Super-resolution tasks, leveraging latent upscaling for higher resolution outputs.
These capabilities are extended through integration with open-source libraries and conditioning methods, making it a flexible tool for experimentation with image generation.
Release and Availability
Stable Cascade and its components, including Stage B, are available under a non-commercial research license. The Würstchen architecture paper was first made public in January 2024, with Stage B's algorithms and models detailed in both the main paper and accompanying technical documentation. Source code, pretrained model weights, and further documentation are provided to the research community for transparent evaluation and independent study.