Launch a dedicated cloud GPU server running Laboratory OS to download and run ControlNet 1.5 IP Adapter using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
tencent / ControlNet 1.5 IP Adapter
ControlNet 1.5 IP Adapter is a lightweight extension that adds image prompting capabilities to text-to-image diffusion models through decoupled cross-attention mechanisms. Developed by Tencent, it enables generation conditioned on input images alone or combined with text prompts while maintaining compatibility with existing frameworks like ControlNet. The adapter uses CLIP-based image encoders and introduces parallel cross-attention modules for image features alongside existing text pathways, requiring only 22 million additional parameters when frozen base models remain unchanged.
Explore the Future of AI
Your server, your data, under your control
ControlNet 1.5 IP Adapter, often termed IP-Adapter, is a lightweight and modular extension that enables pre-trained text-to-image diffusion models to incorporate image prompt capabilities. This adapter facilitates generating images conditioned on an input image, alone or in combination with a text prompt, and is compatible with major controllable image synthesis frameworks, including ControlNet and T2I-Adapter. Its design expands the flexibility and controllability of diffusion-based image generation while maintaining architectural efficiency.
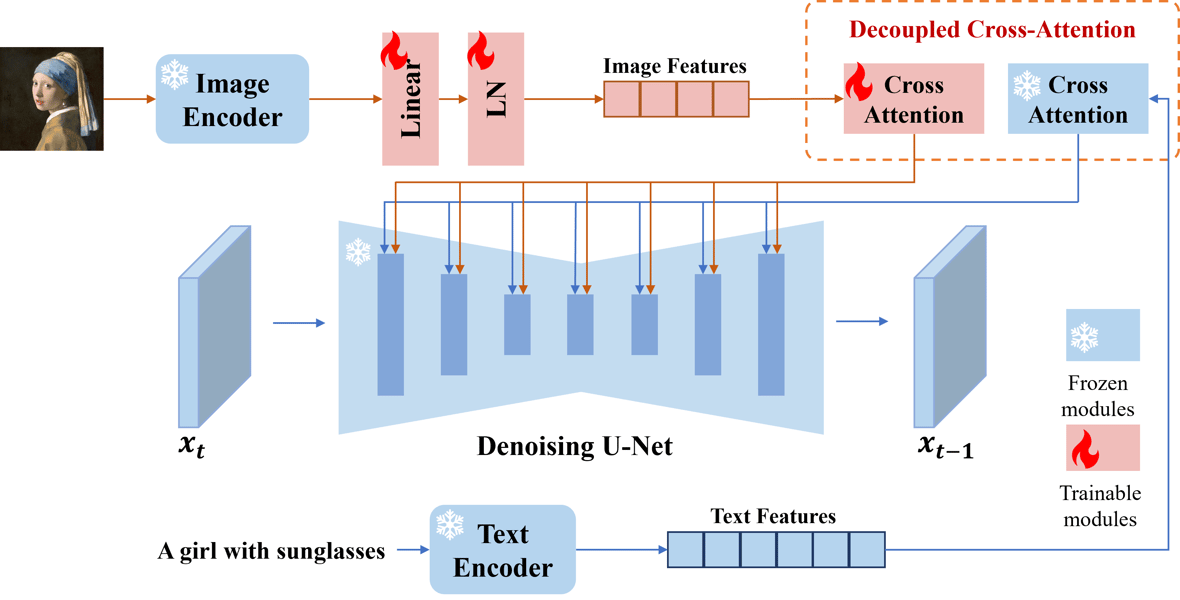
IP-Adapter architecture: A technical schematic highlighting the integration of its cross-attention modules within a diffusion-based text-to-image model. The flow from text and image inputs to the denoised image is detailed, distinguishing frozen and trainable components.
The IP-Adapter introduces a decoupled cross-attention mechanism within the UNet backbone of diffusion models. In the original architecture, all cross-attention layers handle only text features; IP-Adapter adds parallel cross-attention modules dedicated to image features. This augmentation allows the model to embed both modalities concurrently without altering the pretrained diffusion core, ensuring compatibility with existing checkpoints and minimizing additional parameter overhead.
The adapter uses a CLIP-based image encoder—such as OpenCLIP-ViT-H-14 or OpenCLIP-ViT-bigG-14, depending on the base diffusion model—to extract global image embeddings from the prompt. These embeddings are mapped into sequences compatible with the diffusion U-Net using a trainable projection network. For each cross-attention layer, IP-Adapter supplements the text-attention pathway with an image-attention pathway. The outputs from both pathways are combined, and during training, only the new image cross-attention modules are updated while the original model remains frozen. This results in a highly parameter-efficient design, with the main SD 1.5 IP-Adapter containing approximately 22 million trainable parameters, a fraction compared to models fully fine-tuned for image prompting, as described in the IP-Adapter paper.
Training Data and Methodology
IP-Adapter was trained on a large-scale multimodal dataset, incorporating approximately 10 million text-image pairs derived from the LAION-2B and COYO-700M datasets. For SDXL versions, a two-phase training strategy was implemented: initial pretraining at 512x512 resolution, followed by fine-tuning with randomly scaled images, as detailed in the project documentation. Images were resized and center-cropped for uniformity, and classifier-free guidance was achieved by randomly ablated prompts during training.
The primary base model for adaptation was Stable Diffusion 1.5, and fine-tuning was performed using techniques such as DeepSpeed ZeRO-2 for efficiency. Learning rates, batch sizes, and optimizer settings were carefully selected to balance convergence speed and generalization, with extensive use of modern open-source optimization libraries.
Capabilities and Applications
The integration of image-prompted guidance endows diffusion models with new operations, including image variation, hybrid multimodal prompting, image-to-image translation, and structural conditioning through conjunction with external guidance such as depth maps or edge detectors.
Demonstration of image variation: An original portrait serves as an image prompt, producing diverse yet consistent variations with stylistic and detail preservation. Input: Portrait of a red-haired woman in armor.
A primary application is generating diverse variations from a single image, allowing exploration of style, pose, or environmental changes while retaining core subject identity. IP-Adapter's decoupled multimodal cross-attention permits the seamless blending of text and image prompts, enabling fine-grained control over content and scene modification.
Image-to-image generation: The style of 'Girl with a Pearl Earring' is applied to an aerial beach photograph, yielding outputs that blend content from the beach image with painterly elements from the artwork.
Inpainting example: Missing facial regions in an artistic portrait are reconstructed using features extracted from a source photograph, blending source and artwork in the inpainting output.
IP-Adapter can also be combined with external structural guides (such as edge maps or depth information) by leveraging ControlNet. This supports tasks like structural generation and translation, allowing reference images to influence both the style and structure of new outputs.
Structural prompt application: A marble bust and a depth map are jointly used as prompts, producing novel busts that adhere to the provided structure.
Another capability is robust multimodal generation, in which image and text prompts are fused to modulate both the appearance and context of the output.
Multimodal prompt fusion: An armored portrait and a text prompt, 'wearing a hat on the beach,' drive generation of outputs that combine visual identity with textual content.
The model can also perform image-to-image translation, inpainting, and structural compositing, among other foundational visual tasks.
Evaluation and Performance
Quantitative evaluation of IP-Adapter's effectiveness is conducted on established benchmarks such as the COCO2017 validation set, using metrics based on CLIP image embedding similarity (CLIP-I) and CLIPScore (CLIP-T) to assess semantic and visual alignment with prompts. Across these metrics, the adapter demonstrates strong performance, closely matching or exceeding more computationally demanding fine-tuned models, despite its relatively compact parameter count. For example, the IP-Adapter with Stable Diffusion 1.5 achieves CLIP-T and CLIP-I scores that are competitive with or better than models trained from scratch or fully fine-tuned for image prompting.
Qualitative comparisons confirm that IP-Adapter is capable of producing high-fidelity, contextually relevant images, maintaining both the global structure and stylistic features of the input prompt while allowing expressive variation.
Direct visual comparison: Image prompts and outputs across IP-Adapter, Reimagine XL, and prior models, highlighting consistency and style transfer across diverse subjects.
IP-Adapter offers several variants tailored for Stable Diffusion 1.5 and SDXL, including models specialized for face images and those using fine-grained, patch-based embeddings for detailed structure retention. The adapter modules can be directly applied to a variety of models derived from the same base, supporting broad compatibility without retraining. For instance, community fine-tuned checkpoints such as Realistic Vision can be augmented with image prompt capabilities with minimal setup.
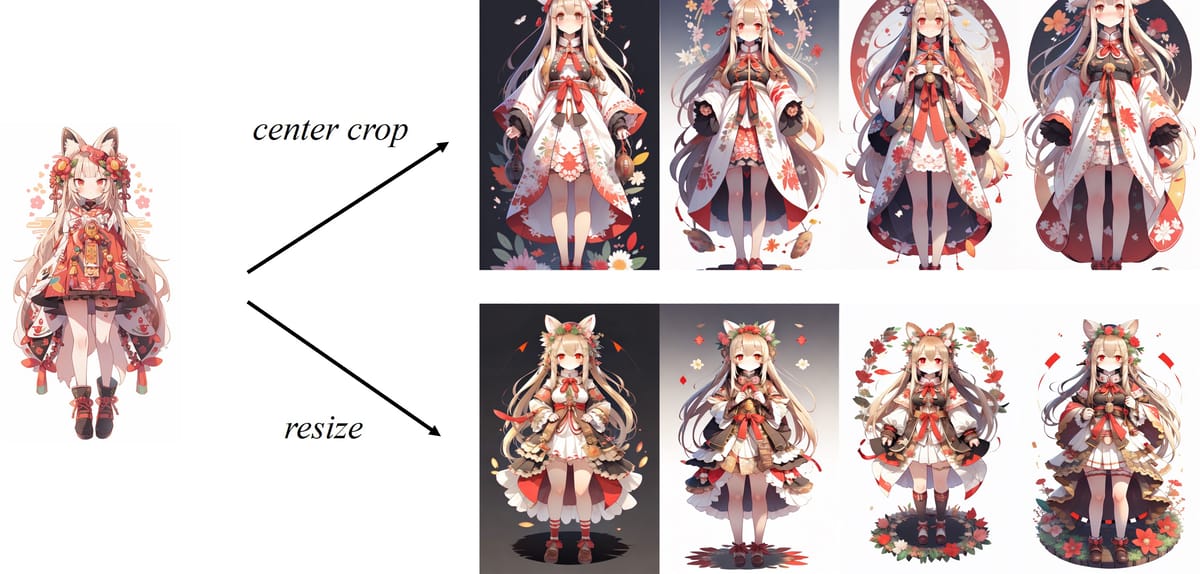
The default CLIP-based processing pipeline uses center cropping for non-square input images, potentially omitting peripheral details; resizing images to 224x224 offers a workaround, but with a trade-off in content preservation. While the model excels in transferring stylistic and content features, its capacity for strict subject identity preservation lags behind subject-specialized methods such as DreamBooth. Additionally, the use of fine-grained features, though beneficial for fidelity, may reduce the diversity of generated samples.
Effect of center cropping vs. resizing: Output variations from an anime character input show different results based on input preprocessing strategy.
The initial public release of IP-Adapter models and code occurred on August 16, 2023, with subsequent updates introducing SDXL support, fine-grained and face-specific adapters, and training code. Official support was later added to widely-used diffusion model UIs and libraries, such as Diffusers and ComfyUI. The project is published under the Apache-2.0 license, promoting open research and community contribution.