Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek Coder V2 Lite using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek Coder V2 Lite
DeepSeek Coder V2 Lite is an open-source Mixture-of-Experts code language model featuring 16 billion total parameters with 2.4 billion active parameters during inference. The model supports 338 programming languages, processes up to 128,000 tokens of context, and demonstrates competitive performance on code generation benchmarks including 81.1% accuracy on Python HumanEval tasks.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-Coder-V2-Lite is an open-source Mixture-of-Experts (MoE) code language model developed by DeepSeek-AI as part of the DeepSeek-Coder-V2 series. Designed for code generation, reasoning, and understanding, it offers a range of capabilities tailored to software development and computational problem-solving across a multitude of programming languages. The model is distinguished by its efficient parameter utilization and extended context processing, which enable sophisticated code intelligence while minimizing computational overhead.
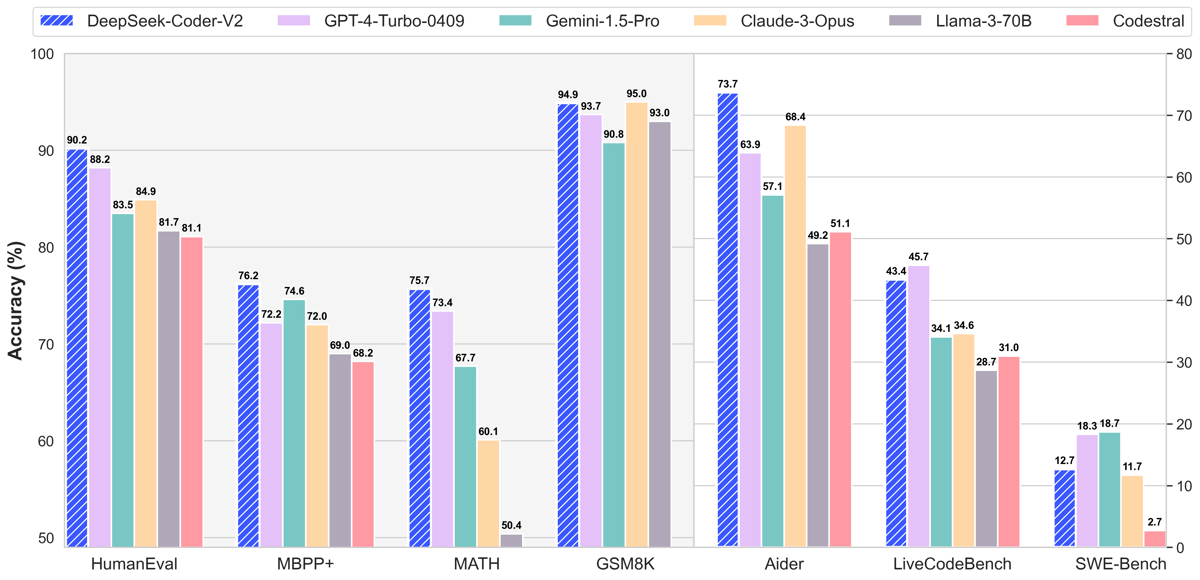
Comparison of coding and mathematical benchmark accuracy for DeepSeek-Coder-V2 and several contemporaries, including HumanEval, MBPP+, MATH, GSM8K, Aider, LiveCodeBench, and SWE-Bench.
DeepSeek-Coder-V2-Lite is constructed using a Mixture-of-Experts (MoE) architecture, featuring 16 billion total parameters with 2.4 billion active parameters engaged during inference. This architecture balances performance and efficiency, supporting diverse code-related tasks while reducing computational resource demands. The model explicitly supports 338 programming languages, a substantial expansion from the 86 languages available in its predecessor, as documented in the supported languages list.
A technical feature of DeepSeek-Coder-V2-Lite is its extended context length, supporting up to 128,000 tokens per input. This capability, achieved through the Yarn technique with tuned hyperparameters, permits the model to handle complex and extensive codebases and documentation, facilitating comprehensive code completion and reasoning. Additionally, it is trained with a 0.5 fill-in-the-middle (FIM) rate, enabling it to fill gaps within provided code blocks using surrounding context, a feature particularly relevant for code editors and automated refactoring tools. The underlying model architecture closely mirrors DeepSeek-V2, with refinements to normalization strategies implemented to ensure training stability.
Training Data and Pre-training Techniques
DeepSeek-Coder-V2-Lite is further pre-trained from an intermediate DeepSeek-V2 checkpoint, exposing it in total to approximately 10.2 trillion high-quality tokens. The pre-training data is composed of 60% source code (principally curated from public GitHub repositories), 10% mathematical corpora, and 30% general natural language, as detailed in the model's technical paper. The code corpus is filtered and deduplicated to maximize quality, while the mathematical and web-based code data are collected from forums, documentation sites, and mathematics platforms by leveraging iterative classification techniques and fastText models for relevant content discovery.
The model utilizes a Byte Pair Encoding (BPE) tokenizer, consistent with the broader DeepSeek-V2 series, to efficiently support a wide variety of languages, including those without space-delimited word boundaries. Training objectives comprise next-token prediction and FIM with Prefix, Suffix, Middle (PSM) mode, enhancing its versatility in code completion scenarios. Optimization is performed using the AdamW algorithm with specific moment and weight decay parameters, while a cosine learning rate decay is applied during training.
For alignment, DeepSeek-Coder-V2-Lite undergoes supervised fine-tuning on code, math, and general instruction datasets, followed by a reinforcement learning phase. Here, preference data is generated using compiler feedback and bespoke reward models, directing the model towards more contextually appropriate and robust outputs.
Benchmark Performance
DeepSeek-Coder-V2-Lite demonstrates competitive results across a spectrum of code and language benchmarks, as outlined in the public evaluation results. On HumanEval and MBPP+ code generation tests, the model achieves an average accuracy of 65.6% across multiple programming languages, surpassing the performance of earlier models, including the DeepSeek-Coder-33B. In Python-specific HumanEval tasks, it attains 81.1% accuracy, and similar strong results are observed across Java, C++, C#, and TypeScript.
In code completion (RepoBench v1.1), DeepSeek-Coder-V2-Lite registers 38.9% accuracy for Python and 43.3% for Java over various context lengths, matching or exceeding previous DeepSeek variants despite a lower active parameter count. Fill-in-the-middle (FIM) capabilities achieve a mean score of 86.4% across Python, Java, and JavaScript, highlighting the effectiveness of FIM training. On code repair, the model achieves 44.4% with Aider and also reports measurable results for code understanding tasks (CRUXEval) and competitive programming tasks (LiveCodeBench, USACO).
The model's capacity for mathematical reasoning is demonstrated by an 86.4% score on GSM8K and 61.8% on the MATH benchmark. For general natural language tasks, DeepSeek-Coder-V2-Lite is strong on reasoning-heavy benchmarks such as BBH and Arena-Hard, though it underperforms on knowledge-intensive datasets such as TriviaQA and NaturalQuestions, likely due to the relative emphasis on code and mathematical data during pre-training.
Use Cases and Applications
DeepSeek-Coder-V2-Lite is intended for a wide array of automated programming tasks and computational reasoning applications. Its code generation and completion capabilities make it suitable for assisting in software development environments, enabling features such as context-aware code suggestion, insertion, and refactoring. The FIM-enabled architecture enhances code editing workflows, allowing for insertion or modification of code blocks within larger files based on provided context.
Beyond code-centric tasks, the model's mathematical and logical reasoning skills enable applications in algorithmic problem solving, educational tutoring for programming and mathematics, and even general-purpose text understanding and generation when natural language context is involved. The extended context window further supports handling of large codebases or technical documentation within single inference sessions.
Limitations
Despite its broad capabilities, DeepSeek-Coder-V2-Lite exhibits some notable limitations, as described in the official documentation. The model presents a discernible gap in instruction-following ability relative to systems such as GPT-4 Turbo, particularly in complex, open-ended scenarios like those evaluated by the SWE-Bench. Its performance also declines in highly knowledge-intensive constraints, a reflection of the focused nature of its training data. Finally, while the active parameter count ensures efficiency, running full large-scale DeepSeek models may require substantial computational resources for local inference.
Licensing
The DeepSeek-Coder-V2 codebase is released under the MIT License, while the model weights are licensed separately; the latter permit commercial use under specified conditions.