Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 2.5 72B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 2.5 72B
Qwen 2.5 72B is a 72.7 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, released in September 2024. The model features a 128,000-token context window, supports over 29 languages, and demonstrates strong performance on coding, mathematical reasoning, and knowledge benchmarks. Built with architectural improvements including RoPE and SwiGLU activation functions, it excels at structured data handling and serves as a foundation model for fine-tuning applications.
Explore the Future of AI
Your server, your data, under your control
Qwen2.5-72B is a large language model in the Qwen series developed by Alibaba Group’s Qwen Team. Released in September 2024, it represents an extensively scaled, dense, decoder-only transformer architecture designed to facilitate a broad range of natural language processing tasks. Qwen2.5-72B supports a significant context window, robust multilingual capabilities, and improved handling of structured data. Its architecture and training regime allow it to deliver strong performance across established linguistic, coding, and mathematical benchmarks, positioning it as a versatile component within the open-source AI ecosystem.
This official video presents an overview of the Qwen2.5 series, highlighting its principal capabilities and improvements within the Qwen model family. [Source]
Model Architecture and Technical Specifications
Qwen2.5-72B is built on a causal transformer framework, integrating technologies such as Rotary Position Embeddings (RoPE), SwiGLU activation functions, RMSNorm normalization, and attention mechanism enhancements including QKV bias. The model features 72.7 billion parameters, of which 70 billion are allocated exclusively to non-embedding roles, reflecting a focus on scalable inference and generation performance. This architecture supports a maximum context length of 128,000 tokens and provides output sequences up to 8,000 tokens in length, accommodating both brief and extended conversational or document-based tasks.
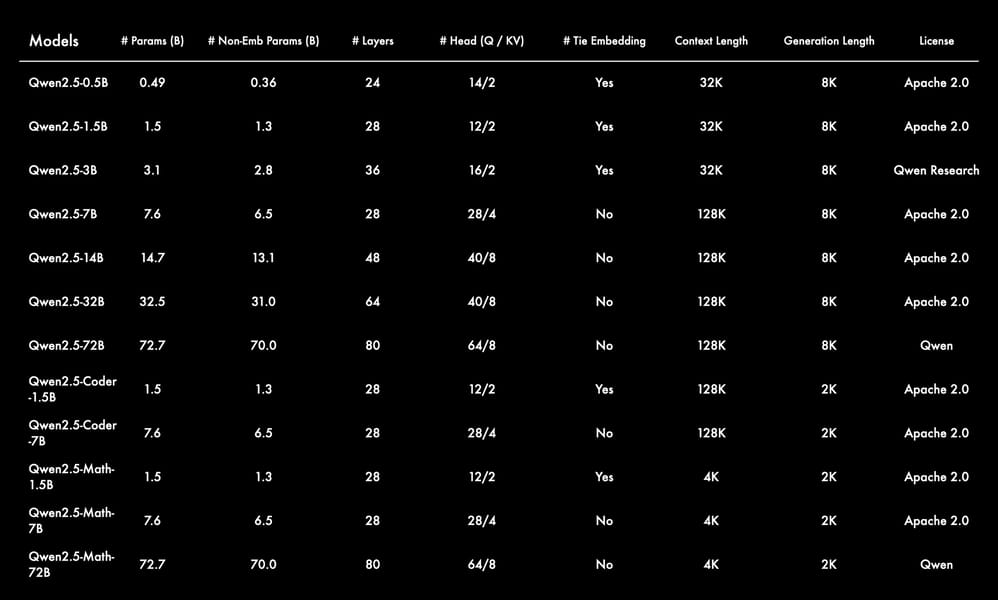
Specification table for Qwen2.5, listing model sizes, parameters, layer counts, head configuration, context lengths, generation lengths, and available specialized variants, including Qwen2.5-Coder and Qwen2.5-Math.
Qwen2.5-72B is licensed under the Apache 2.0 license, encouraging open research and development initiatives. The model is provided as a base version, meaning it is optimally used as a foundation for further post-training processes such as supervised fine-tuning or reinforcement learning from human feedback.
Training Regimen and Model Capabilities
Qwen2.5 models are pretrained on a massive corpus comprising up to 18 trillion tokens, encompassing diverse textual domains and over 29 languages. This extensive pretraining confers a pronounced aptitude for multilingual tasks, allowing the model to process and generate text in languages including Chinese, English, French, Spanish, German, Russian, Japanese, Korean, Arabic, Vietnamese, and Thai. The model architecture exhibits significant improvements in structured data comprehension, particularly for extracting and generating table-based and JSON-formatted content, facilitating robust interactions with structured enterprise and scientific datasets.
A principal focus of Qwen2.5-72B is enhanced instruction following and robustness to system prompt diversity, which supports sophisticated role-play scenarios and advanced chatbot conditioning. The model also demonstrates strong utility as an AI agent, effectively integrating with external tools via programmatic interfaces. Although certain “thinking mode” and “general-purpose mode” distinctions are introduced in successor models (such as Qwen3), Qwen2.5-72B supports highly capable logical reasoning, coding, and mathematical operations through its foundation training and exposure to expert model insights, including Qwen2.5-Coder and Qwen2.5-Math.
Performance and Benchmarking
Qwen2.5-72B achieves high levels of benchmark performance relative to contemporary large language models. On knowledge-intensive benchmarks such as MMLU, it surpasses a score of 85, reflecting improvements in factual accuracy and general knowledge retrieval over its predecessor, Qwen2. For coding tasks, the model exceeds a HumanEval score of 85, evidencing enhanced performance in software engineering and code synthesis domains. Mathematical reasoning is similarly improved, with MATH benchmark scores above 80, demonstrating capacity for quantitative and logical inference.
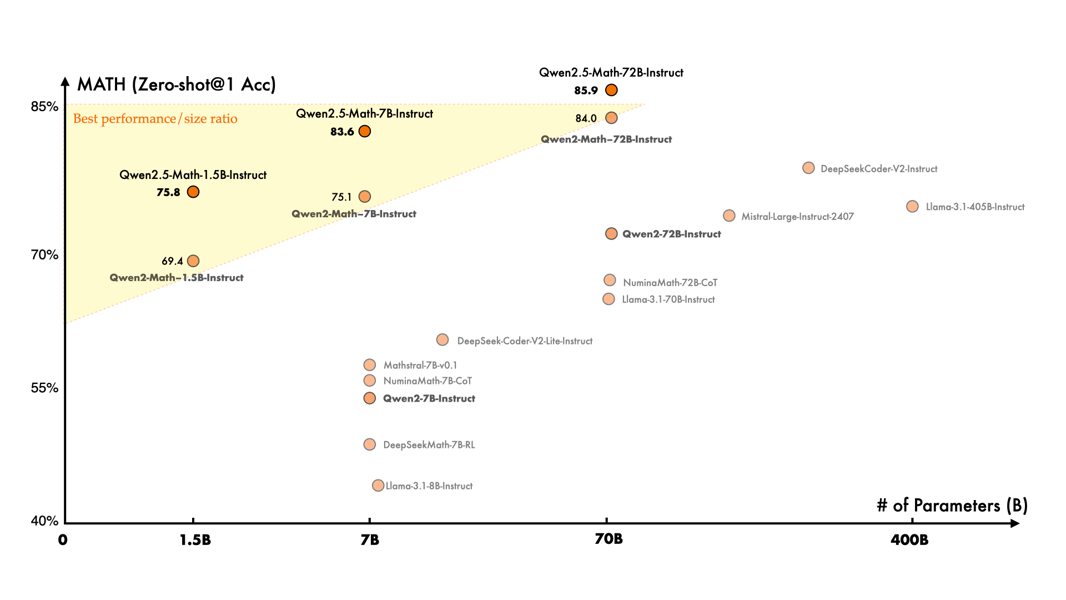
Scatter plot of Qwen2.5-Math model performance against parameter size, highlighting competitive accuracy on the MATH benchmark across all sizes, with Qwen2.5-72B-Instruct achieving top accuracy.
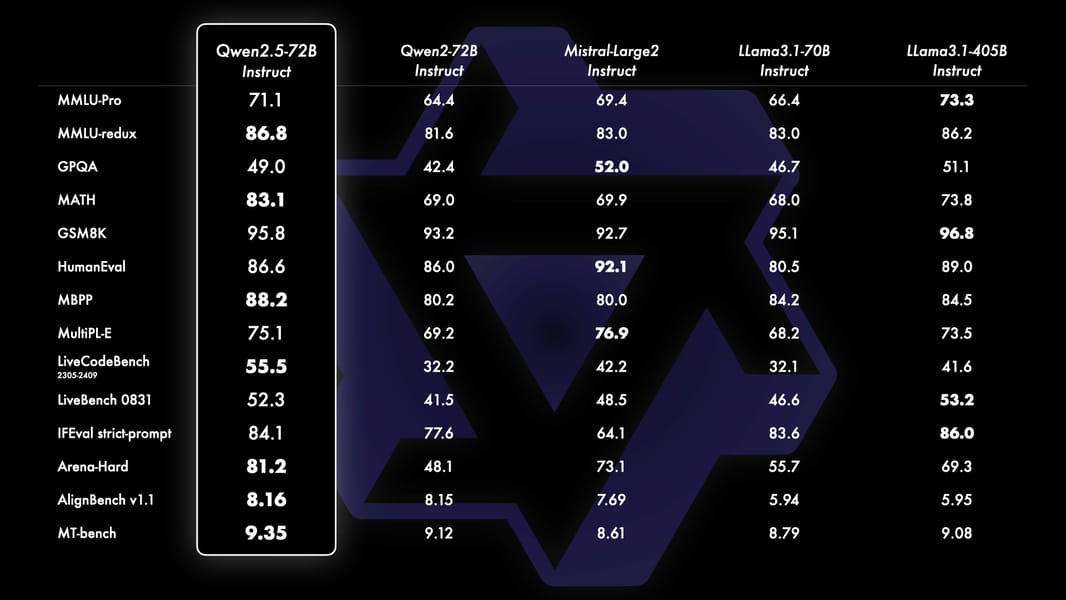
Benchmark table comparing Qwen2.5-72B Instruct with other leading language models, including Mistral-Large V2 and Llama-3.1-70B, across diverse evaluation tasks.
The base version of Qwen2.5-72B also compares closely to models with larger parameter counts, such as Llama-3-405B, in academic and general reasoning benchmarks. In instruction-tuned configurations, Qwen2.5-72B demonstrates competitive results with established open-source models such as Mistral-Large V2 and the Llama-3.1-70B series. These evaluations are publicly documented and cross-referenced in the Qwen2.5 blog release.
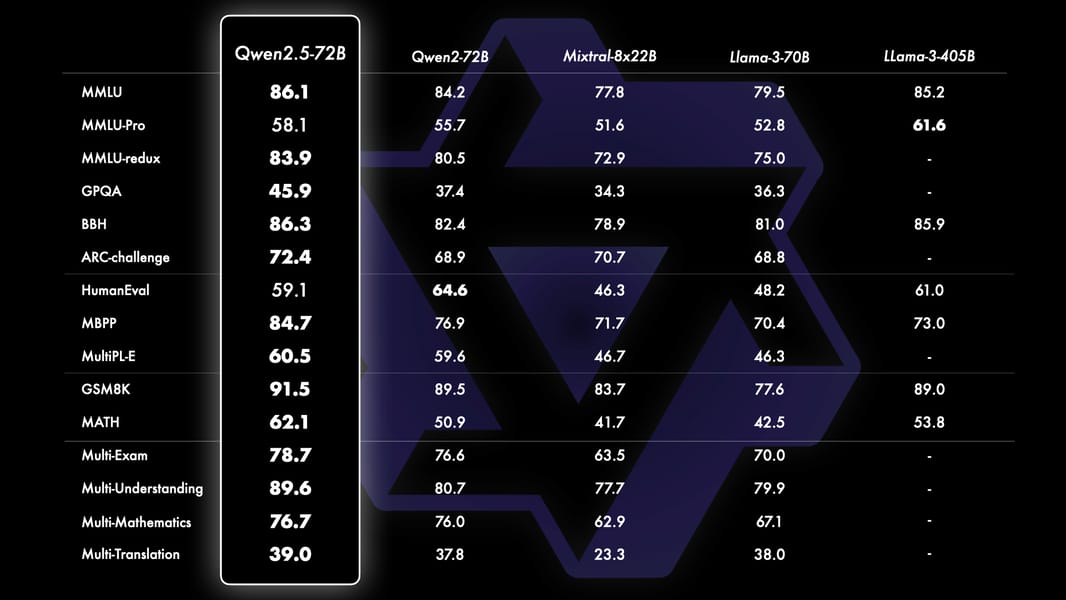
Data table showing Qwen2.5-72B’s base model performance on academic and reasoning benchmarks, directly compared to Qwen2-72B, Mixtral, Llama-3-70B, and Llama-3-405B.
Qwen2.5-72B’s capabilities make it well-suited for a spectrum of applications requiring deep natural language understanding, text generation, tool use, and AI agent behaviors. Its improvements in handling extensive context windows benefit document analysis, legal text processing, scientific literature review, and other large-scale text operations. Enhanced structured data handling supports business intelligence, data annotation, and interactive analytics through direct JSON or table output.
The model’s strong multilingual support extends its applicability to translation, cross-lingual summarization, and global conversational interfaces. Additionally, its specialized expert training enables robust performance in software development (via Qwen2.5-Coder) and academic mathematics (via Qwen2.5-Math), with specialized versions targeting each domain for improved performance.
Qwen2.5-72B is released as a base model, optimized for further post-training rather than direct deployment in conversational scenarios. Typical workflows involve supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), or continued domain-specific pretraining to achieve optimal performance for target applications.
Model Family, Availability, and Evolution
Qwen2.5-72B is the largest member of the Qwen2.5 dense, decoder-only model family, which spans a parameter spectrum from 0.5B through 72B. Specialized derivatives within the series include Qwen2.5-Coder (optimized for programming tasks) and Qwen2.5-Math (optimized for mathematical and reasoning challenges), both available at different parameter scales. The Qwen2.5 series builds on earlier Qwen releases, and has since been superseded by the Qwen3 series, which introduces further architectural enhancements and a new naming scheme. All open-source Qwen models are published under the Apache 2.0 license.
Development milestones include the release of Qwen2.5 models in September 2024, with previous iterations and MoE-based variants tracing back through the Qwen1.5 and Qwen2 timelines.
Limitations
Although Qwen2.5-72B demonstrates substantial performance across benchmark suites, its base version is not recommended for direct conversational or end-user deployment without additional post-training. For optimal usage, post-training strategies such as instruction-tuning should be employed. While API-based models derived from Qwen (such as Qwen-Plus) demonstrate strong comparative results to leading large models, they may underperform relative to select proprietary models on certain benchmarks.