Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 2 72B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 2 72B
Qwen2-72B is a 72.71 billion parameter Transformer-based language model developed by Alibaba Cloud, featuring Group Query Attention and SwiGLU activation functions. The model demonstrates strong performance across diverse benchmarks including MMLU (84.2), HumanEval (64.6), and GSM8K (89.5), with multilingual capabilities spanning 27 languages and extended context handling up to 128,000 tokens for specialized applications.
Explore the Future of AI
Your server, your data, under your control
Header image displaying the stylized Qwen2 logo, representing the Qwen2 series of large language models.
Qwen2-72B is a large-scale language model introduced as part of the Qwen2 series, released on June 7, 2024, as an evolution of the earlier Qwen1.5 models. Developed by the Qwen team, Qwen2-72B is designed as a foundational language model positioned for further post-training, including supervised fine-tuning and reinforcement learning from human feedback. The Qwen2 series encompasses models of varying sizes, with both base and instruction-tuned variants. Qwen2-72B, the largest dense model in the lineup, demonstrates strong performance across a diverse range of benchmarks, multilingual tasks, and extended context scenarios, reflecting ongoing advancements in large language model research and engineering. For further details, refer to the official Qwen2 release announcement.
Architecture and Model Design
Qwen2-72B is built upon the Transformer architecture, incorporating several enhancements such as SwiGLU activation, attention QKV bias, and Group Query Attention (GQA). The use of GQA contributes to improved inference speed and reduced memory consumption. This dense model comprises approximately 72.71 billion parameters, of which 70.21 billion are non-embedding weights. Unlike some smaller Qwen2 variants, Qwen2-72B does not employ embedding tying. An updated tokenizer is integrated to support multiple natural languages and programming code, reflecting efforts to enhance multilingual and code understanding.
The Qwen2 model family includes both base and instruction-tuned models. Qwen2-72B itself is a dense, decoder-only language model, differentiating it from Mixture-of-Experts (MoE) architectures found in related models like Qwen2-57B-A14B. All models in the series utilize GQA, but only the smallest models (Qwen2-0.5B and Qwen2-1.5B) integrate tied embeddings.
Training Data and Methods
Qwen2-72B and its instruction-tuned derivative, Qwen2-72B-Instruct, were trained on large, diverse datasets covering 27 languages beyond English and Chinese. Considerable emphasis was placed on increasing both the quality and volume of multilingual and instructional training data. The training regimen addressed linguistic challenges such as code-switching, leading to significant improvements in multilingual evaluation metrics.
For instruction tuning, models such as Qwen2-72B-Instruct underwent post-training to enhance human alignment and task-following capabilities. Alignment techniques included scalable supervised fine-tuning, reward modeling, and online Direct Preference Optimization (DPO). Automated strategies such as rejection sampling for mathematics, execution feedback for coding, back-translation for creative writing, and scalable oversight for role-play were employed to generate high-quality instructional data. An Online Merging Optimizer was implemented to reduce the so-called "alignment tax" during post-training.
Benchmark Performance
Comparison table showing Qwen2-72B benchmark scores relative to Llama3-70B, Mixtral-8x22B, and Qwen1.5-110B across multiple datasets.
Qwen2-72B exhibits robust performance across a broad array of benchmarks. Evaluations on standard datasets demonstrate competitive or superior results to contemporary models such as Llama-3-70B and Mixtral-8x22B, as well as achieving notable gains over its predecessor, Qwen1.5-110B, despite a smaller parameter count. Key benchmark results include high scores on MMLU (84.2), HumanEval (64.6), GSM8K (89.5), C-Eval (91.0), and Multi-Mathematics (76.0). These figures represent the model's capabilities in tasks ranging from general language understanding and mathematics to code generation.
The instruction-tuned variant, Qwen2-72B-Instruct, demonstrates further improvements in alignment and applied task performance.
Benchmark comparison of Qwen2-72B-Instruct, Llama-3-70B-Instruct, and Qwen1.5-72B-Chat, highlighting Qwen2-72B-Instruct's results across MMLU, HumanEval, and additional datasets.
On popular benchmarks, Qwen2-72B-Instruct attains scores such as 82.3 on MMLU, 86.0 on HumanEval, and 91.1 on GSM8K, closely matching or outperforming other leading models tested at similar scales.
Further analysis of domain-specific capabilities shows Qwen2-72B-Instruct possessing strong coding and mathematical proficiency across programming languages and mathematical benchmarks.
Charts illustrating coding and mathematical performance of Qwen2-72B-Instruct compared to Llama3-70B-Instruct across both language and mathematics subdomains.
In addition to high raw scores, Qwen2-72B-Instruct demonstrates strong multilingual and context-handling capabilities. Human evaluation studies and benchmarking on M-MMLU and MGSM further confirm robust performance in language understanding and mathematical reasoning across multiple languages.
Extended Context and Long-Range Understanding
A distinctive feature of the Qwen2 series, including Qwen2-72B-Instruct, is its capacity to process exceptionally long contexts. Models are trained on contexts up to 32,000 tokens and are evaluated at lengths as high as 128,000 tokens via techniques such as YARN and Dual Chunk Attention.
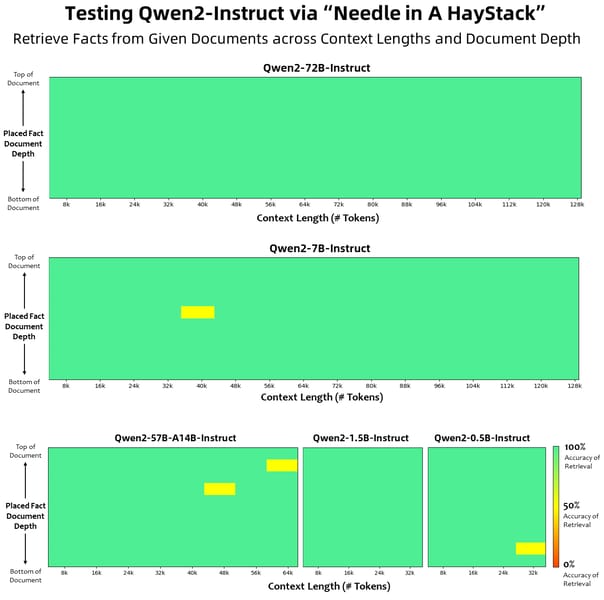
Heatmaps from the Needle in a Haystack task, showing Qwen2-72B-Instruct achieving 100% accuracy in retrieving facts across up to 128,000 token contexts.
Heatmap-based evaluation from the Needle in a Haystack benchmark demonstrates that Qwen2-72B-Instruct maintains perfect retrieval accuracy for factual information even at 128,000 tokens, indicating robust long-range memory and information extraction. This positions the model for use cases demanding precise recall across extensive documents.
Applications, Limitations, and Model Family
Qwen2-72B serves primarily as a base model for specialized post-training, including instructional fine-tuning and reinforcement learning workflows. The instruction-tuned Qwen2-72B-Instruct displays aptitude for tasks in reasoning, code generation, mathematics, multilingual understanding, and information extraction from long texts. As a general-purpose model, it can be applied to language generation, code synthesis, educational tasks, and research scenarios where large-context comprehension and multilingual support are required.
Within the Qwen2 family, models range in scale from 0.5B to 72B parameters, encompassing both dense and MoE architectures. Context length capabilities vary from 32K to 128K tokens for instruction-tuned versions, depending on model size.
The primary limitation of Qwen2-72B is that its base form is intended for further post-training and not optimized for direct deployment in text generation applications without additional alignment. Licensing for Qwen2-72B is governed by the Qianwen License, while other family members typically utilize the Apache 2.0 open-source license.