Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 2.5 Coder 32B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 2.5 Coder 32B
Qwen2.5-Coder-32B is a 32.5-billion parameter transformer-based language model developed by Alibaba Cloud, specifically designed for programming and code intelligence tasks. The model supports over 92 programming languages and features capabilities in code generation, completion, repair, and reasoning with a 128,000-token context window. Trained on approximately 5.5 trillion tokens of code and instructional data, it demonstrates performance across various coding benchmarks including HumanEval, MBPP, and multilingual programming evaluations.
Explore the Future of AI
Your server, your data, under your control
Qwen2.5-Coder-32B is a large language model specialized for programming and code intelligence tasks, developed by the Qwen Team at Alibaba Group as part of the Qwen model family. Based on the Qwen2.5 architecture, it provides support for programming across a wide array of languages and tasks. With its substantial parameter count and refined training methodology, Qwen2.5-Coder-32B is an open code generation model (Qwen2.5-Coder blog post; Qwen2.5-Coder technical report).
The Qwen3 logo prominently represents the latest series of large language models from Alibaba Group, including the Qwen2.5-Coder model family.
Qwen2.5-Coder-32B contains approximately 32.5 billion parameters (31.0B non-embedding), organized in a transformer-based architecture enhanced with rotary position embeddings (RoPE), SwiGLU activations, Root Mean Square Layer Normalization (RMSNorm), and Attention QKV bias (Qwen2.5-Coder-32B Hugging Face model card). The model comprises 64 transformer layers, with 40 attention heads for the query (Q) and 8 for the value (KV), following the Grouped Query Attention (GQA) paradigm. An architectural feature is its ability to manage long context windows, accepting up to 128,000 tokens through the incorporation of the Yet another RoPE N-gram (YaRN) method (YaRN arXiv preprint).
Qwen2.5-Coder models are instruction-tuned or available as base models, depending on the intended application. They support over 92 programming languages, and support capabilities in code generation, completion, repair, and reasoning (Qwen2.5-Coder technical report; Qwen2 technical report). The architecture is designed to handle multi-language and repository-level completions, as well as fill-in-the-middle tasks facilitated by dedicated token schemes (Efficient Training of Language Models to Fill in the Middle).
Training Data and Methodology
Qwen2.5-Coder-32B was trained on an extensive dataset comprising approximately 5.5 trillion tokens that include a blend of source code, instructional text-code samples, and synthetic data. This dataset was curated to cover programming languages and task diversity, aiming to support the model’s application in software development scenarios (Qwen2.5-Coder blog post). Training strategies, such as instruction tuning and alignment, support capabilities in creative task following, role-playing, and multi-turn dialogue, which are relevant for code assistant applications (Qwen2.5-Coder technical report).
Benchmark Performance
Qwen2.5-Coder-32B and its smaller siblings have been evaluated on a wide range of code-centric and general reasoning benchmarks. Results indicate that the instruction-tuned variants, in particular, perform on various benchmarks when compared to contemporary open-source models.
The radial bar chart illustrates Qwen2.5-Coder's performance on coding benchmarks, including HumanEval, EvalPlus, and MBPP, in comparison to other open code models.
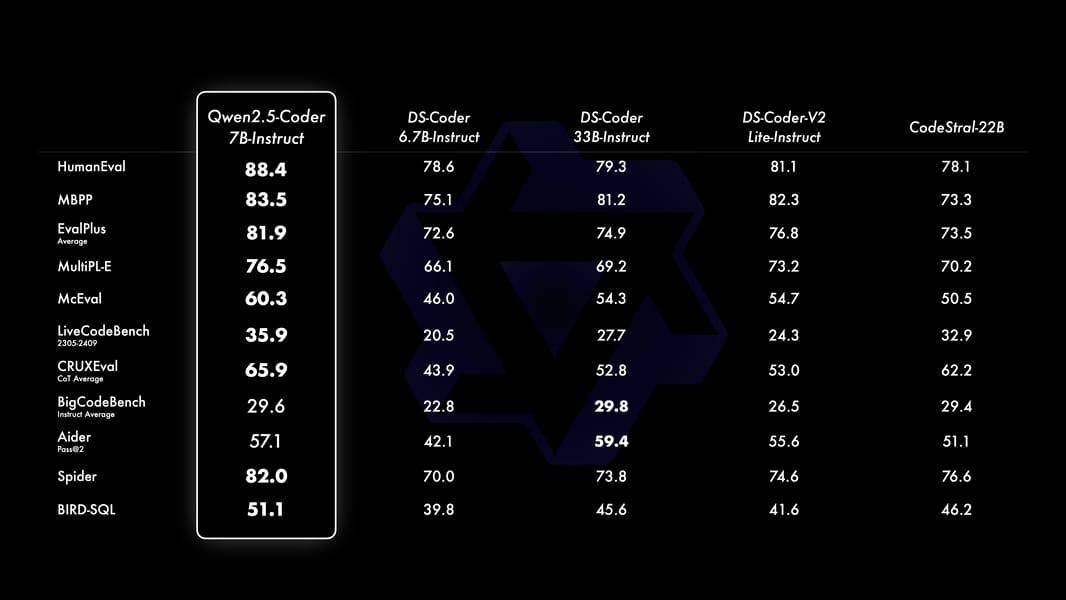
Comparisons on evaluation tasks like HumanEval, MBPP, MultiPL-E, CRUXEval, and BigCodeBench show results in code synthesis, fill-in-the-middle, and code reasoning tasks for Qwen2.5-Coder models (Qwen2.5-Coder blog post).
CRUXEval-O (CoT) analysis indicates Qwen2.5-Coder-Instruct models' code reasoning performance relative to their model size, when compared to other open models.
Qwen2.5-Coder-Instruct performs on benchmarks for code generation and repair, mathematical reasoning (on datasets such as GSM8K and Math), and general abilities (MMLU, ARC). This performance suggests transfer of reasoning skills from its pretraining corpus (Qwen2.5-Coder technical report).
Benchmark table showing Qwen2.5-Coder-Instruct's results after instruction tuning in comparison with DS-Coder and [Codestral-22B](https://openlaboratory.ai/models/codestral-22b-v0_1), using evaluation tasks such as MBPP, EvalPlus, and CRUXEval.
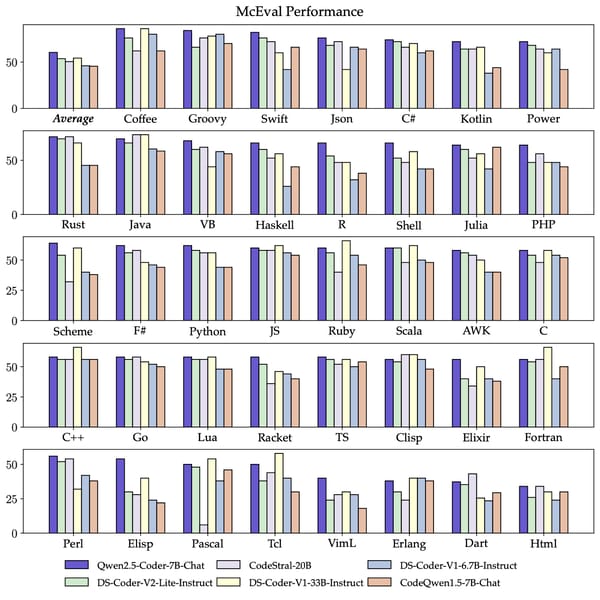
Qwen2.5-Coder-Instruct also performs on the McEval multilingual benchmark, which encompasses nearly 50 programming languages. The model's instruction-following capability extends to both code and natural language across over 100 human languages and dialects (Qwen2.5-Coder technical report).
The bar chart illustrates Qwen2.5-Coder-Instruct's performance on the McEval multilingual coding benchmark, indicating its language support.
Qwen2.5-Coder-32B is available as both a base and instruction-tuned model (Qwen/Qwen2.5-Coder-32B on Hugging Face). The base variant is primarily used for foundational code completion and fill-in-the-middle tasks, whereas the instruction-tuned version enables chat-based interactions and more complex multi-turn dialogue, and supports applications as a coding assistant.
Typical use cases include single- and multi-file code completion, automatic code repair, repository-level code understanding, and program synthesis. Fill-in-the-middle capabilities allow insertion of code in specified gaps within larger contexts, which is facilitated by specialized prompt templates and tokens (Qwen2.5-Coder blog post). The long-context support, powered by the YaRN method, supports applications involving large repositories or documentation-heavy projects (YaRN arXiv preprint).
Performance comparison of Qwen2.5-Coder-7B-Base versus other open models across a range of evaluation tasks.
For long input sequences exceeding 32,768 tokens, users are advised to set a rope_scaling configuration in the deployment to leverage dynamic context extension. It is also recommended that base models are not used for conversational chat directly; instead, instruction-tuned variants should be employed where dialogue or chat interactions are required.
Qwen2.5-Coder-32B is distributed under the Apache 2.0 license, facilitating research, modification, and redistribution (Qwen2.5-Coder GitHub repository).
Position within the Qwen Model Family
Qwen2.5-Coder is a constituent of the broader Qwen model suite at Alibaba Group, which includes both dense and Mixture-of-Experts (MoE) architectures suitable for language and multimodal tasks. Within the Coder series, multiple size variants are available, from 0.5B to 32B parameters, allowing for selection based on performance and resource considerations (Qwen Team blog; Qwen Official Documentation). Qwen2.5-Coder focuses on coding skills across languages, instruction-following capabilities, and long-context processing, when compared to its predecessors and peer models.