Launch a dedicated cloud GPU server running Laboratory OS to download and run Playground v2.5 Aesthetic using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Automatic1111's legendary web UI for Stable Diffusion, the most comprehensive and full-featured AI image generation application in existence.
Model Report
playgroundai / Playground v2.5 Aesthetic
Playground v2.5 Aesthetic is a diffusion-based text-to-image model that generates images at 1024x1024 resolution across multiple aspect ratios. Developed by Playground and released in February 2024, it employs the EDM training framework and human preference alignment techniques to improve color vibrancy, contrast, and human feature rendering compared to its predecessor and other open-source models like Stable Diffusion XL.
Explore the Future of AI
Your server, your data, under your control
Playground v2.5 Aesthetic is an open-source, diffusion-based text-to-image generative model developed by Playground. Released in February 2024, it builds upon the foundation of its predecessor, Playground v2, to deliver highly aesthetic and photorealistic images at resolutions up to 1024x1024 pixels, supporting both portrait and landscape aspect ratios. The model’s training and architecture leverage advancements in diffusion modeling and human preference alignment to enhance color fidelity, aspect ratio versatility, and visual realism, particularly in the depiction of humans. Extensive user studies and benchmark evaluations have established Playground v2.5 as a leading model in open-source image generation, with broad applicability across artistic, design, and media domains.
A collage of AI-generated images by Playground v2.5, illustrating its versatility across a range of subjects and styles.
Playground v2.5 is based on the latent diffusion model architecture, with technical similarities to Stable Diffusion XL (SDXL). The model employs two fixed, pre-trained text encoders—OpenCLIP-ViT/G and CLIP-ViT/L—for robust text-to-image alignment. A distinguishing aspect of Playground v2.5's development was its integration of the EDM (Elucidating the Design Space of Diffusion-Based Generative Models) training framework, which introduces a near-zero signal-to-noise ratio at the final denoising step, as well as principled noise scheduling and improved loss conditioning. This methodology directly addresses prior limitations in color vibrancy, contrast, and image consistency observed in previous diffusion models.
The model’s data pipeline was redesigned to improve multi-aspect ratio generation, employing a balanced bucket sampling strategy to prevent overrepresentation of square images—a common issue in latent diffusion models. Additionally, Playground v2.5 features a novel preference alignment procedure, drawing inspiration from methodologies such as those presented in the Emu model, which enables more accurate and lifelike rendering of human features through supervised fine-tuning with high-quality, human-curated datasets.
Visual Quality, Color, and Contrast
A significant motivation behind Playground v2.5’s development was to overcome the limitations in color reproduction and regional contrast that often affect open-source diffusion models. Training from scratch with the EDM framework enabled the model to produce images with vivid saturation, dynamic range, and pure-colored backgrounds, which sets it apart from models such as Stable Diffusion XL and other contemporaries.
The contrast and color depth improvements are evidenced in direct comparisons with both Playground v2 and Stable Diffusion XL. Side-by-side analyses reveal that v2.5 produces richer, more vibrant images with enhanced detail and realistic lighting.
Multi-Aspect Ratio Generation and Human-Centric Image Quality
Playground v2.5 significantly advances the generation of images across a variety of aspect ratios, such as 9:16, 16:9, and beyond, whereas many prior diffusion models exhibit a performance bias toward square formats. This improvement was enabled through a meticulous restructuring of the training data and conditioning pipeline, reducing catastrophic forgetting and ensuring even representation of all aspect ratios.
Preference study results for image quality across various aspect ratios: Playground v2.5 exhibits markedly higher user preference than SDXL.
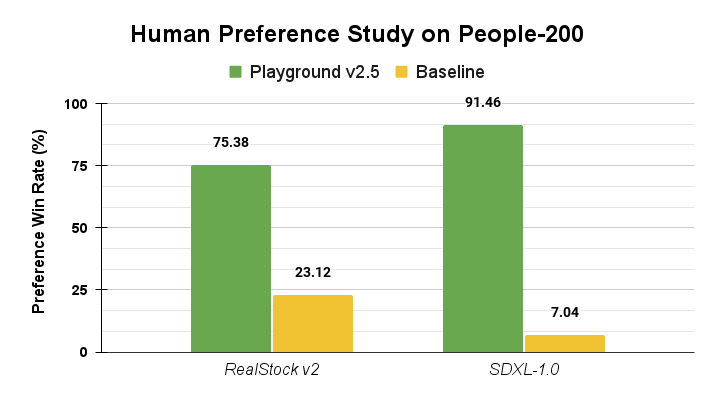
Particular attention was given to improving human-centric image synthesis. The model utilizes an advanced alignment approach, balancing both supervised fine-tuning and human-in-the-loop curation. This produces more anatomically plausible faces, hands, and other challenging features, and improves lighting, color balance, and perceptual depth in scenes with people.
Human preference alignment comparison: Playground v2.5 achieves superior performance on people-centric images over RealStock v2 and SDXL.
Benchmarking, Evaluation, and Comparative Performance
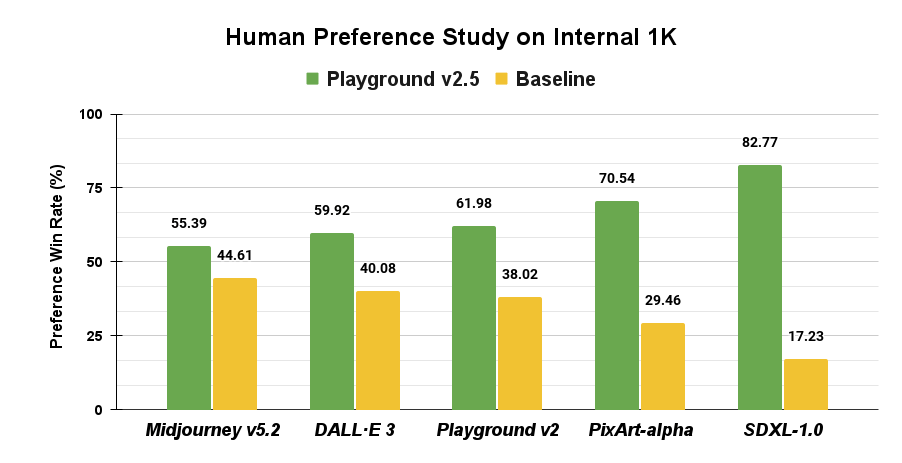
The efficacy of Playground v2.5 has been rigorously evaluated through extensive user preference studies and quantitative benchmarks. In blinded user studies, the model achieved higher preference win rates over both open- and closed-source models—including DALL-E 3, Midjourney v5.2, Stable Diffusion XL, PixArt-α, and Playground v2.
Aggregate results from human preference studies: Playground v2.5 outperforms several leading baseline models on overall image quality.
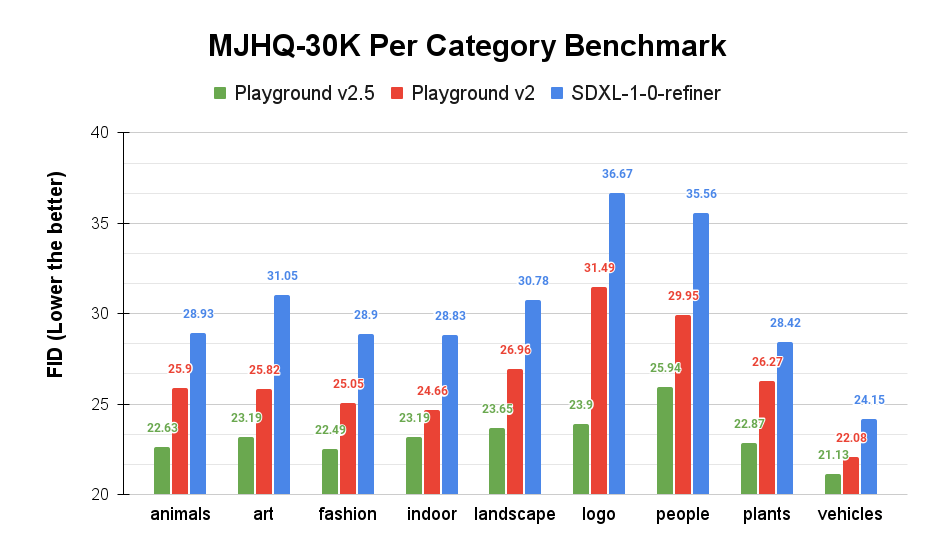
Evaluation on the MJHQ-30K benchmark dataset—containing 3,000 Midjourney-vetted images spanning multiple categories—demonstrates Playground v2.5’s advances in Fréchet Inception Distance (FID) scores, achieving lower (better) marks than Playground v2 and Stable Diffusion XL across diverse domains including people, fashion, and landscape.
Per-category FID scores from the MJHQ-30K benchmark: Playground v2.5 demonstrates lower FID across all major categories.
While the model demonstrates strong performance in aesthetic quality and human-centric generation, acknowledged limitations remain. Future directions include improving text-image alignment, enhancing variation and diversity in outputs, and exploring new architectural foundations beyond the current Stable Diffusion XL-derived framework. Additional work is also anticipated in areas of precise, reference-based image editing and controllability.
Applications and Use Cases
Playground v2.5 is designed for high-quality image synthesis from text prompts, suitable for creative arts, illustration, conceptual design, and prototyping use cases. Its ability to reliably generate high-resolution images in diverse aspect ratios, with faithful text-image correspondence and elevated realism, extends its utility to numerous domains demanding versatility and visual precision.
Model Progression and Comparisons
Playground v2.5 is a direct successor to Playground v2, introducing notable improvements in vividness, human preference alignment, and support for a greater range of aspect ratios. Playground v2, released previously, was widely adopted in the open-source community and served as a reference point for other models such as Stable Cascade.