Note: Command A weights are released under a CC-BY-NC 4.0 License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Command A using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Cohere / Command A
Command A is a decoder-only transformer language model developed by Cohere for enterprise applications, featuring a 256,000-token context window and optimized for multilingual understanding, retrieval-augmented generation, code synthesis, and agentic workflows. The model employs grouped-query attention and architectural innovations for enhanced throughput, achieving competitive performance across academic benchmarks while demonstrating efficiency advantages in inference speed and memory usage compared to similar models.
Explore the Future of AI
Your server, your data, under your control
Command A is a generative language model developed by Cohere and Cohere Labs, specifically engineered for enterprise tasks demanding high performance, security, and computational efficiency. Released for research on March 13, 2025, Command A advances core capabilities in multilingual understanding, retrieval-augmented generation (RAG), code synthesis, and agentic tool use. The model is available under a CC-BY-NC license and is designed for non-commercial research and development applications.
Promotional graphic for Command A, highlighting the product identity and brand logo.
Command A employs a decoder-only transformer architecture, optimized for throughput and long-context reasoning. The model features a context window of 256,000 tokens, enabling it to process extensive enterprise documents and perform complex sequence tasks. This architecture leverages multiple innovations, including interleaved attention mechanisms combining sliding window attention with Rotary Positional Embeddings (RoPE) and full attention layers sans positional encoding for efficient context handling.
Key architectural attributes include grouped-query attention for increased throughput, shared input and output embeddings to conserve memory, and the omission of bias terms to stabilize training at scale. Command A utilizes SwiGLU activations and is trained via Cohere's JAX-based distributed training infrastructure. A distinguishing feature of its training regime is progressive context extension and precision optimization through JAX's GSPMD tools, combining data, fully sharded, and sequence parallelism, as detailed in the technical report.
Training Data and Methodology
Model development follows a multi-stage pipeline, including large-scale pre-training, supervised fine-tuning (SFT), reinforcement learning (RL), and a unique model-merging process. Pre-training leverages a diverse corpus of multilingual text and code, synthetic data, and high-quality domain-specific vendor datasets. Data quality is ensured through deduplication and heuristic filtering, focusing on educational and informative content.
Fine-tuning involves the creation of multiple expert models (targeting domains such as code, safety, RAG, mathematics, multilinguality, and long-context operation), which are then merged using linear parameter-merging. Reinforcement learning is applied with reward models trained via human annotation and synthetic evaluations, utilizing approaches like direct preference optimization (SLiC, DPO, IPO), self-revising RL, and KL-regularized objectives (CoPG). The final "polishing" stage iteratively refines tone and task alignment with human feedback, blending offline and online RLHF strategies.
Datasets are segmented to address specialized capabilities:
Multilingual components span 23 languages, utilizing both annotated and synthetic prompts alongside machine-translated public datasets, with iterative best-of-N selection for data curation.
Code data emphasizes eight programming languages and multiple SQL dialects, with augmentation via execution feedback.
Agentic tool-use blends human and synthetic traces across API, document, and code environments.
Mathematical and logical tasks are synthesized with correctness checks performed by LLM-based judges.
Safety datasets are expanded with persona-driven prompts and iterative refusal policy alignment.
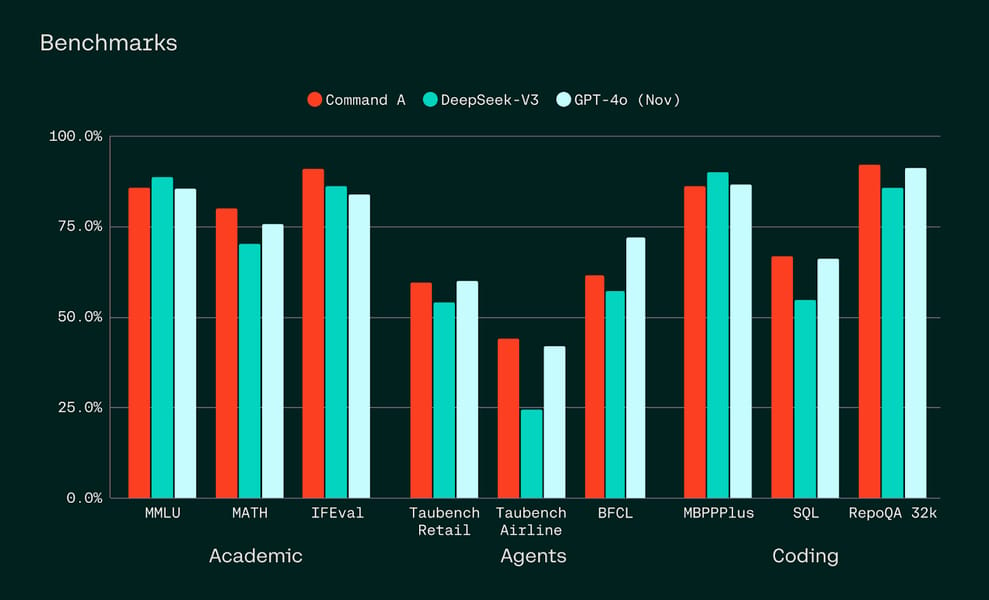
Command A demonstrates competitive or leading results across a broad range of academic benchmarks, real-world enterprise evaluations, coding tasks, and multilingual assessments. The model achieves high throughput and inference efficiency.
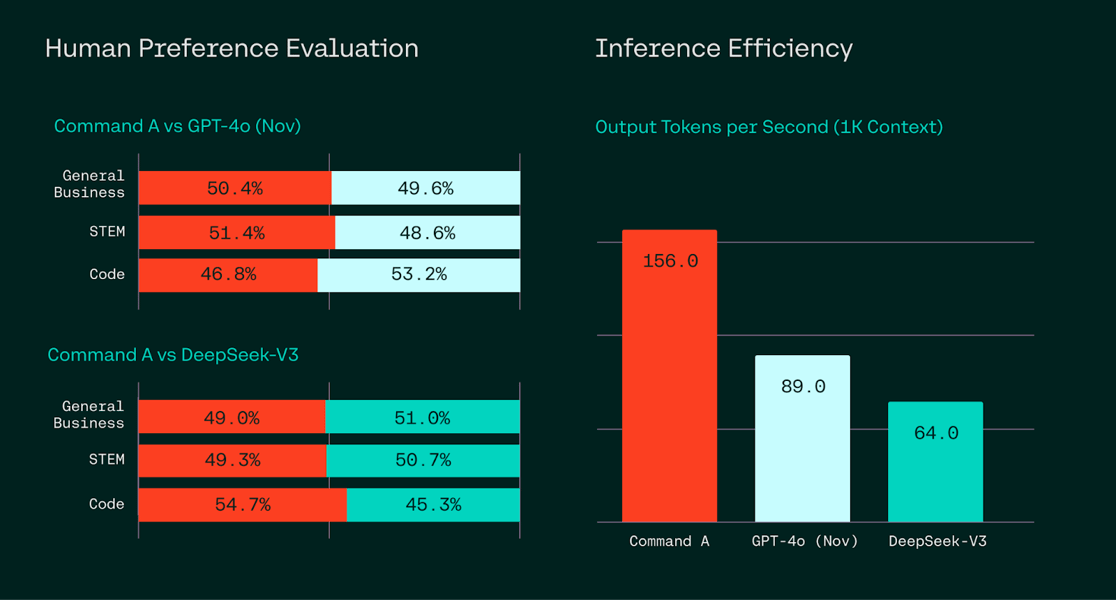
Human evaluation head-to-head win rates and inference efficiency: Command A vs. GPT-4o and DeepSeek-V3 for business, STEM, and code tasks.
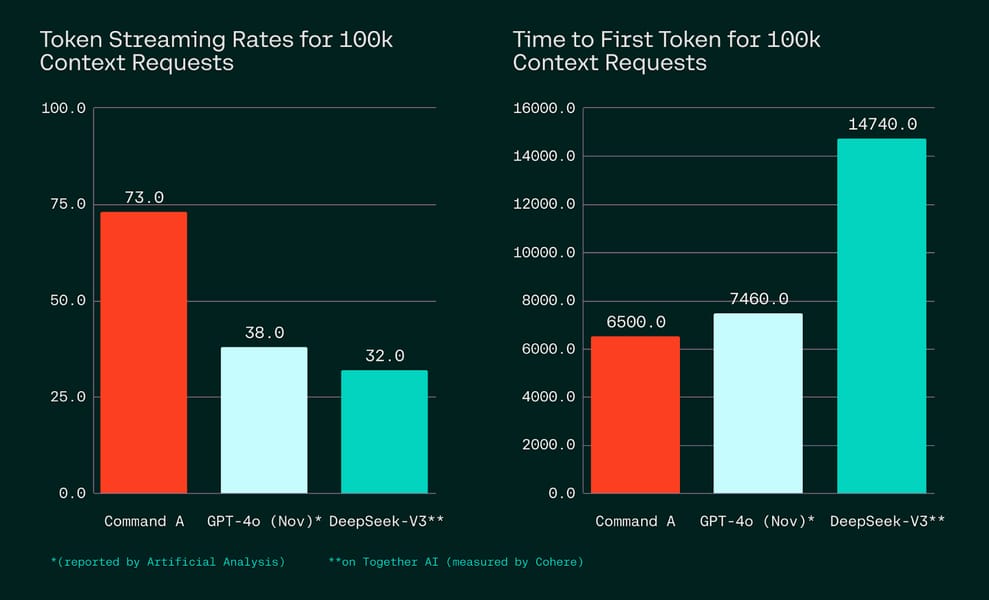
The model delivers up to 156 tokens/sec throughput—substantially higher than comparable models such as GPT-4o and DeepSeek-V3. It also reduces KV cache memory requirements, with notable savings for long-context tasks. Performance metrics from recent benchmarks include:
Multilingual: NTREX translation average (68.8 COMET-20), mArenaHard preference rates favoring Command A in most languages, and top scores in Arabic dialect identification
Quantitative overview of academic, agentic, and coding benchmarks for Command A, DeepSeek-V3, and GPT-4o.
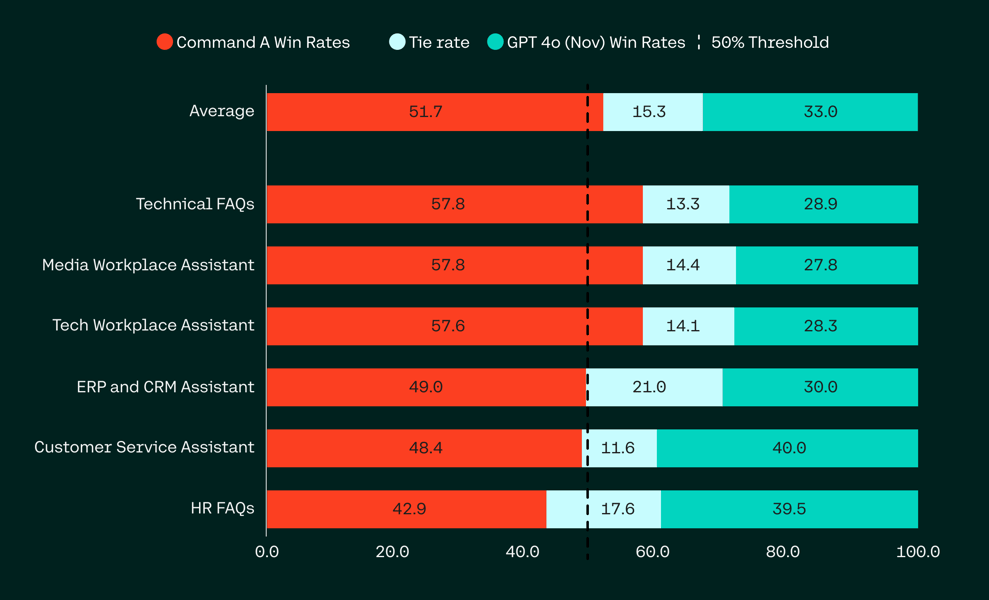
Enterprise-grade RAG use-cases highlight Command A's retrieval precision, with human evaluation win rates favoring the model in technical FAQ, workplace assistant, and customer service scenarios.
Human evaluation of RAG (Retrieval-Augmented Generation) use-cases, comparing Command A with GPT-4o across enterprise applications.
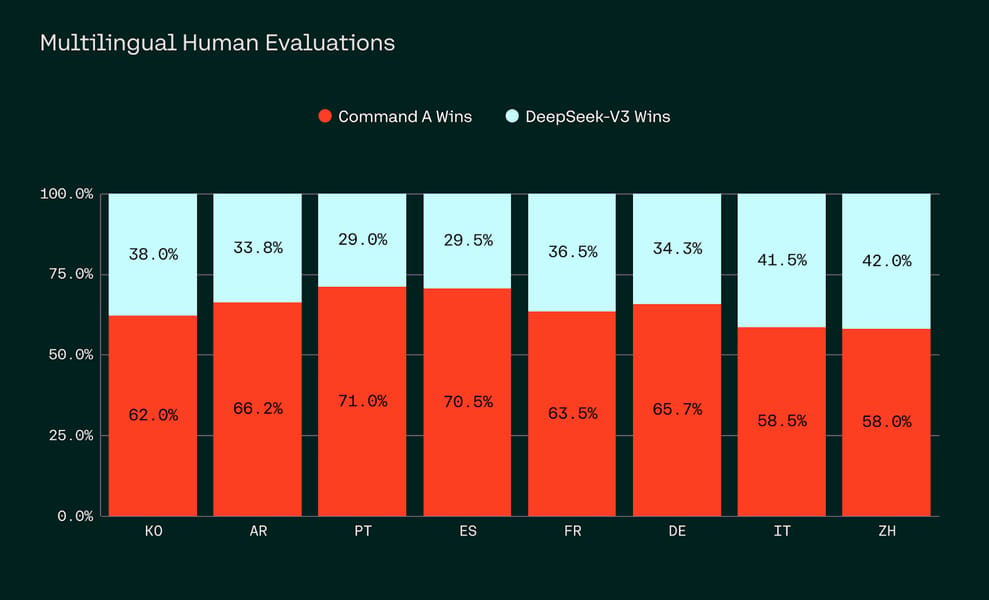
Multilingual performance is further supported by comparative human evaluations and LLM-as-judge metrics, demonstrating strong preference rates across Korean, Arabic, Portuguese, Spanish, French, German, Italian, and Chinese.
Win rates across eight languages in head-to-head human evaluation: Command A vs. DeepSeek-V3.
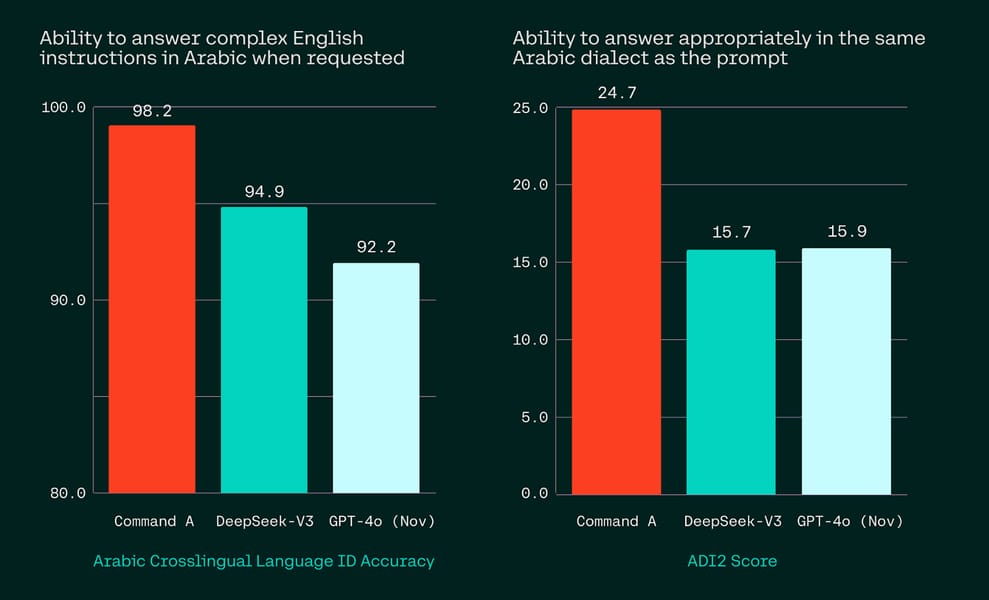
The model excels in dialectal adherence and cross-lingual response, especially in Arabic, as evidenced by precision on dialect identification and instruction-following benchmarks.
Comparative performance for complex English-to-Arabic instruction and dialect matching, illustrating Command A's strengths in multilingual tasks.
Command A is tailored for a wide range of enterprise applications:
Agentic workflows: Well-suited for scenarios requiring integration with APIs and databases, supporting complex tool-use and planning for REACT-style agents.
Multilingual operations: Enables cross-lingual communication, translation, and regional compliance across 23 supported languages.
Retrieval-Augmented Generation (RAG): Ideal for tasks requiring the model to cite or ground outputs in external documents, such as policy analysis, legal compliance, and technical assistance.
Conversational systems and chatbots: Configured by default for dialogue with context-aware introductions, follow-ups, and support for Markdown/LaTeX formatting.
Information extraction and summarization: Effective in document classification, summarization, and knowledge distillation from lengthy or technical materials.
Code generation and review: Supports SQL synthesis, code translation, and bug resolution with strong performance at low temperatures.
Mathematical and logical problem solving: Suitable for domains requiring advanced reasoning and precise computational output.
Safety, Limitations, and Model License
Command A incorporates sophisticated safety systems, offering both contextual and strict safety modes to control refusal behavior and mitigate unintended outputs. Custom reward modeling and iterative policy alignment ensure robust handling of sensitive topics while emphasizing a balance between helpfulness and compliance.
Limitations include a default configuration set to 128k context on certain libraries (with potential extension to 256k), occasional preservation loss for code performance during model merging, and inherent saturation/bias in academic benchmarks that may not fully represent enterprise relevance. The model-merging process, while computationally efficient, necessitates subsequent alignment and "polishing" phases to ensure consistency.
Command A is a member of Cohere Labs' Command series of large language models. A notable related model is Command R7B, which shares architectural elements but operates with fewer parameters, providing strong performance in proportion to model size. Command A supersedes Command R+ (including Command R+ Refresh), offering increased inference efficiency and broader capability coverage.
Significant milestones include its initial research release on March 13, 2025, the publication of its technical report on April 7, 2025, and continuing dataset and capability updates through the Hugging Face model repository.