Launch a dedicated cloud GPU server running Laboratory OS to download and run Phi-4 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Microsoft / Phi-4
Phi-4 is a 14-billion parameter decoder-only Transformer language model developed by Microsoft Research that focuses on mathematical reasoning and code generation through curated synthetic data training. The model supports a 16,000-token context window and achieves competitive performance on benchmarks like MMLU (84.8) and HumanEval (82.6) despite its relatively compact size, utilizing supervised fine-tuning and direct preference optimization for alignment.
Explore the Future of AI
Your server, your data, under your control
Phi-4 is a compact generative language model developed by Microsoft Research, designed to support complex reasoning capabilities within a smaller parameter footprint. As an evolution in the Phi model series, Phi-4 focuses on highly curated and synthetic training data to support performance in domains such as mathematics, scientific reasoning, and code generation. It was released in December 2024 and is intended to support both academic exploration and applied research in scalable language technology.
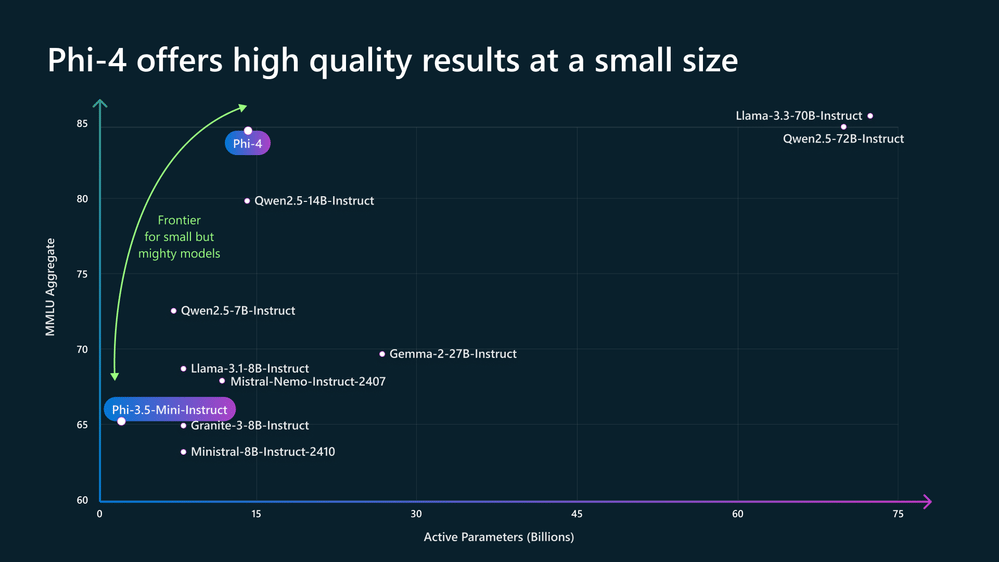
Phi-4 achieves high quality results relative to its small parameter size compared to other large language models (see MMLU scores and model sizes).
Phi-4 builds upon a dense, decoder-only Transformer architecture with 14 billion parameters, employing a tiktoken tokenizer for multilingual token handling and a padded vocabulary of 100,352 tokens. The model supports up to a 16,000-token context window, which was extended from an initial 4,000 during midtraining to facilitate longer and more complex reasoning chains.
A notable aspect of Phi-4's development is the integration of synthetic data, leveraging multi-agent prompting, self-revision cycles, and instruction reversal. These synthetic datasets supplement filtered organic content to increase the density and diversity of reasoning tasks during training. The pretraining corpus encompasses approximately 9.8 trillion tokens, drawing on both broad synthetic formulations and select high-quality web and code data.
For post-training, Phi-4 utilizes supervised fine-tuning (SFT) and direct preference optimization (DPO). SFT applies targeted instruction data for mathematics, coding, safety, multilingual prompts, and conversational tasks. DPO is performed in two rounds: the first employs pivotal token search for fine-grained optimization, and the second uses external judges based on models such as GPT-4o to label and guide preference learning.
Datasets, Synthetic Methods, and Alignment
Phi-4's data pipeline involves problem selection and augmentation from curated datasets. Synthetic datasets are generated through curated seed selection, iterative rewriting, and validation loops. For example, code synthesis tasks undergo execution-based validation, while Q&A data is filtered or expanded using majority-voting systems. Multilingual content is included through language-identified and classifier-filtered material from CommonCrawl and Wikipedia, but English remains the model's primary domain.
Alignment and safety protocols are supported through a combination of open-source and custom synthetic datasets. Techniques such as direct preference optimization and pivotal token search address both output safety and factual reliability. The training span was 21 days, using publicly available data up to June 2024 as described in the Phi-4 technical report.
Performance and Benchmark Evaluation
Phi-4 demonstrates results across a variety of specialized and broad benchmarks, performing well in mathematical reasoning and code generation tasks. On the MMLU benchmark, Phi-4 achieves an aggregate score of 84.8, a score also achieved by some models with significantly larger parameter counts. In the HumanEval code generation evaluation, Phi-4 attains 82.6, achieving a higher score than other open-weight models within its size class.
On graduate-level STEM QA benchmarks such as GPQA and problem-solving contests including the AMC 10/12, Phi-4 achieves higher scores than its predecessor models (Phi-2 and Phi-3), and also achieves higher scores than some larger generative models, including Gemini Pro 1.5 and GPT-4o. Extensive long-context evaluations show consistent recall and reasoning up to the model's full 16K token capacity, reflecting sequence processing and attention scaling.
Example of Phi-4's output on a mathematical reasoning task: the model solves for the diagonal of a rectangle using the Pythagorean theorem.
Phi-4 is designed for scenarios that involve efficient reasoning and consistent logical processes within constrained computational environments. It is relevant in applications requiring mathematical problem solving, general scientific inquiry, programming assistance, and other tasks where explainable step-by-step logic is critical. The model is often employed using chat-based prompt formats, as exemplified in documentation, supporting multi-turn and single-turn queries.
While Phi-4 supports basic multilingual capabilities, English-centric tasks receive the most reliable performance due to training focus and data. Its inference design is tuned for both latency-sensitive and memory-constrained contexts, enabling integration in high-performance or embedded research systems.
Limitations and Responsible Deployment
Similar to other generative models, Phi-4 inherits certain challenges, even with its data curation and synthetic alignment. Its performance on non-English prompts is reduced, given a primarily English training curriculum. The model can perpetuate biases and stereotypes present in source data and may occasionally produce inappropriate or inaccurate content, referred to as hallucinations, especially in domains with limited training coverage. In code-related outputs, reliability is generally higher for Python and commonly used packages, and users are advised to manually verify code in less represented languages or libraries.
Phi-4 tends towards verbose, chain-of-thought explanations even for simpler queries—a consequence of its synthetic reasoning-intensive curriculum. It is effective on single-turn problems but may demonstrate less consistency in sustained dialog management or strict instruction-following scenarios.
Responsible model deployment is encouraged in line with best practices for AI safety, including appropriate filtering, grounding responses with retrieval augmentation, and thorough vetting before use in high-stakes applications.
Model Family and Evolution
Phi-4 continues the developmental philosophy established by previous Phi models, such as Phi-2 and Phi-3, which prioritize data quality and curriculum structure over raw parameter scaling. The synthetic data methodologies and fine-tuning innovations present in Phi-4 represent incremental extensions, emphasizing structured reasoning and factual alignment. Comparative analysis indicates observable improvements over both its predecessors and teacher models, particularly in mathematics and STEM-focused Q&A benchmarks.