Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Diffusion 3.5 Large using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Model Report
stabilityai / Stable Diffusion 3.5 Large
Stable Diffusion 3.5 Large is an 8.1-billion-parameter text-to-image model utilizing Multimodal Diffusion Transformer architecture with Query-Key Normalization for enhanced training stability. The model generates images up to 1-megapixel resolution across diverse styles including photorealism, illustration, and digital art. It employs three text encoders supporting up to 256 tokens and demonstrates strong prompt adherence capabilities.
Explore the Future of AI
Your server, your data, under your control
Stable Diffusion 3.5 Large is an advanced text-to-image generative model developed by Stability AI, released in October 2024 as part of the broader Stable Diffusion 3.5 family. Leveraging the Multimodal Diffusion Transformer (MMDiT) architecture, the model converts natural language prompts into detailed, high-resolution images across a variety of styles and subjects. This model incorporates architectural and training innovations to improve prompt adherence, output diversity, and typographic fidelity, supporting both professional and research-oriented applications, as detailed in the Stability AI announcement.
A collage of diverse AI-generated images, illustrating Stable Diffusion 3.5 Large's ability to produce a variety of subjects and artistic styles based on different text prompts.
Stable Diffusion 3.5 Large builds upon the Multimodal Diffusion Transformer (MMDiT) framework, employing diffusion-based generative mechanisms in conjunction with transformer networks, as described in the MMDiT research paper. A key innovation is the integration of Query-Key Normalization (QK-Normalization) within transformer blocks, a feature that enhances training stability and simplifies the fine-tuning process, according to the Stability AI announcement. This architectural refinement allows for greater variety in outputs from identical prompts with different random seeds, promoting a broader expressive range and stylistic diversity.
The model uses three fixed, pretrained text encoders: OpenCLIP-ViT/G, CLIP-ViT/L, and T5-xxl. These encoders facilitate a maximum context length of up to 256 tokens, depending on the training phase, as noted in the Hugging Face model card. Their inclusion supports complex prompt interpretation and improved text-to-image alignment.
Stable Diffusion 3.5 Large demonstrates versatile style generation, shown here in etched illustration, photorealistic, and anime digital painting outputs.
Stable Diffusion 3.5 Large was trained on a wide spectrum of datasets, encompassing both large-scale synthetic and rigorously filtered publicly available data. The resulting model contains 8.1 billion parameters and is optimized for image synthesis at resolutions up to 1 megapixel, as reported by Stability AI.
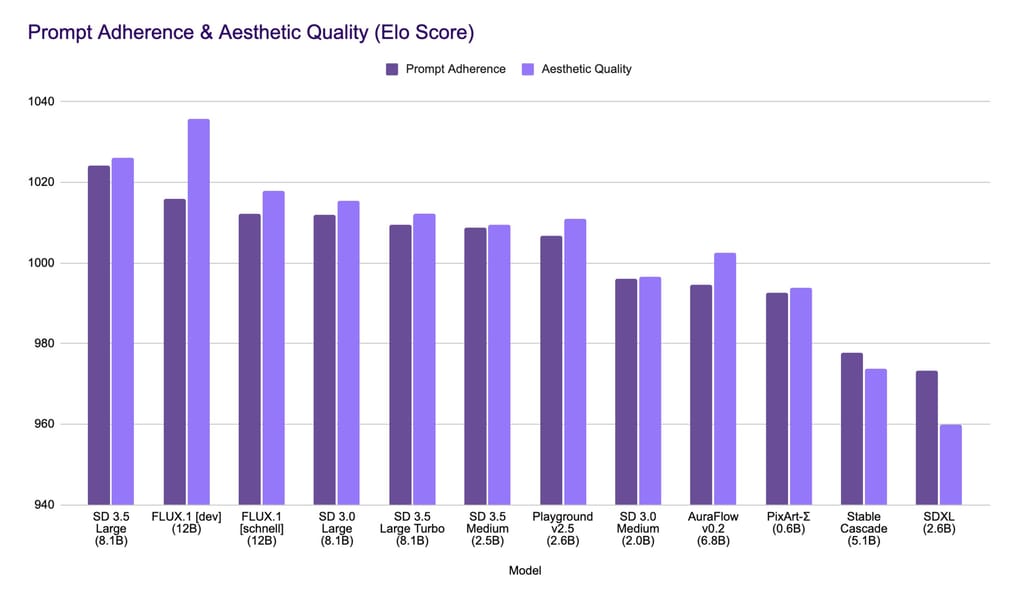
Empirical analysis by Stability AI indicates strong performance in prompt adherence and image quality among diffusion-based text-to-image systems, showing capabilities comparable to models of larger parameter counts, according to a Stability AI blog post. Performance benchmarks indicate consistency in visual quality and representation across various prompts and subject matter.
Comparison chart of prompt adherence and aesthetic quality (Elo Score) for Stable Diffusion 3.5 Large and peer models.
Stable Diffusion 3.5 Large is designed for flexibility and stylistic breadth. The model produces images encompassing a range of genres, including photorealism, illustration, 3D renderings, line art, and digital painting, as stated in the Hugging Face model card. Its outputs are diverse not only in aesthetic but also in depiction, capable of synthesizing visual representations of varied skin tones, features, and subjects with minimal prompting requirements.
Triptych of AI-generated portraits, highlighting the model's ability to produce diverse and realistic representations of people without elaborate prompts.
The model's fine-tuning and customization capabilities enable adaptation to specific creative or professional workflows. Its architecture encourages varied and unpredictable outputs in response to less constrained prompts, broadening its application scope across design, art, education, and research uses, as discussed in a Stability AI blog post.
Example prompt-to-image generations, showcasing the model's nuanced interpretation of detailed textual prompts.
The Stable Diffusion 3.5 family comprises Stable Diffusion 3.5 Large, Stable Diffusion 3.5 Large Turbo, and Stable Diffusion 3.5 Medium, as announced by Stability AI. Stable Diffusion 3.5 Large Turbo is a distilled version designed for rapid image synthesis, performing in as few as four inference steps. Stable Diffusion 3.5 Medium, with 2.5 billion parameters, is designed for broad compatibility. Each variant is tailored for distinct use cases, balancing speed, quality, and resource requirements.
Limitations, Safety, and Licensing
Although Stable Diffusion 3.5 Large incorporates multiple safety mitigations, comprehensive removal of all potential harmful content cannot be assured, as stated on the Stability AI safety page. The model was not developed for factual representation of real-world individuals or events, and outcomes may vary in consistency, especially for vague or underspecified prompts, according to the Hugging Face model card. Developers and researchers are encouraged to conduct independent evaluations and implement supplementary safety measures where necessary.
Stable Diffusion 3.5 Large is released under the Stability Community License, which allows free research and non-commercial use. Commercial usage is free for entities with less than $1 million annual revenue; larger organizations require a separate enterprise license, as outlined in the Stability AI license FAQ. Users retain ownership rights over generated media.
A photorealistic AI-generated image created by Stable Diffusion 3.5 Large, exemplifying its capacity for natural visual depiction from text prompts.
Intended applications include image generation for design, illustration, and art creation, as well as integration in creative and educational tools, as noted in the Hugging Face model card. The model is also suitable for research into generative AI methods and their societal, ethical, or technical boundaries. Usage must adhere to the Acceptable Use Policy established by Stability AI.