Note: Stable Diffusion 3.5 Turbo weights are released under a Stability AI Non-Commercial Research Community License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Diffusion 3.5 Turbo using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Model Report
stabilityai / Stable Diffusion 3.5 Turbo
Stable Diffusion 3.5 Turbo is a text-to-image generation model developed by Stability AI using a Multimodal Diffusion Transformer architecture with three text encoders and Query-Key Normalization. The model employs Adversarial Diffusion Distillation to enable high-quality image synthesis in as few as four denoising steps, providing efficient inference while maintaining prompt adherence and visual fidelity across diverse artistic styles.
Explore the Future of AI
Your server, your data, under your control
Stable Diffusion 3.5 Turbo is a generative image synthesis model developed by Stability AI, forming part of the broader Stable Diffusion 3.5 model family. Released on October 22, 2024, this Turbo variant emphasizes efficient image generation while retaining high image fidelity and prompt alignment. The model represents an evolution of the earlier Stable Diffusion architectures, leveraging innovative neural components and training strategies for improved speed and performance. Stable Diffusion 3.5 Turbo utilizes advanced diffusion techniques and transformer-based designs to generate diverse and highly detailed visual content from text prompts.
A photorealistic example generated by Stable Diffusion 3.5, showcasing the model's ability to synthesize complex visual scenes from text prompts.
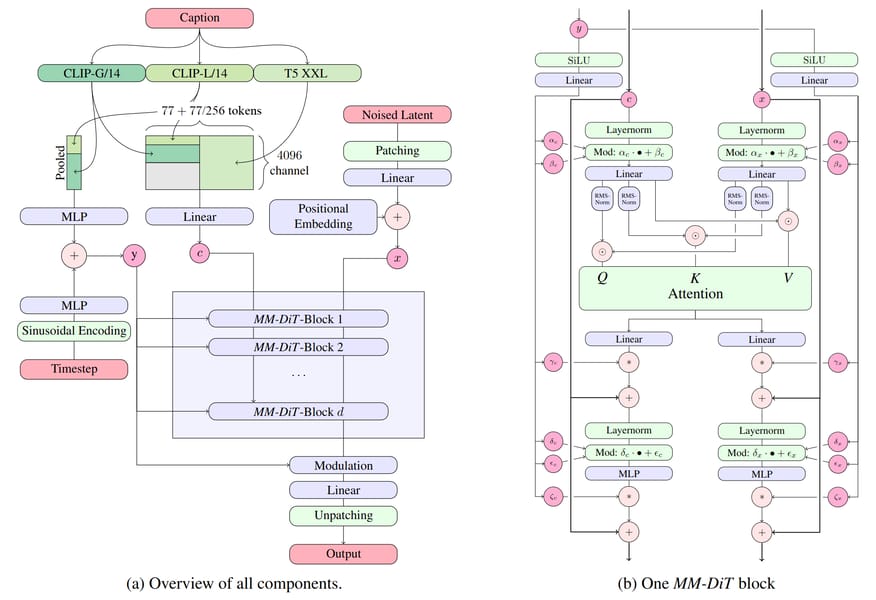
At the technical core of Stable Diffusion 3.5 Turbo lies the Multimodal Diffusion Transformer (MMDiT) framework. This architecture combines the strengths of transformer models with diffusion-based image synthesis, enabling efficient and high-fidelity generative capabilities. The MMDiT system integrates three fixed, pretrained text encoders, specifically OpenCLIP-ViT/G, CLIP-ViT/L, and T5-xxl, each tuned for handling linguistic context at various stages of processing.
One of the distinctive features of this model is the use of Query-Key Normalization (QK-normalization) in its transformer blocks. This mechanism stabilizes the training process and simplifies subsequent fine-tuning. To accelerate image generation, Stable Diffusion 3.5 Turbo employs Adversarial Diffusion Distillation (ADD), a technique that enables the model to achieve high-quality generation with a low number of sampling steps—typically as few as four.
Diagram of the MMDiT architecture, illustrating the integration of multiple text encoders and the internal structure of a single transformer block.
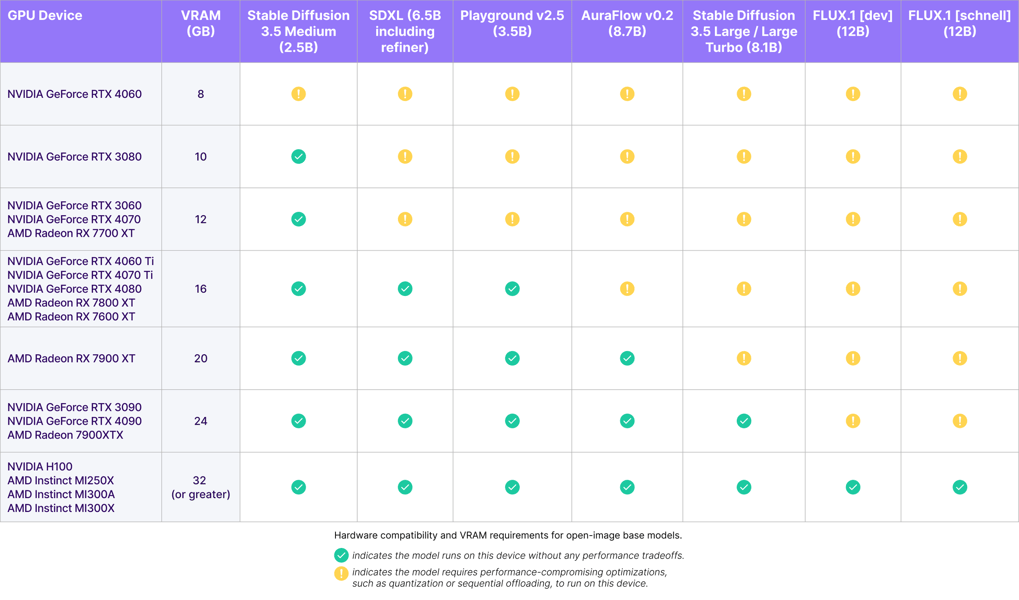
Stable Diffusion 3.5 Turbo is engineered for rapid image generation, providing efficient inference without sacrificing significant prompt adherence or visual quality. The use of ADD distillation allows for image synthesis with as few as four denoising steps, resulting in lower generation latency and reduced computational requirements relative to comparable non-distilled models. The model also includes architectural optimizations making it feasible to run on a range of consumer hardware, as demonstrated by benchmarking data that place Stable Diffusion 3.5 Medium, a related variant, at only 9.9 GB of VRAM usage (excluding text encoders).
VRAM requirements for Stable Diffusion 3.5 Medium and comparable models across various GPU types, illustrating efficiency and compatibility.
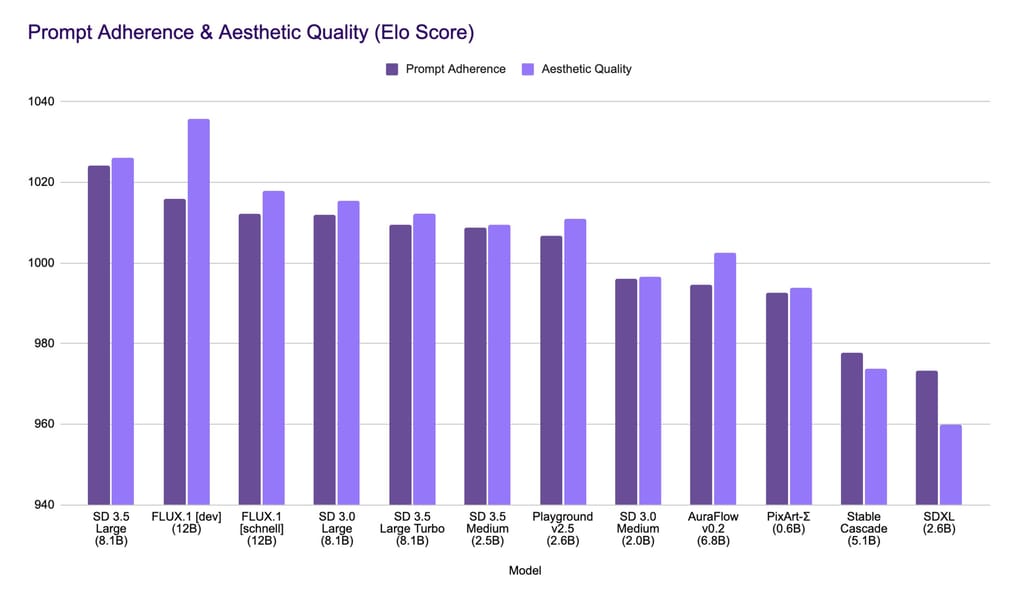
Empirical evaluation has shown that Turbo maintains competitiveness in both qualitative output and prompt alignment metrics. Evaluations against a field of open-source models placed Stable Diffusion 3.5 Large—the foundational architecture for Turbo—among the leaders in prompt adherence and aesthetic quality when assessed with human and automated scoring.
Performance comparison showing prompt adherence and aesthetic quality scores for Stable Diffusion 3.5 family and other models.
Central to the Turbo variant is its ability to consistently generate diverse and realistic outputs, even with minimal explicit instruction in prompts. Dedicated benchmarking scenarios have demonstrated the model’s capacity to produce a wide spectrum of skin tones, facial features, and aesthetic variations, supporting broader representation and creative flexibility.
Triptych of generated portraits showcasing the model's capacity to represent diverse skin tones and features with minimal prompting.
Stylistic versatility is also a defining feature. Stable Diffusion 3.5 Turbo can execute a spectrum of visual genres, from photorealistic rendering and digital painting to stylized illustrations and anime-inspired art. This breadth allows creators and researchers to tailor their outputs for a variety of applications.
Demonstration of varied styles generated by the model: etched illustration, photography, and anime-inspired digital painting.
In addition to classical and photographic styles, the model is capable of incorporating nuanced typography and handling complex, multi-faceted prompts with improved comprehension compared to prior generations.
Training Data and Related Models
Stable Diffusion 3.5 Turbo was trained using a blend of curated publicly available datasets and synthetic image-text pairs. This strategy aids in supporting diversity, generalization, and content safety. The overall Stable Diffusion 3.5 family includes other notable variants such as Stable Diffusion 3.5 Large, a powerful 8.1 billion parameter model well-suited for high-resolution professional use, and Stable Diffusion 3.5 Medium, a 2.5 billion parameter version focused on lower VRAM requirements and rapid customization.
Three example outputs, each generated from a different text prompt, illustrating the model's capacity for prompt-to-image synthesis.
While Stable Diffusion 3.5 Turbo advances generative image capabilities, certain limitations are inherent to its design and training process. Output diversity is prioritized, which can introduce variability in results for similar prompts, especially in the absence of detailed guidance. The model is intended for creative generation rather than factual representation, and its outputs are not designed to be accurate depictions of real events or individuals. Datasets have been filtered to reduce the presence of potentially harmful or inappropriate content, but comprehensive content safety is not guaranteed, and users are encouraged to implement their own safeguards.
The model's intended use includes artistic synthesis, educational and creative tool development, and academic research into generative methods. Developers and deployers are urged to follow privacy regulations and ethical standards, particularly regarding user data and generated content.
Licensing and Accessibility
All Stable Diffusion 3.5 models, including Turbo, are provided under the Stability AI Community License. This permissive license enables free use for non-commercial purposes, including research and education, and for commercial purposes by organizations with annual revenues up to $1 million. Generated media remain the property of their creators, without restrictive downstream licensing. Uses must comply with Stability AI's Acceptable Use Policy.