Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 2 7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 2 7B
Qwen2-7B is a 7.6 billion parameter decoder-only Transformer language model developed by Alibaba Cloud as part of the Qwen2 series. The model features Group Query Attention, SwiGLU activations, and supports a 32,000-token context length with extrapolation capabilities up to 128,000 tokens. Trained on a multilingual dataset covering 29 languages, it demonstrates competitive performance in coding, mathematics, and multilingual tasks compared to similarly-sized models like Mistral-7B and Llama-3-8B.
Explore the Future of AI
Your server, your data, under your control
Qwen2-7B is a 7.6 billion parameter generative language model developed as part of the Qwen2 series by the Qwen team. Positioned as a foundational model rather than a ready-to-deploy chatbot, Qwen2-7B is intended primarily for further post-training, such as supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), or continued pretraining. The architecture, multilingual support, and rigorous evaluation position Qwen2-7B as a platform for research and applied natural language processing across diverse domains, as detailed in the Qwen2 blog post and the QwenLM GitHub repository.
Header image from the Qwen2 announcement, visually representing the series’ brand and modern aesthetic.
Qwen2-7B is implemented as a decoder-only Transformer model, incorporating features to optimize efficiency and linguistic adaptability. The architecture utilizes SwiGLU activations, attention QKV bias, and Group Query Attention (GQA), a technique implemented across the Qwen2 suite to enable faster inference and lower memory usage, as described in the QwenLM documentation. The improved tokenizer is engineered for high adaptability across numerous natural languages and programming codes.
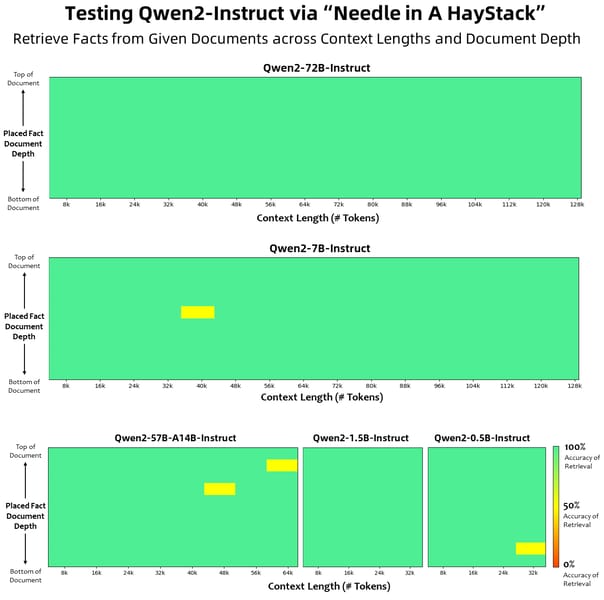
The pretraining context length is 32,000 tokens, allowing the model to process extended inputs in a single sequence. Qwen2-7B exhibits extrapolation up to 128,000 tokens in perplexity-based evaluations. This capability is further extended in the instruction-tuned variant, Qwen2-7B-Instruct, particularly when augmented with mechanisms like YARN for long-context tasks, as evaluated in the Needle in a Haystack Evaluation.
Multilingual Pretraining and Data
A central focus of Qwen2-7B's development was comprehensive multilingual coverage. The model was trained using a balanced and diversified dataset spanning 29 languages. Alongside English and Chinese, training incorporated substantial text in languages such as German, French, Spanish, Russian, Arabic, Japanese, Korean, Vietnamese, and Hindi, among others. This breadth enables enhanced cross-lingual capabilities and improved code-switching performance for both monolingual and mixed-language inputs, as noted in the Qwen2 blog post.
Notably, the pretraining corpus for Qwen2 benefited from improved dataset curation over previous generations. Datasets included both standard natural language corpora and collections of programming code, supporting superior results in coding benchmarks.
Benchmarking and Evaluation
Qwen2-7B was systematically evaluated against other models such as Mistral-7B, Gemma-7B, Llama-3-8B, and its predecessor Qwen1.5-7B. Across diverse benchmarks, Qwen2-7B demonstrates competitive or superior performance, especially in coding, mathematics, and Chinese language tasks.
Instruction-tuned versions, notably Qwen2-7B-Instruct, show the ability to process very long contexts (up to 128,000 tokens) with high factual retrieval accuracy. In the "Needle in a Haystack" task, Qwen2-7B-Instruct maintains robust information extraction capacity across a broad range of context lengths, as shown in the Needle in a Haystack Evaluation.
Heatmaps visualizing Qwen2-Instruct models’ accuracy in the Needle in a Haystack task. Qwen2-7B-Instruct maintains high accuracy even at context lengths up to 128K tokens.
Evaluation results indicate Qwen2-7B performs strongly relative to peer models in the following domains:
General knowledge (MMLU, MMLU-Pro, GPQA)
Problem-solving (TheoremQA, BBH)
Coding (HumanEval, MBPP, MultiPL-E)
Mathematics (GSM8K, MATH)
Chinese and other multilingual tasks (C-Eval, CMMLU, Multi-Exam, Multi-Understanding)
For example, Qwen2-7B achieves a score of 51.2 on the HumanEval coding benchmark and 79.9 on GSM8K for grade-school mathematics, outperforming several similarly sized models, as detailed in the Qwen2 blog post. Across most multilingual and Chinese tasks, it typically leads or matches the highest scores among its peer group.
Training Methods and Model Development
The Qwen2-7B model leverages carefully curated datasets and a sequence of training methodologies. While the base model is suited for further adaptation, instruction-tuned variants undergo additional alignment using instruction-following datasets and scalable oversight techniques. Human alignment is realized through methods including rejection sampling in mathematics, execution feedback in coding, and back-translation for creative writing tasks.
The training process utilizes a mix of supervised fine-tuning and reinforcement learning, alongside innovations such as the Online Merging Optimizer, which targets minimization of the "alignment tax"—a reduction in model ability due to post-training alignment, as discussed in the Qwen2 blog post.
For scaling to long contexts, approaches such as YARN and Dual Chunk Attention are incorporated, facilitating the model’s robust extrapolation to larger token windows—a trait validated in practical and synthetic long-context tests.
Applications, Limitations, and Licensing
Qwen2-7B is primarily offered for further post-training, serving as a base for research and downstream specialization rather than being a direct text generator. The instruction-tuned variant, Qwen2-7B-Instruct, is designed for scenarios requiring extensive context management, such as document-level understanding and long-sequence information extraction within a 128,000-token window.
While Qwen2-7B generally matches or surpasses its peers, some benchmarks indicate minor performance gaps relative to certain models in specific English tasks or translation challenges. The base model is not recommended for immediate end-user deployment before some form of adaptation or alignment. The model is released under the Apache 2.0 license, supporting open research, development, and commercial use.
Related Models in the Qwen2 Family
Qwen2-7B is part of a broader series, with both base and instruction-tuned variants available across several model sizes—including Qwen2-0.5B, Qwen2-1.5B, Qwen2-57B-A14B (a mixture-of-experts model), and Qwen-2-72B. All models in the Qwen2 series deploy Group Query Attention for memory efficiency and scaling, as noted in the QwenLM GitHub repository. Larger models in the family exhibit even higher performance on demanding benchmarks, as demonstrated in the release documentation and visualized in comparative tables.