Note: Stable Video Diffusion XT weights are released under a Stability AI Non-Commercial Research Community License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Stable Video Diffusion XT using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
stabilityai / Stable Video Diffusion XT
Stable Video Diffusion XT is a generative AI model developed by Stability AI that extends the Stable Diffusion architecture for video synthesis. The model supports image-to-video and text-to-video generation, producing up to 25 frames at resolutions supporting 3-30 fps. Built on a latent video diffusion architecture with over 1.5 billion parameters, SVD-XT incorporates temporal modeling layers and was trained using a three-stage methodology on curated video datasets.
Explore the Future of AI
Your server, your data, under your control
Stable Video Diffusion XT (SVD-XT) is a state-of-the-art generative artificial intelligence model for video synthesis developed by Stability AI. Released as part of an ongoing research initiative, SVD-XT extends the Stable Diffusion architecture from still image generation to high-quality video creation, supporting both image-to-video and text-to-video capabilities. The model is particularly notable for its scalable training methods, advanced motion representation, and ability to generate coherent video sequences from static images or textual prompts.
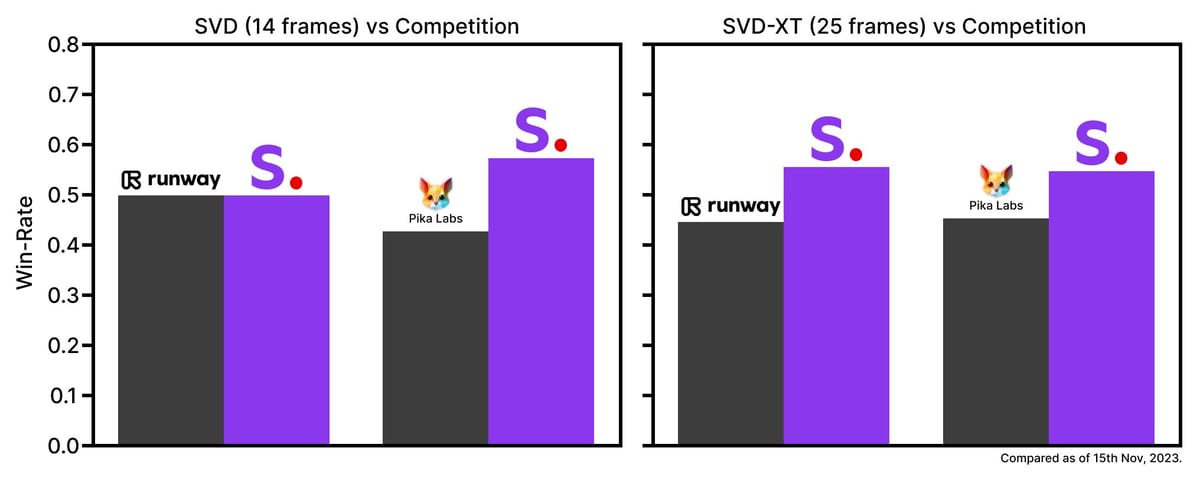
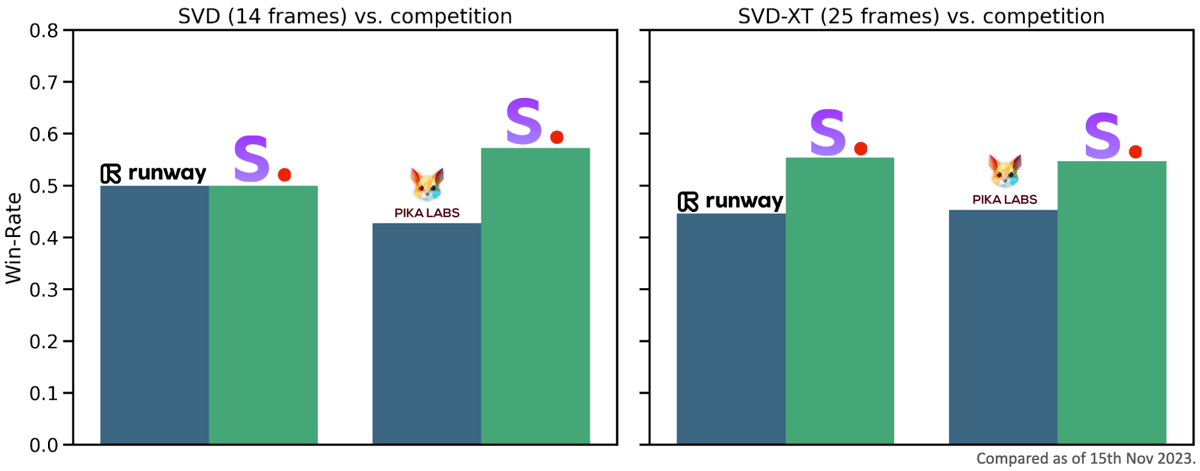
Bar graphs illustrating the 'Win-Rate' of Stable Video Diffusion (SVD and SVD-XT) against competing video generation models as of November 2023.
SVD-XT is based on a latent video diffusion model architecture, inheriting critical innovations from Stable Diffusion 2.1. The architecture extends the 2D UNet backbone of Stable Diffusion by integrating temporal convolution and attention layers after each spatial layer, thereby enabling the model to handle the temporal coherence required for video generation.
The model initializes with pretrained image diffusion weights and introduces approximately 656 million additional parameters dedicated to temporal modeling, resulting in a total of over 1.5 billion parameters. SVD-XT adopts an EDM-framework for noise preconditioning, essential for achieving stability at higher resolutions. Frame rate and motion scores are employed as micro-conditioning factors during training, allowing users to generate videos with customizable motion styles at inference time.
For the image-to-video pathway, SVD-XT incorporates a variant of classifier-free guidance where the guidance scale increases across the generated frames, effectively reducing common artifacts such as color oversaturation or temporal inconsistencies.
Animated demonstration of Stable Video Diffusion generating a video sequence from a single still image (image-to-video). Input: Still image of a person in a dark hood, Output: Video with motion and blinking.
The training procedure for SVD-XT follows a systematic three-stage strategy designed to maximize generalization and video fidelity. The first stage consists of image pretraining using Stable Diffusion 2.1, providing a robust visual representation. The second stage involves video pretraining on a carefully curated large-scale dataset known as the Large Video Dataset (LVD), which initially consists of approximately 580 million pairs of annotated video clips. Subsequent filtering and quality control reduce this dataset to a higher-quality LVD-F, encompassing 152 million video examples.
SVD-XT relies on advanced data curation techniques, including cut detection to identify scene transitions, keyframe-aware clipping, and dense optical flow analysis to filter out redundant or static content. Additionally, synthetic captioning is employed: captions are generated using both image and video neural captioners, along with large language model-based summarization to provide comprehensive temporal and spatial descriptions. To mitigate quality and relevance issues, CLIP embeddings are used to score aesthetics and text-image correspondence, and extensive optical character recognition removes excessive textual content from the video samples.
The final finetuning stage uses a high-resolution, high-quality subset of about one million videos, enabling the model to generalize well while producing visually coherent outputs. Specialized finetuning on multi-view datasets such as Objaverse and MVImgNet further enables the model to generate consistent multiple viewpoints from single images.
Capabilities and Performance
SVD-XT supports generating video sequences from a static image or textual prompt, enabling both short-form content synthesis and novel-view generation. For image-to-video, SVD-XT is capable of generating up to 25 frames per sequence, supporting frame rates from 3 to 30 frames per second. The model can be further fine-tuned for multi-view synthesis, frame interpolation, and explicit motion control based on temporal prompting or finetuned LoRA modules.
In third-party and internal evaluation, SVD-XT demonstrates competitive performance in comparison to closed-source models. Human preference studies show higher user-rated win rates for SVD-XT (25-frame output) relative to alternative models such as GEN-2 and PikaLabs in the visual quality of generated clips. In zero-shot text-to-video tasks, SVD-XT outperforms several baselines in standardized benchmarks, such as the UCF-101 dataset, with improved metrics like FVD (Fréchet Video Distance).
Evaluation charts showing SVD (14 frames) and SVD-XT (25 frames) win-rates over Runway and Pika Labs in user assessments of video quality.
The model achieves robust results in multi-view object synthesis, with SVD-MV—a version finetuned for this task—achieving lower LPIPS scores and higher PSNR and CLIP-S metrics on datasets like Google Scanned Objects as compared to image-based methods including Zero123XL and SyncDreamer.
Applications and Limitations
SVD-XT is suitable for a variety of creative and research-oriented applications. Notable use cases include generating dynamic content for digital media, facilitating educational demonstrations, enabling multi-view rendering of 3D objects from a single perspective, and supporting research into generative and video synthesis models. Its outputs are utilized for artistic expression and content creation workflows.
However, the model does present several limitations. The duration of generated clips is currently short (typically under four seconds), constraining use in longer-form video applications. While outputs are temporally coherent, they may not achieve perfect photorealism or precise motion control in all scenarios. The model faces challenges in rendering fine, legible text, and the generation of human faces or people may not always meet high-fidelity expectations. Sampling speed and computational requirements can be prohibitive for some users, and the autoregressive nature of video diffusion contributes to slower inference.
SVD-XT was released as a research-only model, not intended for immediate commercial deployment. As with all generative video models, there is a potential risk for misinformation or misuse; accordingly, safety measures are employed during training and enforced at the user interface level.
Licensing and Ethical Considerations
The model weights and code for SVD-XT are made available under a research and non-commercial license, with commercial licensing governed by the Stability AI commercial license. Users must comply with the Acceptable Use Policy, which prohibits generating misleading or offensive content and restricts applications inconsistent with the intended research purposes. Automated watermarking is enabled by default to help attribute generated media. Safety filters, red-teaming, and data quality controls are an integral part of the release, aiming to reduce the risk of unintended or harmful outputs.
Related Models and Future Directions
Stable Video Diffusion XT represents an evolution of the foundational Stable Diffusion image model towards temporally consistent video synthesis. The model family includes configurations such as SVD (14 frames) and SVD-XT (25 frames), addressing different video lengths and motion requirements. Specialized finetunes (e.g., for multi-view object rendering) expand the model’s utility for scientific visualization and creative industries. Comparisons with related generative models, such as Runway's GEN-2 and Pika Labs, situate SVD-XT within an active research field focused on advancing video quality, frame coherence, and control capabilities.
Ongoing research explores extending video length, improving photorealism, and enhancing user-driven motion and camera control, with a focus on minimizing computational demands while maximizing model versatility.