Launch a dedicated cloud GPU server running Laboratory OS to download and run Kimi K2 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Moonshot AI / Kimi K2
Kimi K2 is an open-source mixture-of-experts language model developed by Moonshot AI, featuring 1 trillion total parameters with 32 billion activated per inference. The model utilizes a 128,000-token context window and specializes in agentic intelligence, tool use, and autonomous reasoning capabilities. Trained on 15.5 trillion tokens with reinforcement learning techniques, it demonstrates performance across coding, mathematical reasoning, and multi-step task execution benchmarks.
Explore the Future of AI
Your server, your data, under your control
Kimi K2 is an open-source mixture-of-experts (MoE) large language model developed by Moonshot AI with a design focus on agentic intelligence, tool use, and autonomous reasoning. Released in 2025, Kimi K2 is engineered to handle complex multi-step tasks, facilitate tool integration, and support extensive context windows for problem-solving. The architecture, training corpus, and optimization strategies have been constructed to enable performance across language, reasoning, coding, and agentic benchmarks, using innovations in large-scale agentic data generation and reinforcement learning.
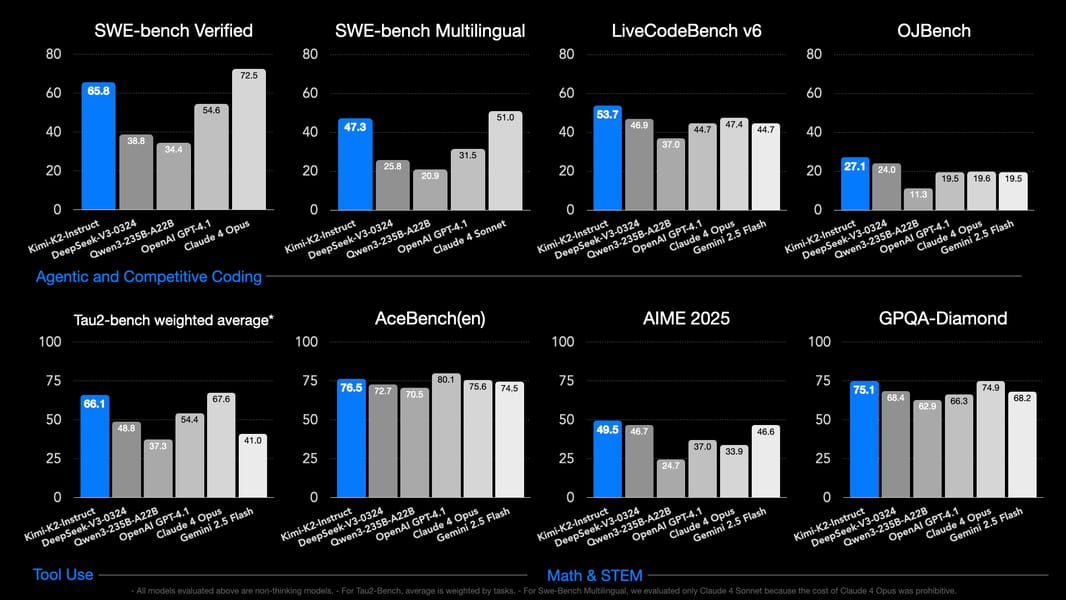
Comparative evaluation showing Kimi-K2-Instruct's performance on agentic coding, tool use, and STEM benchmarks versus leading open and proprietary models.
Kimi K2 utilizes a mixture-of-experts (MoE) approach, comprising 1 trillion total parameters, of which 32 billion are activated per inference pass. The network has 61 dense layers, an attention hidden dimension of 7168, and 384 experts with 8 experts selected per token and an additional shared expert to improve generalization. The model employs a vocabulary of 160,000 tokens and supports a context length of 128,000 tokens, enabling it to process and generate long sequences of text. Within each layer, a SwiGLU activation function and MLA attention mechanism are utilized, with 64 attention heads per layer for context management.
For optimization, Kimi K2 is trained using the MuonClip optimizer, which directly rescales the weight matrices of query and key projections after updates. This stabilization is crucial to prevent issues such as exploding attention logits, a challenge observed more frequently with the Muon optimizer compared to AdamW. The optimizer adaptively sets rescaling factors at each step, ensuring robust training dynamics.
Two principal variants are distributed: Kimi-K2-Base, geared for customization and research use, and Kimi-K2-Instruct, which has undergone instruction fine-tuning for general-purpose chat, agentic workflows, and autonomous tool use.
Training Methods and Data
Kimi K2's capabilities are rooted in an extensive pre-training phase over 15.5 trillion tokens, leveraging diverse data. Key to its agentic intelligence, the pre-training corpus includes large-scale agentic data synthesis, inspired by pipelines similar to ACEBench. This agentic dataset simulates real-world tool-use environments, evolving hundreds of domains and thousands of tools—both real and synthetic—across thousands of agents. Interactions are rubric-based for consistent evaluation, with a large language model (LLM) serving as a judge to filter simulation results and enforce data quality using rejection sampling.
To further optimize for complex reasoning and long-horizon task execution, Kimi K2 is trained with general reinforcement learning, combining self-judgment mechanisms for non-verifiable tasks and on-policy rollouts for verifiable rewards in mathematical problem solving and competitive coding. These approaches foster scalable, rubric-based feedback and policy-driven policy improvements.
The model's token efficiency reflects an intentional strategy to maximize learning from limited human data resources, a consideration crucial for models designed to engage in agentic interaction.
On tool use and multi-domain interaction tasks such as Tau2 and AceBench, Kimi K2 demonstrates performance in accuracy and cross-domain capability. In STEM and mathematical reasoning, it achieves 97.4% on MATH-500 and 92.7% on MMLU-Redux. The Kimi-K2-Base variant, using only pre-training, also attains results such as 87.8 EM on MMLU.
These benchmark results provide a quantitative assessment of Kimi K2's capabilities across domains requiring knowledge, logical reasoning, coding, and agentic tool use.
Agentic Intelligence and Applications
A defining characteristic of Kimi K2 is its agentic intelligence, which extends beyond traditional language modeling into dynamic task execution and tool-based problem solving. The model is engineered to plan, select, and invoke external tools to fulfill complex user requests and to reason through multi-step workflows.
Kimi K2's agentic design enables applications such as autonomous data analysis, end-to-end web development, project planning, and interactive information retrieval. For example, it can analyze structured datasets, generate statistical summaries, and create visualizations as part of a data science workflow. In coding automation, Kimi K2 can iteratively edit files, run commands, debug, and capture logs within development environments, supporting software engineering tasks such as JavaScript development or project scaffolding.
The agentic pipeline includes rubric-driven evaluation, tool definition parsing, and an inference engine capable of supporting native tool invocation. This infrastructure allows for integration in domains where multi-tool composition and adaptive problem-solving are needed, without requiring bespoke workflow orchestration.
Limitations and Future Development
Despite its capabilities, Kimi K2 presents several known limitations. Challenges can occur in tasks involving ambiguous tool definitions or high-complexity reasoning, where the model may generate excessive tokens or deliver incomplete outputs. Tool-enabled performance may also degrade for certain use cases compared to agentic frameworks designed for extended, interactive sessions.
While Kimi K2's context management is functional, its current iteration does not support computer vision or multimodal tasks, though these features are identified for future versions. For large-scale software engineering or multi-stage project builds, performance is maximized within structured, multi-turn agentic frameworks rather than single-shot prompt completions.
Kimi K2 was open-sourced by Moonshot AI in 2025, with continued updates to its tokenizer, system prompts, and chat templates to improve both usability and robustness. Its checkpoints are distributed in block-fp8 format and optimized for compatibility with popular inference engines such as vLLM, SGLang, KTransformers, and TensorRT-LLM.
Adhering to the Modified MIT License, Kimi K2 encourages community-driven innovation in large-scale language and agentic model research.