Launch a dedicated cloud GPU server running Laboratory OS to download and run MPT-7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
MosaicMl / MPT-7B
MPT-7B is a 6.7 billion parameter decoder-only transformer model developed by MosaicML, trained on 1 trillion tokens of English text and code. The model features FlashAttention and ALiBi for efficient attention computation and extended context handling, enabling variants like StoryWriter-65k+ to process up to 65,000 tokens. Released under Apache 2.0 license, it serves as a foundation for further fine-tuning across various applications.
Explore the Future of AI
Your server, your data, under your control
The Mosaic Pretrained Transformer 7B (MPT-7B) is a large-scale, decoder-style transformer model introduced by MosaicML on May 5, 2023. Distinguished by its open-source, commercially usable license and technical optimization for efficient training and inference, MPT-7B is a foundational member of the MPT model family. It was pretrained on a substantial dataset of English text and code, designed to promote adaptability as a base for further fine-tuning across varied downstream tasks.
Promotional illustration for MPT-7B, a foundational model series developed by MosaicML.
MPT-7B employs a decoder-only transformer architecture, tailored for stability and high performance. Central to its design are two major innovations: the use of FlashAttention for accelerated attention computations and Attention with Linear Biases (ALiBi) for efficient handling of both short and very long sequences. Unlike traditional transformers that rely on positional embeddings, ALiBi allows the model to extrapolate to much longer contexts than those seen during training while maintaining memory efficiency.
The model comprises approximately 6.7 billion parameters, organized in 32 layers with 32 attention heads per layer and a model dimension of 4096. Bias terms are omitted, and optional QK LayerNorm enhances training efficiency. MPT-7B is trained using the LION optimizer, selected for stable update magnitudes and reduced optimizer state memory compared to more commonly used optimizers such as AdamW.
Training Data and Methods
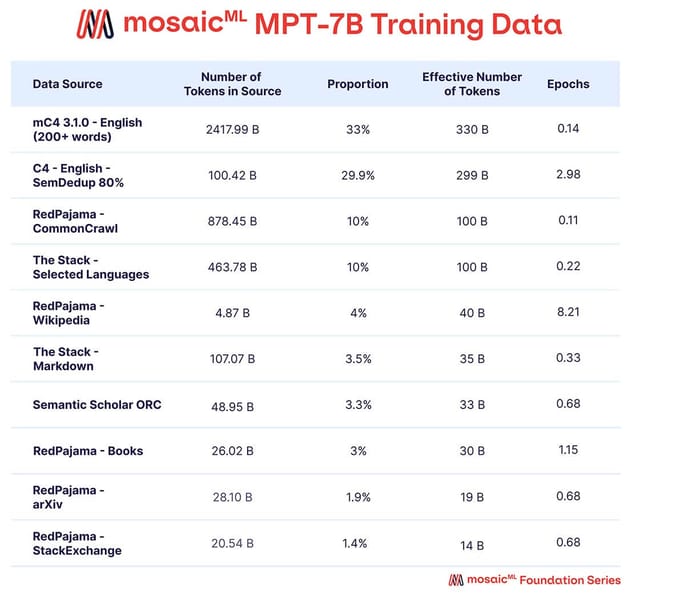
MPT-7B was trained on a mixture of large-scale public datasets totaling 1 trillion tokens, encompassing both English natural language and code. This training set size is comparable to other leading open-source models. Key data sources include mC4, C4 with semantic deduplication, RedPajama CommonCrawl and Wikipedia splits, The Stack code corpus, S2ORC scientific papers, and several others.
Proportional breakdown of the data sources used in pretraining MPT-7B.
Efficient training was made possible through the StreamingDataset library, which streams data during training and enables seamless resumption following interruptions. Tokenization leverages the EleutherAI GPT-NeoX-20B tokenizer, chosen for its robust handling of code and text, space delimitation, and improved compression of whitespace sequences. The vocabulary size of 50,432 is a multiple of 128, producing marginal improvements in model flop utilization as highlighted by Karpathy.
Training Procedure and Infrastructure
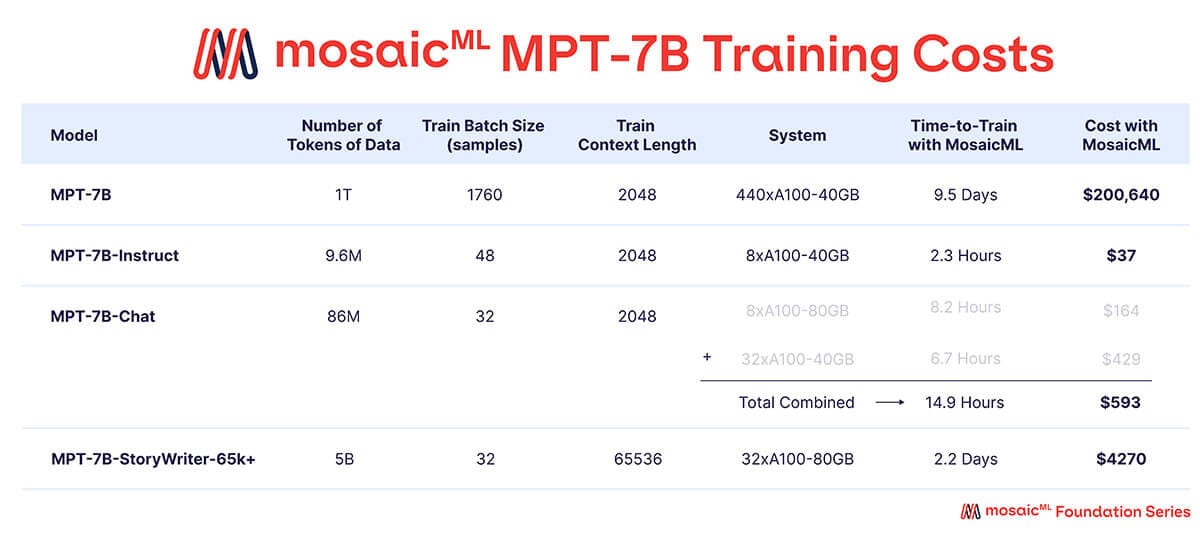
The pretraining of MPT-7B was conducted on clusters comprising 440 Nvidia A100-40GB GPUs. The process lasted approximately 9.5 days and utilized a batch size of 1,760 samples, each with a sequence length of 2,048 tokens. Training employed sharded data parallelism via FullyShardedDataParallel (FSDP) and was managed on the MosaicML platform, which provided automated fault tolerance. The pretraining run cost an estimated 200,000 USD.
A summary of training costs, system configuration, and runtime for MPT-7B and its variants.
The platform's robust design automatically handled hardware interruptions without manual intervention, as illustrated by the training logbook and evident in the smooth recovery demonstrated on the loss curve.
Excerpt from the MPT-7B training log, showing the system's automated response to hardware failures.
MPT-7B was evaluated across 11 standard academic tasks using the LLM Foundry evaluation framework, ensuring that prompt strings or prompt tuning did not bias results. The model's zero-shot performance is competitive with other open-source models of similar scale, including LLaMA-7B, Pythia, and StableLM.
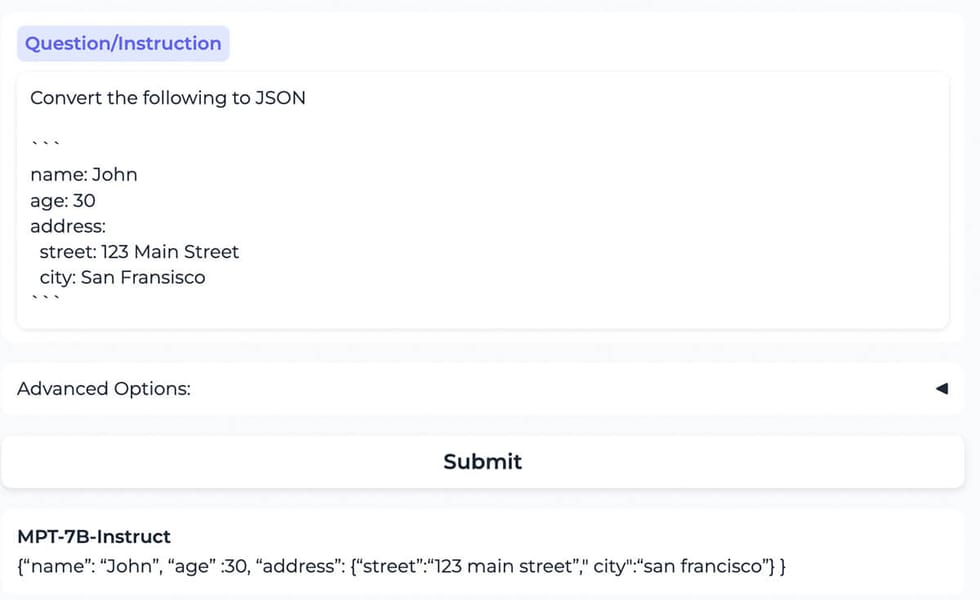
Example of MPT-7B generating a tweet and responding to user queries, demonstrating its text generation and conversation abilities.
Through the integration of FlashAttention and infrastructure adaptations like NVIDIA's FasterTransformer, MPT-7B delivers fast inference—reported as 1.5x to 2x faster than comparable models out-of-the-box.
Variants in the MPT Family
The foundational MPT-7B model enables fine-tuning for targeted applications. Notable variants include:
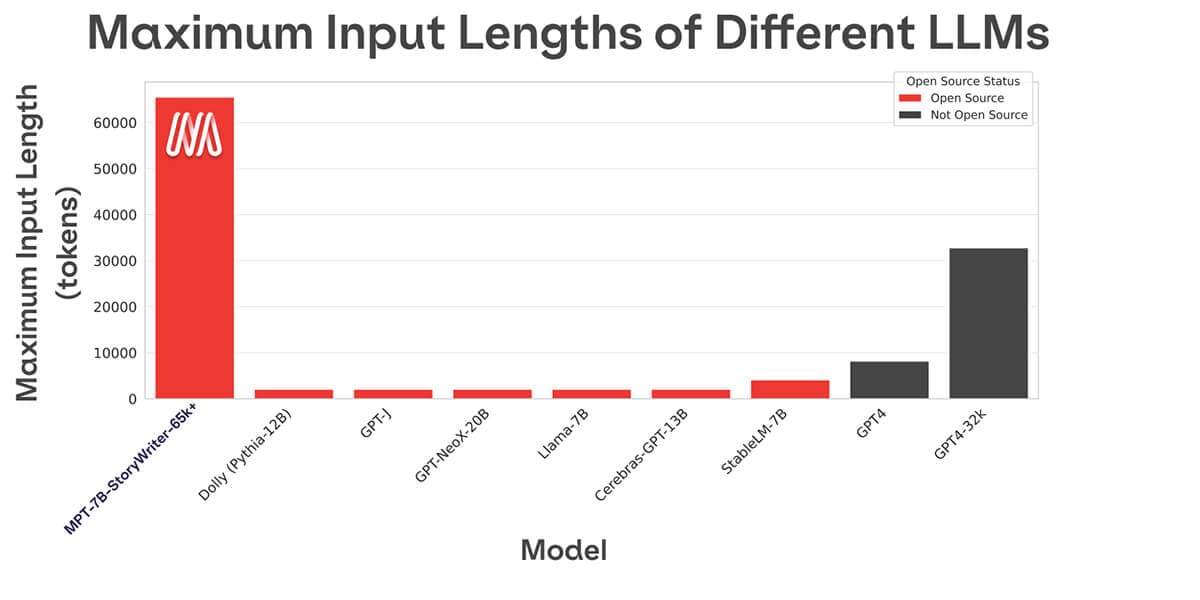
MPT-7B-StoryWriter-65k+, finetuned for long-form fiction, demonstrates extended context handling up to 65,000 tokens using ALiBi. This capacity is illustrated by generating entirely new story endings with substantial input context.
Comparison of maximum input lengths for major LLMs, highlighting MPT-7B-StoryWriter-65k+ support for extremely long inputs.
Each variant is released under a specific license, detailed in their respective documentation, with the base MPT-7B under Apache 2.0 to allow broad commercial usage.
Applications and Limitations
MPT-7B is intended as a base model for further finetuning rather than for direct deployment in human-facing applications. Its strengths include serving as a starting point for developing custom language models in varied research and industry settings and enabling tasks requiring long-context handling, such as large document summarization or legal text analysis.
Users should be aware that, as with all generative large language models, MPT-7B can produce factually incorrect or undesired outputs and is not suitable for unsupervised deployment without appropriate finetuning or safety mechanisms. Its outputs may reflect biases present in public data sources. For any production or commercial use, due diligence with respect to the licensing terms and further finetuning is recommended.