Launch a dedicated cloud GPU server running Laboratory OS to download and run FLUX.1 [schnell] using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
black-forest-labs / FLUX.1 [schnell]
FLUX.1 [schnell] is a 12-billion parameter text-to-image generation model developed by Black Forest Labs using hybrid diffusion transformer architecture with rectified flow and latent adversarial diffusion distillation. The model generates images from text descriptions in 1-4 diffusion steps, supporting variable resolutions and aspect ratios. Released under Apache 2.0 license, it employs flow matching techniques and parallel attention layers for efficient synthesis.
Explore the Future of AI
Your server, your data, under your control
FLUX.1 [schnell] is a text-to-image generative AI model developed by Black Forest Labs as part of the FLUX.1 suite. Designed for speed and efficiency, FLUX.1 [schnell] leverages architectural features to enable rapid image synthesis with specified characteristics from textual descriptions, supporting diverse styles, resolutions, and aspect ratios. Released openly under the Apache 2.0 license, the model is tailored for local development and individual use, while maintaining capabilities aligned with the intended scope of the FLUX.1 family of foundational media generation models.
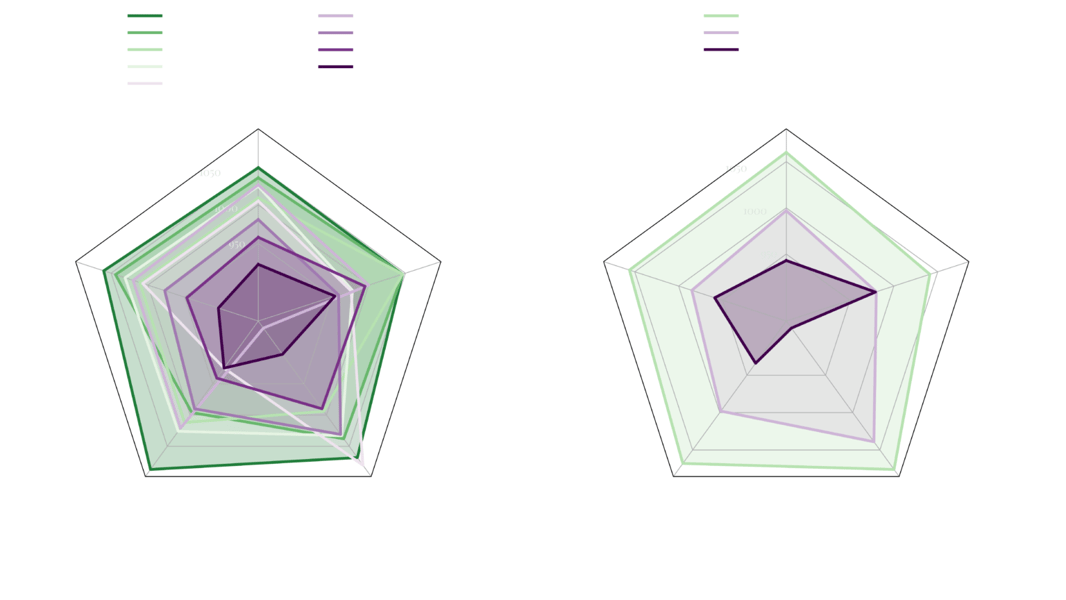
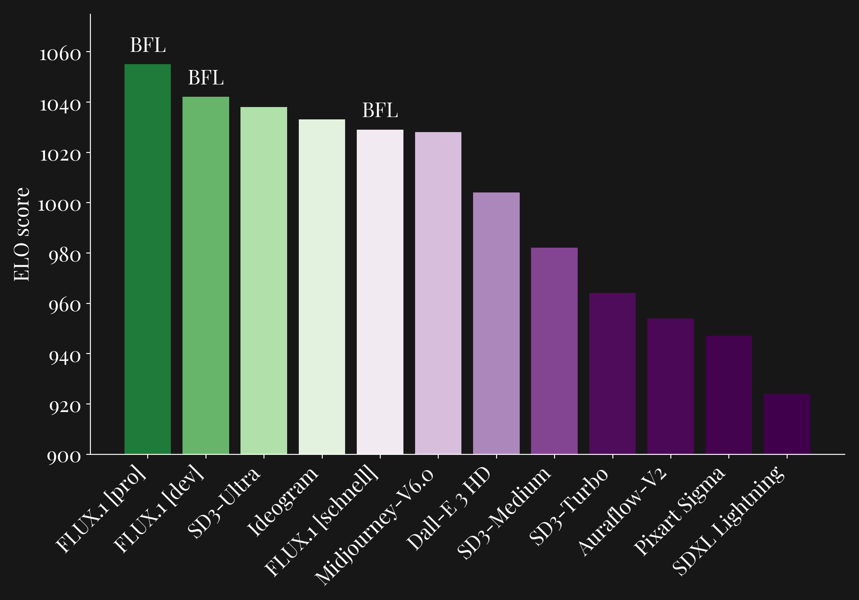
ELO score benchmarks comparing the FLUX.1 model family, including FLUX.1 [schnell], against other prominent image generation models.
FLUX.1 [schnell] is built on a hybrid architecture that combines multimodal and parallel diffusion transformer blocks, underpinned by the rectified flow transformer paradigm. The model contains 12 billion parameters, incorporating features such as rotary positional embeddings and parallel attention layers to contribute to generative fidelity and hardware efficiency. Its architecture supports rapid sampling—producing image outputs with specified characteristics in as few as 1 to 4 diffusion steps.
FLUX.1 [schnell] uses latent adversarial diffusion distillation, a method that distills the capabilities of larger, more computationally intensive models into a faster, more efficient student model, while maintaining output quality, scene complexity, and style diversity. The model’s training pipeline also draws upon flow matching techniques to generalize the process of learning generative dynamics beyond conventional diffusion, thereby supporting diverse image synthesis.
Varied outputs from FLUX.1 [schnell], illustrating prompt adherence, detail, and diverse visual styles. Prompts (left to right, top to bottom) include: 'the word SCHNELL made from vegetables', 'the inside of a watch', 'sunbeams streaming into a coral reef', 'a regal hedgehog on a throne', and 'tiny wizard next to a boot, line art'.
Evaluations indicate FLUX.1 [schnell] is a few-step text-to-image model in its parameter and speed class. According to internal benchmarks published by Black Forest Labs and public comparisons on Hugging Face, the model demonstrates performance in prompt adherence, visual quality, output diversity, and adaptability to variable resolutions and aspect ratios.
A collage displaying images of a dog on a skateboard at the beach and a vintage train in a mountainous station, demonstrating FLUX.1 models’ flexibility in producing outputs across a wide range of aspect ratios and resolutions.
Key metrics include ELO scores and performance in prompt following, output diversity, and visual accuracy. Benchmarking against contemporaries such as Midjourney v6.0 and DALL·E 3 (HD) is visualized in radar and bar charts, reflecting FLUX.1 [schnell]'s standing among models with similar capabilities in categories like typography, size and aspect variability, and overall image quality.
Training Data, Methods, and Model Family
FLUX.1 [schnell] is trained on extensive datasets using a combination of strategies to support generalization and output diversity. The model’s foundation relies on methods such as flow matching, which generalizes diffusion-based training processes and supports efficient path sampling through data space. The integration of rotary positional embeddings and parallel attention is designed to contribute to spatial reasoning and efficiency within transformer layers.
As part of the FLUX.1 suite, FLUX.1 [schnell] shares its core architecture with other variants such as FLUX.1 [pro] and FLUX.1 [dev]. The [pro] variant offers distinct performance characteristics via proprietary endpoints, while [dev] is an open-weight model guidance-distilled from [pro] and primarily targeted at non-commercial and research applications. All models in this family implement the same 12B-parameter hybrid framework and utilize similar methodological advances in generative modeling.
Minimalist line chart symbolizing performance or feature improvements across the FLUX.1 model family.
The primary use case for FLUX.1 [schnell] is text-to-image generation tailored for local experimentation, research, and artistic workflows. Its speed and adaptable output resolution make it suitable for scenarios that require quick iteration, prompt engineering, or style exploration. The open Apache 2.0 license also permits commercial applications, provided usage adheres to relevant regulations and ethical guidelines.
Developers can deploy FLUX.1 [schnell] via its GitHub repository and leverage integrations—such as the 🧨 Diffusers library and ComfyUI node-based workflows—to incorporate the model into custom pipelines.
Despite its utility, FLUX.1 [schnell] has notable constraints. It does not serve as a source of factual information and may exhibit prompt-following limitations based on phrasing or intricacy of the input. As with other large-scale generative models, outputs can reflect and amplify societal biases present in the training data. The license prohibits its use in contexts that violate laws, promote harm, facilitate disinformation, or automate adverse legal decision-making.
Development, Release, and Context
Black Forest Labs publicly launched FLUX.1 [schnell] alongside the full FLUX.1 suite, developed to contribute to text-to-image synthesis. The project builds on a heritage that includes contributions to prior generative modeling such as VQGAN, Latent Diffusion, Stable Diffusion 1.5, SDXL, and SVD.



![Collage of five images generated by FLUX.1 [schnell]](https://openlaboratory.ai/cdn-cgi/image/width=1200,height=600,quality=80/https://media.openlaboratory.ai/model-reports/model-images/d6d3a3ef89b0141cb17dc44f2cee6948f6131d7aaa0131f5f4af911518729a99.jpeg)