Launch a dedicated cloud GPU server running Laboratory OS to download and run Yi 1.5 6B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
01.AI / Yi 1.5 6B
Yi 1.5 6B is a bilingual Transformer-based language model developed by 01.AI, trained on 3 trillion words of multilingual data. The model supports both English and Chinese for tasks including language understanding, commonsense reasoning, and reading comprehension. Available in base and chat variants with quantized versions, it is distributed under Apache 2.0 license for research and commercial use.
Explore the Future of AI
Your server, your data, under your control
Yi 1.5 6B is a bilingual large language model developed by 01.AI, forming part of the broader Yi model series. Trained on a 3 trillion word multilingual dataset, the model is designed for language understanding, commonsense reasoning, and reading comprehension across both English and Chinese. Built with a Transformer-based architecture, Yi 1.5 6B is open-source and distributed under the Apache 2.0 license, making it accessible for research, academic, and commercial purposes.
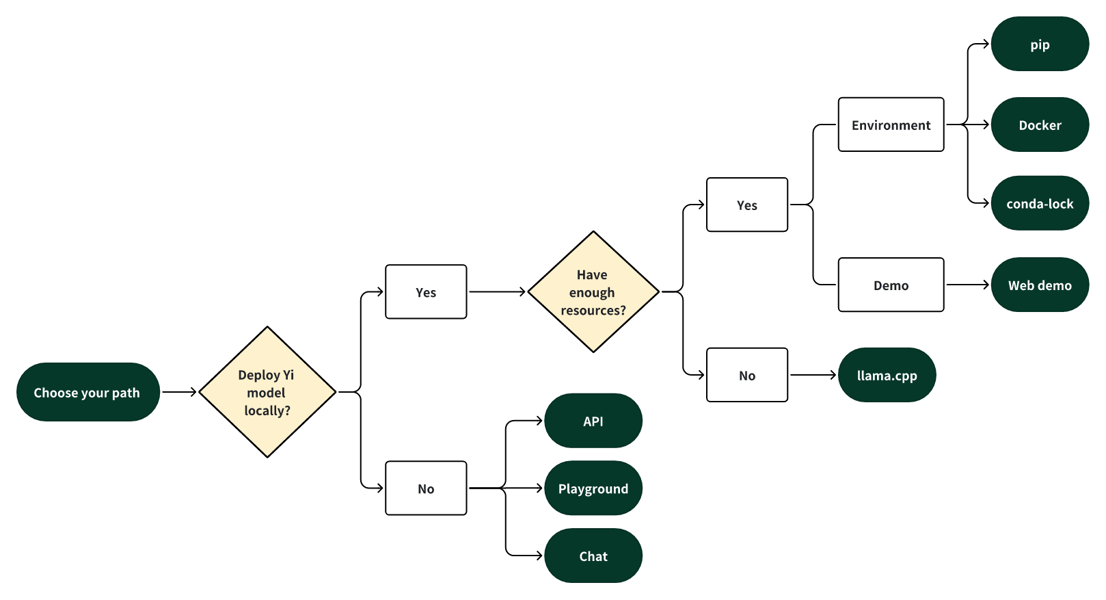
Flowchart depicting the decision process for deploying Yi models locally or via the cloud.
Yi 1.5 6B employs a Transformer framework, similar to that of Llama, but does not utilize Llama's pre-trained weights. Instead, the architecture and training methodology are uniquely developed by 01.AI, leveraging proprietary datasets and robust pipelines. The base model supports a context window of 4,096 tokens, while an extended version, Yi-6B-200K, offers context lengths up to 200,000 tokens, accommodating substantially longer text inputs. The model is bilingual, performing proficiently in both English and Chinese, which is facilitated by its extensive multilingual corpus.
Quantized versions of the model are available in 4-bit and 8-bit formats. The 4-bit variant utilizes AWQ for quantization, and the 8-bit variant uses GPTQ, reducing memory requirements for deployment. Supervised Fine-Tuning (SFT) is used for chat variants, enhancing response diversity and instruction-following capabilities.
Training Data and Methodology
The training corpus for Yi 1.5 6B comprises approximately 3 trillion words, encompassing diverse domains and languages, with data collected up to June 2023. This extensive dataset is central to the model's bilingual proficiency and its handling of a broad spectrum of tasks. For chat models like Yi-6B-Chat, initial training employs SFT, enabling more nuanced dialogue and creative text generation. The proprietary training infrastructure developed by 01.AI emphasizes high-quality data curation and efficient large-scale training workflows.
Performance and Benchmarking
Although benchmark scores for the largest Yi models, such as Yi-34B and Yi-9B, are most frequently highlighted, Yi 1.5 6B demonstrates competitive results within its class. The technical report and comparative analyses on the Hugging Face Open LLM Leaderboard and OpenCompass LLM Leaderboard indicate that Yi models excel in language understanding, commonsense reasoning, and code generation.
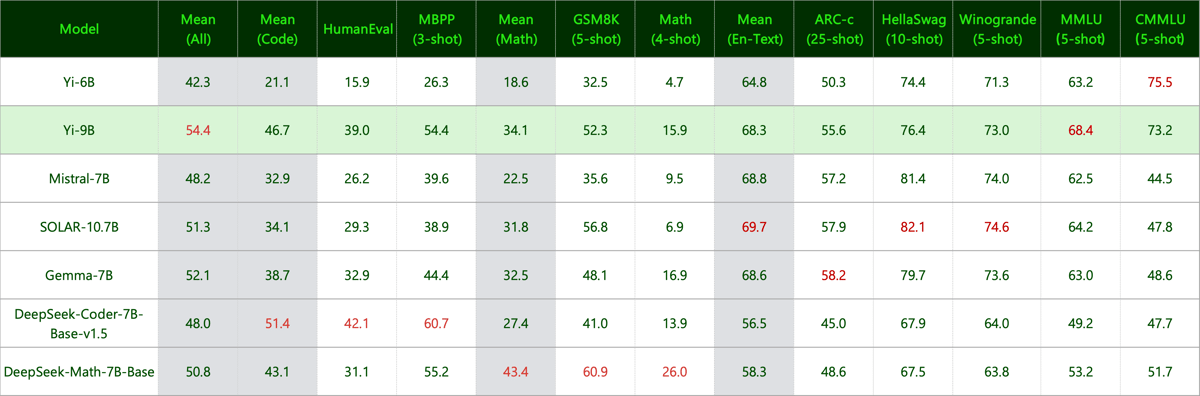
Benchmark chart evaluating the performance of the Yi-6B model compared to several other prominent LLMs in coding, math, and reading tasks.
While the detailed leaderboards emphasize the strengths of larger models like Yi-34B, Yi 1.5 6B and its chat variant deliver competitive results on common sense, language understanding, and reading comprehension tasks (as reported in the Yi Tech Report). The model also provides a strong foundation for instruction-following and creative content generation, with quantized versions supporting deployment in resource-constrained environments.
Applications and Use Cases
Yi 1.5 6B addresses a range of natural language processing tasks, notable for its versatility in both English and Chinese. Key application areas include language understanding, commonsense reasoning, reading comprehension, and creative writing. The chat variants, enabled through SFT, further strengthen the model’s conversational abilities and response diversity. Additional use cases encompass code completion, mathematical reasoning, and as a foundation for downstream fine-tuning in educational, research, and creative domains.
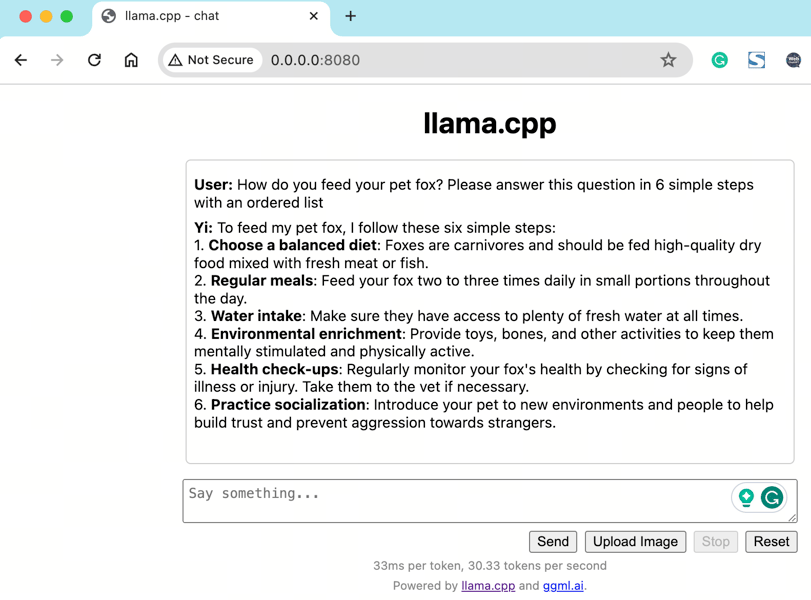
Web demonstration of the Yi chat model responding interactively to a user question, highlighting real-time answer generation in a browser environment.
Yi 1.5 6B offers broad flexibility in deployment. Local options include environments configured via pip, Docker, conda-lock, or lightweight inference using llama.cpp for quantized models. For users seeking cloud interaction, the model can be accessed through APIs, playgrounds, and chat interfaces. Fine-tuning is supported with provided scripts and detailed guidance. Both the base and chat variants can be adapted using custom datasets in jsonl format, with the base model preferable for substantial supervised datasets and the chat model more suitable for dialogue applications or smaller fine-tuning sets.
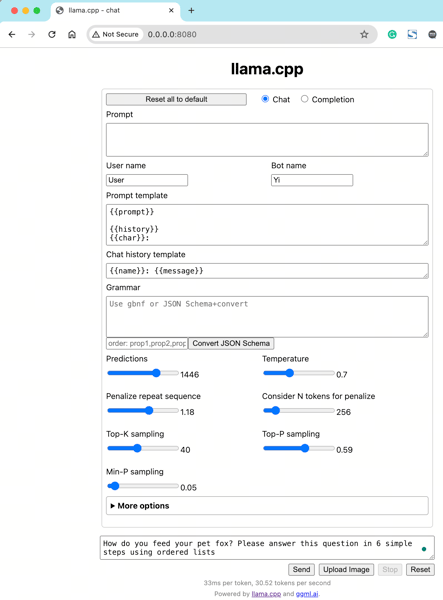
Web-based local interface for configuring and running the Yi model with adjustable prompt templates and sampling parameters.
Model quantization, facilitated by AutoGPTQ and AutoAWQ, allows for reduced-precision versions suitable for memory-limited hardware. This versatility ensures that both researchers and practitioners can deploy and experiment with the model across a wide range of computational resources.
Limitations
Despite its strengths, Yi 1.5 6B shares several limitations common to large language models. The model may occasionally generate factually inaccurate or nonsensical outputs, a phenomenon known as hallucination. Increased response diversity in chat variants can amplify such behavior. Non-determinism in output—meaning that the same prompt may yield different responses when regenerated—can also occur. For intricate tasks requiring long chains of reasoning, small errors may accumulate, resulting in compounding inaccuracies. Users can mitigate these effects by adjusting parameters such as temperature and top-k/top-p sampling during inference.
Model Family and Versions
Yi 1.5 6B is part of a family of models that vary in size and specialization. Larger variants, such as Yi-34B, provide increased capacity, supporting longer context windows and achieving high scores on public leaderboards like Hugging Face Open LLM Leaderboard and C-Eval, particularly in both English and Chinese. Vision-language models, such as Yi-VL-6B and Yi-VL-34B, extend the family's capabilities to multimodal tasks. Within the Yi series, 4-bit and 8-bit quantized variants and long-context models (e.g., the "200K" series) support tailored deployment and application requirements.
Bar chart showing how Yi-9B compares to other models in overall, coding, math, and text understanding benchmarks.
Yi 1.5 6B is distributed under the Apache 2.0 license. This permits unrestricted use, including for personal, academic, and commercial applications. When creating derivative models, users are required to provide clear attribution to 01.AI and specify the particular Yi Series Model employed.