Launch a dedicated cloud GPU server running Laboratory OS to download and run QwQ 32B Preview using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / QwQ 32B Preview
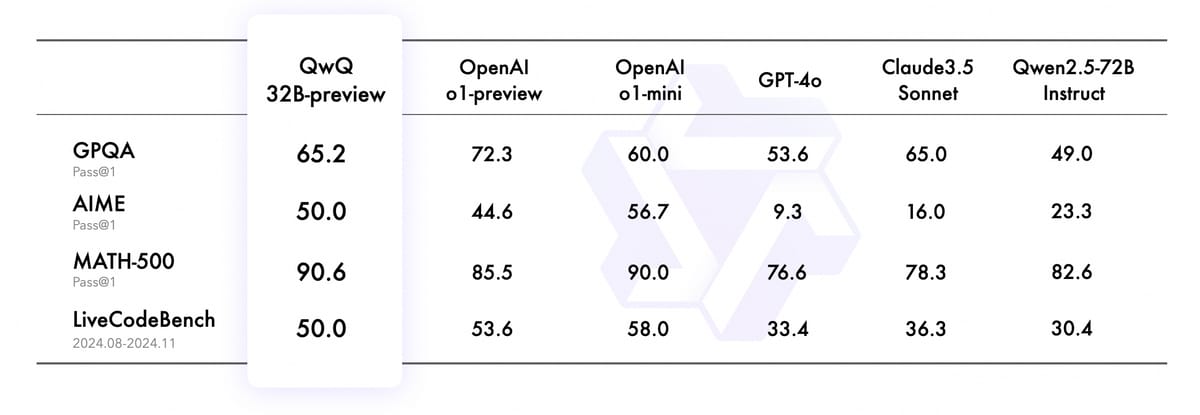
QwQ 32B Preview is an experimental large language model developed by Alibaba Cloud's Qwen Team, built on the Qwen 2 architecture with 32.5 billion parameters. The model specializes in mathematical and coding reasoning tasks, achieving 65.2% on GPQA, 50.0% on AIME, 90.6% on MATH-500, and 50.0% on LiveCodeBench benchmarks through curiosity-driven, reflective analysis approaches.
Explore the Future of AI
Your server, your data, under your control
QwQ 32B Preview is an experimental large language model developed by the Qwen Team, with the goal of advancing reasoning capabilities in artificial intelligence. Pronounced similarly to "quill" (/kwju:/), the QwQ 32B Preview model is designed to approach challenging problems through a process of curiosity-driven, reflective analysis, particularly excelling in mathematical and coding tasks. Its development aims to enhance AI's ability to engage in deep, self-questioning thought, especially on problems at the frontier of knowledge. The primary technical advancements and evaluation results associated with QwQ 32B Preview are publicly documented on the QwQ 32B Preview blog post and the corresponding Qwen2 Technical Report.
Benchmark table comparing QwQ 32B Preview with other large language models on GPQA, AIME, MATH-500, and LiveCodeBench. The table enables direct comparison of model performance in technical and reasoning domains.
QwQ 32B Preview is classified as a causal language model, built on a transformer-based architecture designed for next-token prediction. The construction of the model features notable components widely adopted in natural language processing systems: Rotary Position Embedding (RoPE) for positional encoding, the SwiGLU activation function for increased representation power, RMSNorm for normalization, and attention QKV bias for improved attention mechanisms. The model was developed through an initial pretraining stage followed by post-training to further refine its capabilities, aligning with modern practices in large-scale language model training as described in the Qwen2 Technical Report.
QwQ 32B Preview shares its foundational architecture with Qwen2.5-32B, inheriting design choices and implementation structures suited for high-capacity reasoning and knowledge integration.
Parameters and Specifications
The QwQ 32B Preview model contains approximately 32.5 billion parameters in total, of which 31.0 billion are non-embedding parameters, underscoring its scale for general-purpose reasoning. The transformer backbone comprises 64 layers, with a grouped-query attention (GQA) head structure utilizing 40 query attention heads and 8 key/value heads. Its context window spans a maximum of 32,768 tokens, permitting the consideration of extended textual inputs and outputs within a single sequence. The model is stored and distributed in BF16 tensor formats to optimize memory efficiency. The total model size, as distributed via safetensors, is 32.8 billion parameters, according to the official documentation.
Performance and Benchmarking
QwQ 32B Preview has been evaluated on several specialized benchmarks measuring analytical, mathematical, and programming competencies. According to the QwQ 32B Preview blog, it attains a score of 65.2% on GPQA, a benchmark testing graduate-level scientific problem-solving. On the AIME benchmark, which measures mathematical reasoning across diverse topics such as algebra, counting, and geometry, QwQ 32B Preview scores 50.0%. On MATH-500, a challenging arithmetic and algebraic reasoning test, the model achieves 90.6%. In coding and real-world logic tests as found in LiveCodeBench, QwQ 32B Preview scores 50.0%. These results distinguish the model as proficient across multiple technical reasoning domains.
The benchmark table found in the overview summarizes and directly compares QwQ 32B Preview’s results with other prominent large language models, clarifying its strengths in comparison to contemporary systems. The table includes models such as OpenAI's o1-series, GPT-4o, Claude 3.5 Sonnet, and Qwen2.5-72B Instruct, illustrating the landscape of AI reasoning capabilities.
Limitations
As an early preview release, QwQ 32B Preview exhibits several notable limitations. The model may occasionally mix or switch languages unexpectedly within the same response, an artifact of its multilingual training data and generation process as noted in official Qwen documentation. Users have also observed that, in certain circumstances, the model may fall into recursive, circular reasoning patterns, resulting in unnecessarily lengthy explanations that fail to reach a definitive conclusion. In addition, while optimized for technical reasoning, the model currently shows limited capabilities in broader domains such as nuanced language understanding or strong common-sense reasoning. Safety features are considered preliminary; as such, robust usage guidelines and caution are recommended when deploying the model for general or public-facing tasks, as described in the release notes.
Applications and Research Context
QwQ 32B Preview is intended primarily for research use in domains where deep, step-by-step reasoning is required, such as advanced mathematics, algorithmic programming, and logical problem solving. Its design is informed by ongoing work in reflective reasoning, where the model seeks to analyze a problem, consider alternative approaches, and systematically check its own logic before providing a solution. This capacity is particularly visible when the model tackles tasks involving multi-step computation or equation manipulation, such as decomposing a number into its prime factors or systematically diagnosing errors in mathematical derivations. The Qwen Team situates this work within broader efforts in large language model research, including reflective process supervision and reinforcement learning enhanced by system feedback, as described in the QwQ 32B Preview blog post.
Release Information and Model Family
QwQ 32B Preview was officially announced on November 28, 2024, as documented in the official blog post. It is directly based on the Qwen2.5-32B base model, with further post-training designed to enhance its reasoning performance. Related models in the Qwen family include Qwen2.5-32B-Instruct, a finetuned variant focused on instruction following. The ongoing development of the Qwen model family aims to incrementally improve advanced reasoning, critique, and multi-step logic in language models, supporting an open research ecosystem. For sustained discussions and collaboration, the Qwen community is accessible via a Discord channel and the Qwen organization page on ModelScope.
Further Reading and Resources
For those interested in exploring QwQ 32B Preview and related Qwen models further, the following resources offer comprehensive technical details, usage instructions, and research background:
These resources provide additional context, guides for research applications, ongoing development updates, and opportunities for community interaction.