Launch a dedicated cloud GPU server running Laboratory OS to download and run Llama 4 Scout (17Bx16E) using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / Llama 4 Scout (17Bx16E)
Llama 4 Scout (17Bx16E) is a multimodal large language model developed by Meta using a Mixture-of-Experts transformer architecture with 109 billion total parameters and 17 billion active parameters per token. The model features a 10 million token context window, supports text and image understanding across multiple languages, and was trained on approximately 40 trillion tokens with an August 2024 knowledge cutoff.
Explore the Future of AI
Your server, your data, under your control
Llama 4 Scout (17Bx16E) is a natively multimodal large language model developed by Meta as part of the Llama 4 family. Utilizing a Mixture-of-Experts (MoE) transformer architecture, it supports both multilingual text and image understanding, while featuring a 10 million token context window and advanced visual reasoning performance. Released on April 5, 2025, Llama 4 Scout serves research and commercial applications with a particular focus on scalable, efficient, and flexible multimodal AI.
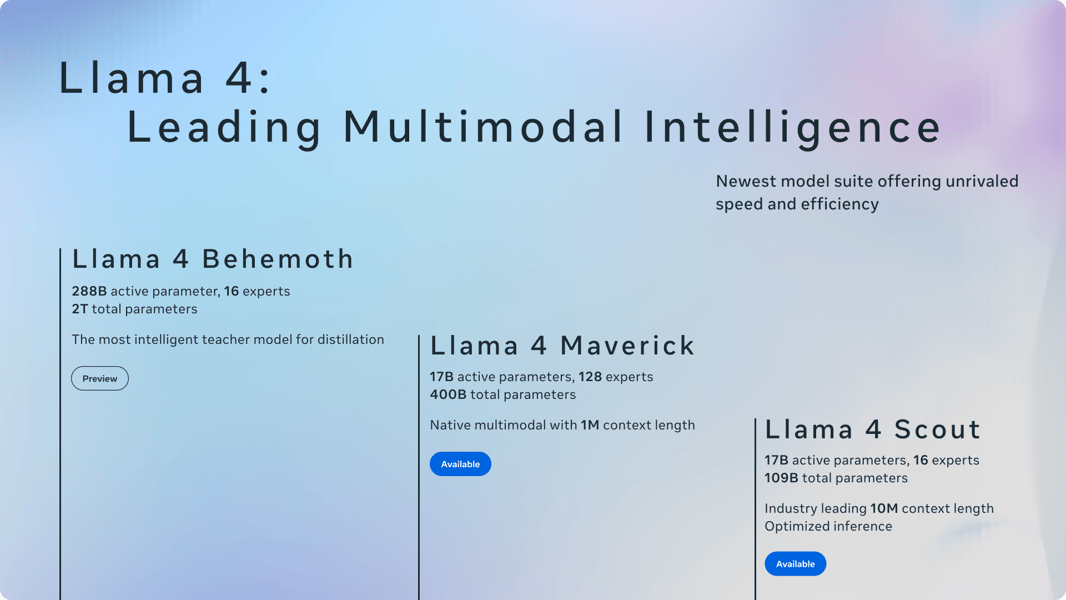
Informational graphic summarizing the Llama 4 model suite, including key specifications such as parameter counts, expert composition, and context lengths.
Llama 4 Scout (17Bx16E) is structured upon a Mixture-of-Experts (MoE) transformer backbone, a first in the Llama family. The model comprises 109 billion total parameters distributed across 16 experts, with 17 billion parameters actively routed per token. The MoE design enables only a subset of parameters—corresponding to top-performing experts—to be activated for each input, optimizing computational efficiency for both training and inference.
A central technical advancement is the iRoPE architecture, which introduces interleaved attention layers without conventional positional embeddings, alongside inference time temperature scaling of attention weights. These features contribute to effective length generalization and underlie the model's 10 million token context window, making it suitable for tasks that involve extensive document, code, or video analysis.
For multimodality, Llama 4 Scout uses "early fusion" to integrate text and visual tokens within a unified model backbone, supporting joint pre-training on massive bilingual and visual datasets. The vision encoder is based on MetaCLIP, trained in conjunction with a frozen Llama language core to enhance visual understanding and image grounding capabilities.
Training Data and Methods
Llama 4 Scout was pre-trained on approximately 40 trillion tokens of multimodal data, including publicly available and licensed datasets, as well as public posts and interactions from Meta platforms. Notably, pre-training included over 200 languages—with over 100 languages represented by at least 1 billion tokens each—greatly expanding multilingual capacity compared to previous generations.
Key training innovations included the MetaP technique for robust hyperparameter selection across varying model scales, extensive utilization of FP8 precision to maximize FLOPs efficiency, and mid-training protocols to incrementally augment long-context capabilities. Post-training involved supervised fine-tuning with challenging datasets, online reinforcement learning, and direct preference optimization (DPO) to improve instruction following and reduce biased refusals. Performance was further refined via knowledge distillation from a larger teacher model, Llama 4 Behemoth.
The data mixture for Llama 4 Scout had an August 2024 knowledge cutoff.
Capabilities and Performance
Llama 4 Scout delivers high performance in text, code, and image understanding, as well as advanced reasoning over long contexts. Its context window of 10 million tokens supports applications involving large-scale document analysis and multi-modal input.
The model natively handles multilingual text, understanding and generating content in languages such as Arabic, English, French, German, Hindi, Indonesian, Italian, Portuguese, Spanish, Tagalog, Thai, and Vietnamese, with primary visual comprehension in English.
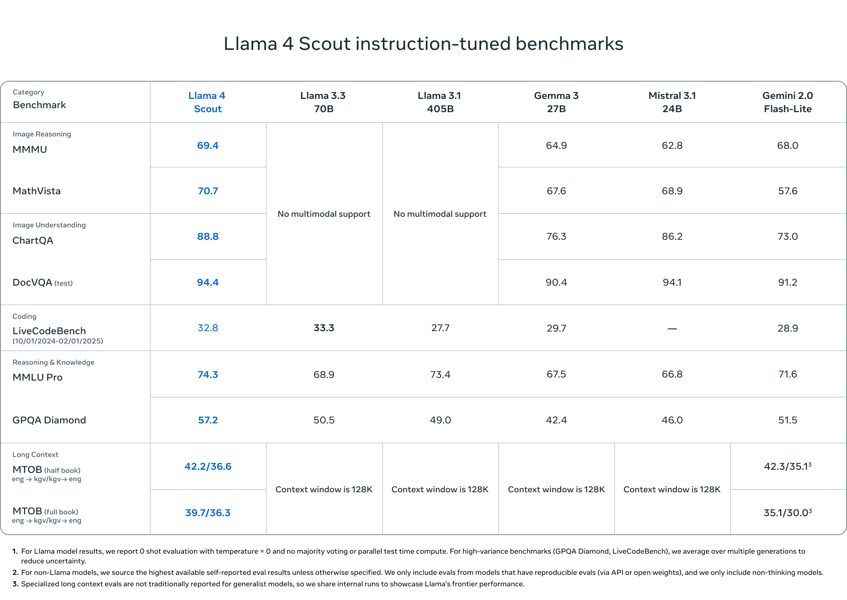
Instruction-tuned Llama 4 Scout attains competitive results on notable academic and industry-standard benchmarks. For example, on reasoning and knowledge tasks, it scored 74.3 on MMLU Pro (0-shot, macro_avg/acc) and 57.2 on GPQA Diamond. It also demonstrates robust performance on image reasoning benchmarks (69.4 on MMMU, 70.7 on MathVista), document understanding (88.8 on ChartQA, 94.4 on DocVQA), and code generation.
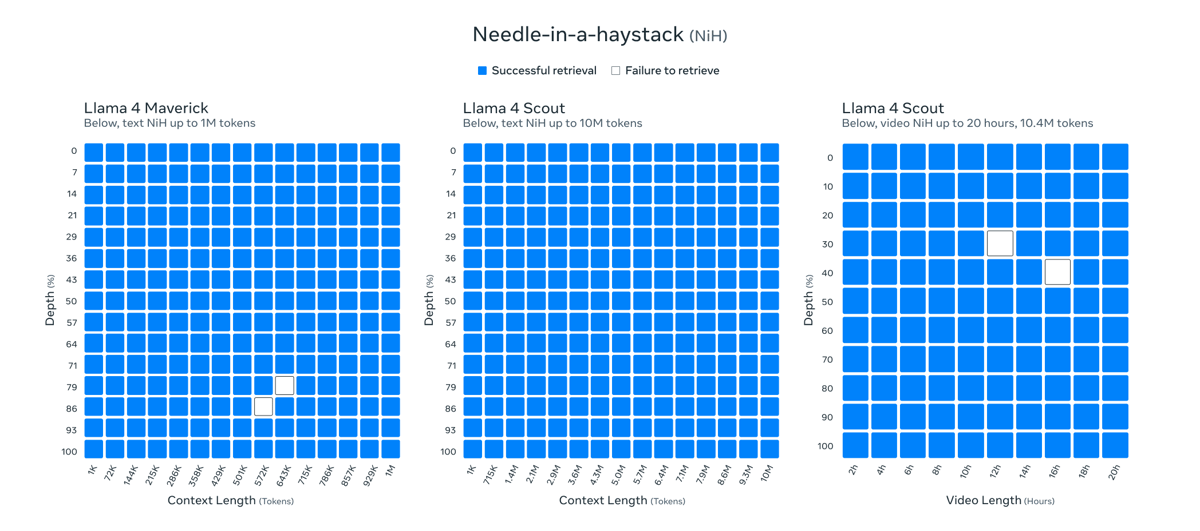
A notable demonstration of the model's long-context retrieval ability is its strong results on the Needle-in-a-Haystack benchmark, achieving robust retrieval across input contexts up to 10 million tokens.
Data visualization of Llama 4 Scout's performance on the Needle-in-a-Haystack benchmark, indicating high retrieval accuracy with extremely long text and video contexts.
In addition to text, Llama 4 Scout is designed for robust image reasoning and understanding. For example, it can analyze and compare illustrated images in context, as demonstrated in the Hugging Face Python code example.
One of two sample images provided in a code example prompting Llama 4 Scout to compare visual details—prompt: 'Can you describe how these two images are similar, and how they differ?'
Llama 4 Scout is suited for a broad spectrum of applications, including research, commercial deployments, and further model development. Its instruction-tuned versions are tailored for assistant-like conversational agents, advanced visual reasoning, and document understanding. The extended context capacity enables applications such as multi-document summarization, large-scale code analysis, and personalized interaction tracing across long history inputs.
Its strong performance on synthetic data generation and distillation also supports downstream model fine-tuning and development. Visual capabilities—including image captioning, visual question answering, and precise image grounding—are central features for tasks in fields such as education, accessibility, digital assistants, and content moderation.
Limitations and Responsible Use
Despite its advanced capabilities, Llama 4 Scout has several limitations. As a static model, it does not update with new information post-training, and its knowledge graph is fixed as of August 2024. Visual understanding is primarily effective in English, and while the model was tested with up to eight input images during post-training, its performance with more images may require additional validation. Meta acknowledges the challenges of bias in large language models; efforts have been made to reduce political or social bias, but residual issues remain.
Developers employing Llama 4 Scout are responsible for conducting their own application-specific safety evaluations, as the foundational evaluation cannot encompass all eventualities. The model may produce inaccurate or inappropriate outputs under some circumstances, and safety best practices are recommended when integrating with sensitive systems.
Licensing and Availability
Llama 4 Scout is distributed under the Llama 4 Community License Agreement, which grants restricted, non-exclusive rights for use, modification, and redistribution, including certain commercial contexts. The agreement includes requirements for attribution, branding, compliance with legal and ethical use policies, and stipulations for redistribution. Organizations exceeding a specified scale, defined by monthly active users, must request additional licensing from Meta.
Technical documentation for model use—including recommended software versions, prompt structure, and input formatting—can be found in the official documentation and model card.