Launch a dedicated cloud GPU server running Laboratory OS to download and run Gemma 3n E4B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Google / Gemma 3n E4B
Gemma 3n E4B is a multimodal generative AI model developed by Google DeepMind with 8 billion raw parameters yielding 4 billion effective parameters. Built on the MatFormer architecture for mobile and edge deployment, it processes text, image, audio, and video inputs to generate text outputs. The model features elastic inference capabilities, allowing extraction of smaller sub-models for faster performance, and supports over 140 languages with demonstrated proficiency in reasoning, coding, and multilingual tasks.
Explore the Future of AI
Your server, your data, under your control
Gemma 3n E4B is a generative artificial intelligence model developed by Google DeepMind for on-device and mobile-first applications, as part of the broader Gemma model family. The model features multimodal capabilities, accepting image, audio, video, and text inputs while producing text outputs. Its architecture is specifically optimized for edge deployment, balancing resource efficiency with performance. This article outlines the architecture, capabilities, performance metrics, training methodology, and typical applications of Gemma 3n E4B within the wider context of generative AI.
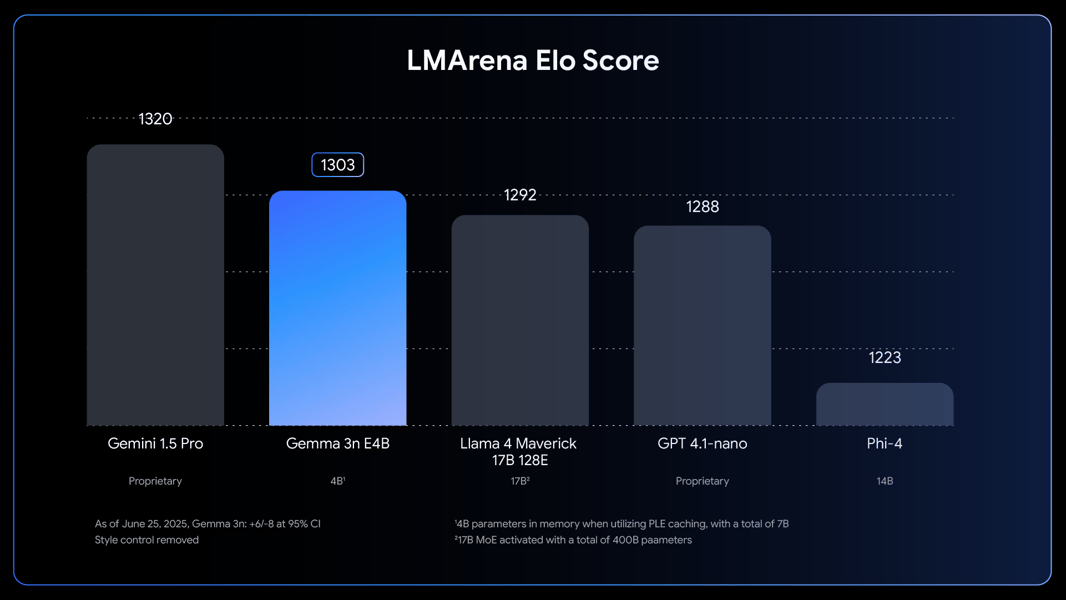
LMArena Elo Score benchmark scores: Gemma 3n E4B is shown alongside other proprietary and open models, highlighting its performance among models under 10 billion parameters.
Gemma 3n E4B is grounded in a mobile-centric architecture built for both efficiency and versatility. Central to the model is the MatFormer (Matryoshka Transformer) design, which enables elastic inference: a large model contains smaller, fully-operational sub-models. In practice, the E4B model (with 8 billion raw parameters, yielding 4 billion effective parameters) incorporates an E2B sub-model. Developers can operate with either the main E4B model or deploy the E2B, benefiting from up to twice the inference speed.
MatFormer architecture diagram: shows how Gemma 3n E4B contains elastic, nested sub-models, allowing custom model sizes and flexible feed-forward network configurations.
The model's architecture supports custom sizing of sub-models via the Mix-n-Match technique, which adjusts the feed-forward network hidden dimensions per layer and can skip entire blocks to optimize for various deployment scenarios. Memory efficiency is further enhanced through Per-Layer Embeddings (PLE), which allow a substantial portion of embeddings to reside in system memory, minimizing the load on the high-speed accelerator memory. This feature is important for running large models on devices with limited computational resources.
Per-Layer Embeddings (PLE) compare standard and optimized loading requirements, illustrating reduced on-device memory usage for large model deployments.
Efficiency for streaming and real-time applications is improved by KV cache sharing, directly sharing keys and values of intermediary layers with top layers, leading to faster initial response times.
Multimodal Capabilities
Gemma 3n E4B is designed for multimodal interactions, processing not only text but also images, audio, and video inputs. For visual tasks, it integrates the MobileNet-V5-300M vision encoder, characterized by its ability to process images at multiple input resolutions—including 256x256, 512x512, and 768x768 pixels. Co-trained on multimodal data, MobileNet-V5-300M enables video analysis and visual understanding on edge devices, achieving up to 60 frames per second on supported mobile hardware.
For audio understanding, Gemma 3n E4B adopts an encoder based on the Universal Speech Model (USM), allowing the model to process speech by tokenizing audio in 160-millisecond segments. This encoder supports both automatic speech recognition (ASR) and speech translation (AST), with demonstrated effectiveness across numerous languages such as English, Spanish, French, Italian, and Portuguese. The architecture's modularity also enables the processing of extended audio sequences with appropriate latency controls.
Performance and Benchmarks
Gemma 3n E4B has been evaluated across language understanding, reasoning, multilingual capabilities, and code generation. On the LMArena benchmark, it achieved a score above 1300 Elo points (LMArena benchmark).
The model's performance on various established benchmarks includes:
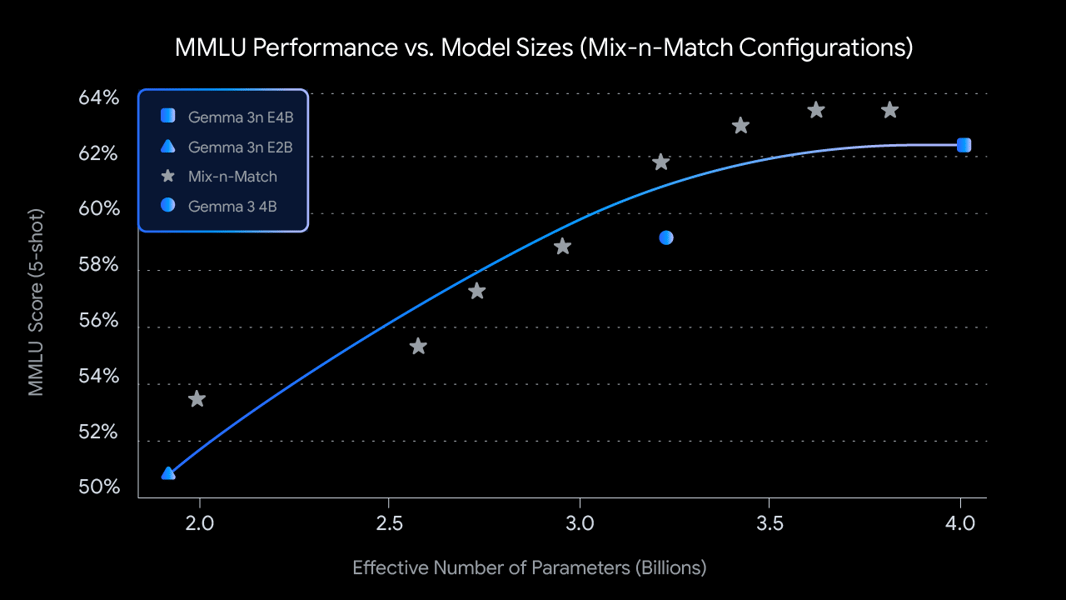
On MMLU (Massive Multitask Language Understanding), E4B achieves an accuracy of 64.9% in 0-shot settings, with performance scaling across model sizes and Mix-n-Match configurations. The Mix-n-Match technique allows for intermediate models that maintain MMLU scores relative to their resource footprint.
MMLU benchmark: Performance increases with effective parameter size, with Mix-n-Match configurations bridging the gap between E2B and E4B.
Reasoning and factuality tasks (including HellaSwag, BoolQ, PIQA, and TriviaQA) demonstrate the model's capabilities for structured thought and factual knowledge representation, while coding and STEM benchmarks show the model's skill in code generation and mathematical reasoning.
Gemma 3n E4B also supports over 140 languages for text and 35 languages for multimodal understanding, indicating broad multilingual capabilities.
Training Data, Methods, and Responsible AI
The training regimen for Gemma 3n E4B encompassed approximately 11 trillion tokens with a knowledge cutoff in June 2024. The data corpus spanned diverse domains, including multilingual web documents, code, mathematics, images, and audio, to foster proficiency in a range of tasks.
Advanced filtering pipelines were employed, including content safety protocols to exclude sensitive data and high-risk content, aligned with Google's AI responsibility policies. Model training utilized distributed computing infrastructure, leveraging JAX and ML Pathways for large-scale training efficiency.
These approaches are supported by research into responsible generative AI, addressing risks associated with bias, privacy, and factuality. Evaluations indicate that while the model achieves robust multilinguality and code proficiency, its safety assessments have prioritized English-language prompts, with ongoing efforts to extend these to global languages.
Applications, Use Cases, and Limitations
The design of Gemma 3n E4B centers on on-device deployment, supporting privacy-critical, offline, or low-latency applications in content creation, communication, research, and language learning. Typical applications include conversational AI, summarization, translation, code generation, multimodal information extraction, and educational tools (official developer guide).
Despite its broad applicability, Gemma 3n E4B has limitations inherent to large language models. The quality and scope of its training data influence its capabilities; potential biases, context comprehension challenges, and a lack of common-sense reasoning may affect some outputs. Moreover, while the model performs well when given clear and structured prompts, nuanced or ambiguous queries may yield less reliable results. Factual outputs should be externally verified, as the model does not act as a real-time knowledge base.
Model Family, Deployment, and Accessibility
Gemma 3n models are released in two effective parameter sizes: E2B (2 billion effective, 5 billion raw parameters) and E4B (4 billion effective, 8 billion raw parameters), enabled by the MatFormer framework. The E2B version is extractable as a standalone sub-model, offering improved efficiency at the cost of output quality. Mix-n-Match further allows for tailored models between E2B and E4B, which can be retrieved using MatFormer Lab.
The model and its variants are licensed under terms outlined by Google; users must review and agree to Gemma's usage license before accessing model checkpoints.